









最近转行到出版社行业,由于互联网的冲击,传统出版行业都转行做移动电子书。纵观现在的电子书标准,可以说是五花八门,每个运营商差不多都有自己的一套标准。国际现在通用的标准是epub3.0。但是身在中国,躲不过去要和三大运营商合作,三大运营商手中的,ocf标准我在网上找了半天,也木有找到。后来直接将ocf文件解压开,分析文件结构以及配置才发现了规律。此规律和epub标准差别不是很大。但是具体的细节上不一样。现在直接上图,
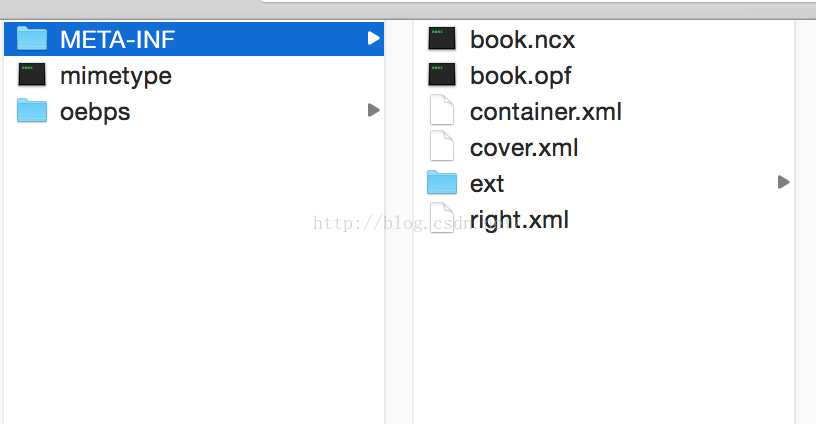
上图是ocf解压后他文件目录结构。我们现在主要关注book.ncx ,此文件记录了ocf电子书的目录结构。
book.ncx内容样例如下:
<?xml version="1.0" encoding="UTF-8"?>
<ncx version="2005-1" xmlns="http://www.daisy.org/z3986/2005/ncx/">
<head>
<meta name="dtb:uid" content=" "/>
<meta name="dtb:depth" content="-1"/>
<meta name="dtb:totalPageCount" content="0"/>
<meta name="dtb:maxPageNumber" content="0"/>
</head>
<docTitle>
<text>很老很灵的偏方验方名方</text>
</docTitle>
<docAuthor>
<text>张银柱</text>
</docAuthor>
<rootpath>/oebps/</rootpath>
<navMap>
<navPoint id="1">
<navLabel>
<text>很老很灵的偏方验方名方</text>
</navLabel>
<navPoint id="2" playOrder="0" mcpcontentid="">
<navLabel>
<text>五官科疾病</text>
</navLabel>
<content src="/chapter01/chapter01.html"/>
</navPoint>
<navPoint id="3" playOrder="1" mcpcontentid="">
<navLabel>
<text>内科疾病</text>
</navLabel>
<content src="/chapter02/chapter02.html"/>
</navPoint>
<navPoint id="4" playOrder="2" mcpcontentid="">
<navLabel>
<text>外科疾病</text>
</navLabel>
<content src="/chapter03/chapter03.html"/>
</navPoint>
<navPoint id="5" playOrder="3" mcpcontentid="">
<navLabel>
<text>皮肤科疾病</text>
</navLabel>
<content src="/chapter04/chapter04.html"/>
</navPoint>
</navPoint>
</navMap>
</ncx>
记录了图书 作者 ,图书标题 ,以及目录 ,目录的顺序 等。其中 navPoint 标签可以多层嵌套,要注意这点。由于现在是电子版的书籍,感觉这个标准制定的很鸡肋,因为在移动端读取目录的时候,一般只读取最后连接页面的目录。
想要从ocf中抽取图书目录,就需要在这个 ncx文件上做手脚了。 OCF说白了,就是定义了固定格式的压缩包。 所以思路是 Java自带的工具类 Java.utils.zip下面的几个类,获取
META-INF目录下的book.ncx剩下的就是解析 xml文件了,我解析xml文件是用的dom4j。
写好的工具类已经上传到csdn了,审核通过后,我会贴上资源的下载地址。
资源的下载地址:
http://download.csdn.net/detail/x734400146/9419505














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









