






1.背景介绍
在Kudu之前,大数据主要以两种方式存储;
(1) 静态数据:
以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是无法进行随机的读写。
(2)动态数据:
以HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。局限性是批量读取吞吐量远不如HDFS,不适用于批量数据分析的场景。
Kudu的定位是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
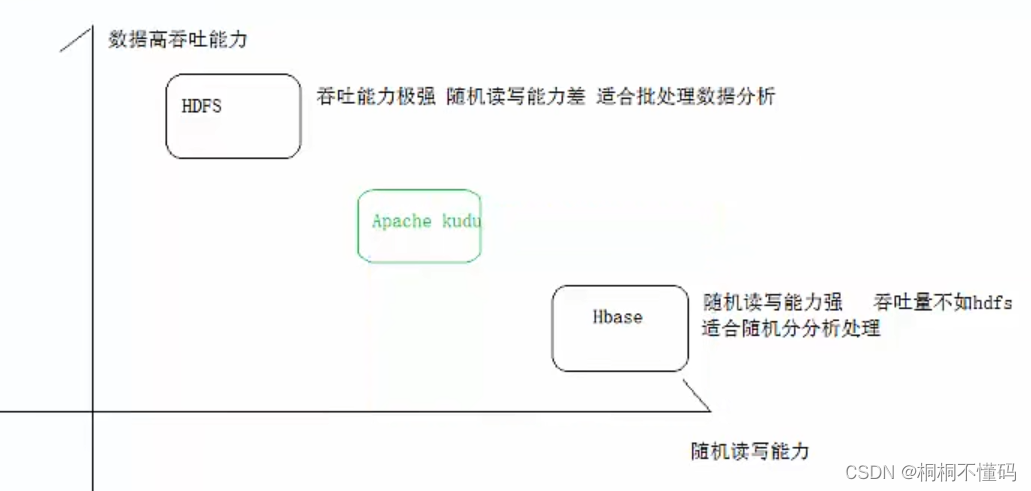
2.kudu是什么
Apache Kudu 是由 Cloudera 开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。它是一个融合HDFS和HBase的功能的新组件,具备介于两者之间的新存储组件。
Kudu支持水平扩展,并且与Cloudera Impala 和 Apache Spark 等当前流行的大数据查询和分析工具结合紧密。
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









