






前言
现有多数超分辨率方法为整数倍数放大,而真实场景需要无极缩放,本文从任意放大倍数的超分辨率方法进行探究。
翻译或解释有误,敬请谅解指出。
一、Meta-SR
1.1 Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
paper
code
给定从相应的原始HR图像
I
H
R
I^{HR}
IHR中缩小的LR图像
I
L
R
I^{LR}
ILR,SISR的任务是生成一个HR图像
I
S
R
I^{SR}
ISR,其ground-truth是
I
H
R
I^{HR}
IHR。 文中选择RDN作为特征学习模块。

设
F
L
R
F^{LR}
FLR表示特征学习模块提取的特征,比例因子为
r
r
r。对于SR图像上的每个像素
(
i
,
j
)
(i,j)
(i,j),可认为其由LR图像上像素
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′)的特征和相应滤波器的权重决定,则上采样模块(upscale moudle)能被认为是
F
L
R
F^{LR}
FLR到
I
S
R
I^{SR}
ISR的映射函数
Φ
Φ
Φ。首先,上采样模块映射像素
(
i
,
j
)
(i,j)
(i,j)到像素
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′),然后,上采样模块需要特定的滤波器映射像素
W
(
i
′
,
j
′
)
W(i^{'},j^{'})
W(i′,j′)的特征,以生成像素
I
S
R
(
i
,
j
)
I^{SR}(i,j)
ISR(i,j)的值。
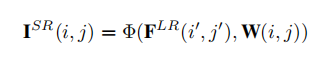
因为SR图像上的每个像素对应一个滤波器。 对于不同的尺度因子,滤波器的数目和滤波器的权重都与其他尺度因子不同。 为了求解单个模型的任意尺度因子的超分辨率,提出了基于尺度因子和坐标信息的元上采样模块(Meta Upscale Module)来动态预测权重
W
(
i
,
j
)
W(i,j)
W(i,j)。
对于元尺度模块,有三个重要的功能: 即位置投影(Location Projection)、权重预测(Weight Prediction)和特征映射(Feature Mapping)。位置投影将像素投影到LR图像上, 权重预测模块预测SR图像上每个像素的滤波器权重,特征映射函数将具有预测权重的LR图像上的特征映射回SR图像来计算像素的值。

1.2 Location Projection
对于SR图像上的每个像素
(
i
,
j
)
(i,j)
(i,j),位置投影是在LR图像上找到
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′),认为像素
(
i
,
j
)
(i,j)
(i,j)的值是由LR图像上
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′)的特征决定的。位置投影可以看作是一种可变的分数步长机制,它可以任意比例因子上采样特征图。如果比例因子
r
r
r为2,则每个像素
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′)确定两点。 然而,如果尺度因子是非整数,如
r
=
1.5
r=1.5
r=1.5,则一些像素决定两个像素,一些像素决定一个像素。 对于SR图像上的每个像素
(
i
,
j
)
(i,j)
(i,j),可以在LR图像上找到一个唯一的像素
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′),并认为这两个像素是最相关的。
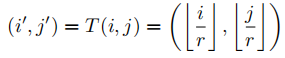
1.3 Weight Prediction
对于经典的上采样模块,预先定义了每个比例因子的滤波器数量,并从训练数据集学习W,与之不同的 Meta Upsacle module 使用网络来预测滤波器的权重。其中
W
(
i
,
j
)
W(i,j)
W(i,j)是SR图像上像素
(
i
,
j
)
(i,j)
(i,j)的滤波器权重,
V
i
j
V_{ij}
Vij是与
i
,
j
i,j
i,j相关的向量。
ϕ
(
.
)
\phi(.)
ϕ(.) 是权重预测网络,并以
V
i
j
V_{ij}
Vij作为输入。
θ
θ
θ是权重预测网络的参数。
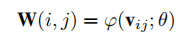
至于像素
(
i
,
j
)
(i,j)
(i,j)的输入
ϕ
(
.
)
\phi(.)
ϕ(.) ,适当的选择是相对于
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′)的相对偏移,
V
i
j
V_{ij}
Vij可以表示为:
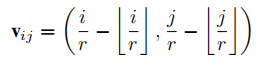
为了将多比例因子训练在一起,最好将比例因子添加到
V
i
j
V_{ij}
Vij中,以区分不同比例因子的权重。 例如,如果想用比例因子2和4对图像进行上采样,分别表示为
I
2
S
R
I_2^{SR}
I2SR和
I
4
S
R
I_4^{SR}
I4SR。 在
I
2
S
R
I_2^{SR}
I2SR上的像素
(
i
,
j
)
(i,j)
(i,j)将具有与
I
4
S
R
I_4^{SR}
I4SR上的像素
(
2
i
,
2
j
)
(2i,2j)
(2i,2j)相同的滤波器权重和相同的投影坐标。这意味着
I
2
S
R
I_2^{SR}
I2SR是
I
4
S
R
I_4^{SR}
I4SR的子图, 限制了性能。 因此,将
V
i
j
V_{ij}
Vij重新定义为:
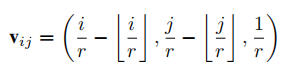
1.4 Feature Mapping
之前从LR图像上的像素
(
i
′
,
j
′
)
(i^{'},j^{'})
(i′,j′)提取了特征FLR, 并利用权重预测网络对滤波器的权重进行预测,最后需要做的是将特征映射到SR图像上像素的值。文中选择矩阵乘积作为特征映射函数,即之前的Φ函数。
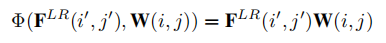
1.5 Algorithm

1.6 Architecture Details
特征学习模块RDN有3个卷积层和16个剩余密集块(RDB),每个RDB有8个卷积层, 密集块的增长率为64, 并且提取的特征图有64个通道。
Meta-UpScale Module由几个完全连接的层和几个激活层组成。 每个输入将输出一组具有形状(
i
n
C
,
o
u
t
C
,
k
,
k
inC,outC,k,k
inC,outC,k,k)的权重。
i
n
C
inC
inC是提取特征映射的通道数,文中
i
n
C
=
64
inC=64
inC=64。
o
u
t
C
outC
outC是预测HR图像的通道数, 通常
o
u
t
C
=
3
outC=3
outC=3表示彩色图像,
o
u
t
C
=
1
outC=1
outC=1表示灰度图像。
k
k
k表示卷积核的大小。
Meta-UpScale Module的参数包括隐藏神经元的数目、完全连接层的数目、激活函数的选择和卷积层的核大小。 由于与输入大小(3)相比,输出大小(
k
∗
k
∗
i
n
C
∗
o
u
t
C
k * k * inC * outC
k∗k∗inC∗outC)非常大,将隐藏神经元的数目设置为256。 继续增加隐藏神经元的数量没有改善。 且激活函数为ReLU。 实验发现完全连接层的最佳数量是2,达到速度和性能的平衡。 至于卷积核大小,3×3是最好的大小,在大特征映射上进行5×5卷积操作更耗时。
class Pos2Weight(nn.Module):
def __init__(self,inC=64, kernel_size=3, outC=3):
super(Pos2Weight,self).__init__()
self.inC = inC
self.kernel_size=kernel_size
self.outC = outC
self.meta_block=nn.Sequential(
nn.Linear(3,256),
nn.ReLU(inplace=True),
nn.Linear(256,self.kernel_size*self.kernel_size*self.inC*self.outC)
)
def forward(self,x):
output = self.meta_block(x)
return output
二、LIIF-SR
Meta-SR可以在训练尺度上执行任意上采样,但在超出训练尺度的大尺度的图片上性能有限。
2.1 Learning Continuous Image Representation with Local Implicit Image Function
通过学习图像的连续表示,使用局部隐式图像函数(Local Implicit Image Function,LIIF)将图像坐标和坐标周围的2D深度特征作为输入,预测输出给定坐标下的RGB值。经自监督超分辨率任务来训练编码器和LIIF表示来生成像素图像的连续表示,可以做到任意倍数的分辨率,甚至可以推算不在训练任务中的30倍以上超分。
paper
code

2.2 Local Implicit Image Function(LIIF)
在LIIF表示中,每个连续图像
I
(
i
)
I^{(i)}
I(i)由二维特征映射
M
(
i
)
∈
R
H
×
W
×
D
M^{(i)}∈\R^{H \times W \times D}
M(i)∈RH×W×D表示。 一个神经隐式函数
f
θ
f_θ
fθ(以
θ
θ
θ为其参数)被所有图像共享,它被参数化为
M
L
P
MLP
MLP(多层感知机)并采取形式
s
=
f
(
z
,
x
)
s = f(z,x)
s=f(z,x)(简便省略
θ
θ
θ),其中
z
z
z是一个向量,
x
∈
X
x \in X
x∈X是连续图像域中的二维坐标,
s
∈
S
s \in S
s∈S是预测信号(即RGB值)。
对于定义的
f
f
f,每个向量
z
z
z都可以看作是表示函数
f
(
z
,
⋅
)
:
X
→
S
f(z,·):X→S
f(z,⋅):X→S。
f
(
z
,
⋅
)
f(z,·)
f(z,⋅)可以看作是一个连续的图像,即映射坐标到RGB值的函数。 假设
M
(
i
)
M^{(i)}
M(i)的
H
×
W
H \times W
H×W特征向量(称为潜在码latent codes)均匀分布在
I
(
i
)
I^{(i)}
I(i)的连续图像域的二维空间中,然后为它们中的每一个分配一个2D坐标。
对于图像
I
(
i
)
I^{(i)}
I(i),坐标
x
q
x_q
xq处的RGB值定义为
I
(
i
)
(
x
q
)
=
f
(
z
∗
,
x
q
−
v
∗
)
I^{(i)}(x_q) = f(z^*,x_q-v^*)
I(i)(xq)=f(z∗,xq−v∗),其中
z
∗
z^∗
z∗是
M
(
i
)
M^{(i)}
M(i)中与
x
q
x_q
xq最近的(欧几里德距离)潜码,
v
∗
v^∗
v∗是图像域中潜码
z
∗
z^∗
z∗的坐标。 下图中,
z
11
∗
z^∗_{11}
z11∗是当前定义中
x
q
x_q
xq的
z
∗
z^∗
z∗,而
v
∗
v^∗
v∗被定义为
z
11
∗
z^∗_{11}
z11∗的坐标。
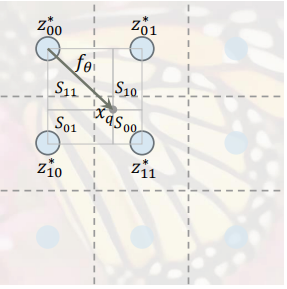
在所有图像共享的隐式函数
f
f
f下,连续图像由二维特征映射
M
(
i
)
∈
R
H
×
W
×
D
M^{(i)} \in \R^{H \times W \times D}
M(i)∈RH×W×D表示,该特征映射被看作是在2D域中均匀分布的
H
×
W
H×W
H×W潜在码(
D
D
D算一维,
H
×
W
H \times W
H×W算一维)。 在
M
(
i
)
M^{(i)}
M(i)中的每个潜在码
z
z
z表示连续图像的局部部分,它负责预测与它最近的坐标集的信号。
2.3 Learning Continuous Image Representation

总体思想是训练编码器
E
ϕ
E_ϕ
Eϕ(以
ϕ
ϕ
ϕ为其参数),将基于像素的图像映射到二维特征映射作为其LIIF表示,其中共同学习神经隐式函数
f
θ
f_θ
fθ。 希望生成的连续LIIF表示不仅能够重建其输入图像,而且更重要的是,即使以更高的分辨率呈现,它也应该保持高保真度。 因此,我们提出在具有超分辨率的自监督任务中学习编码器和隐式函数。
以单个训练图像为例,对于训练图像,输入是通过随机尺度下采样训练图像来生成的。 ground-truth是通过将训练图像表示为像素样本
x
h
r
x_{hr}
xhr,
s
h
r
s_{hr}
shr,其中
x
h
r
x_{hr}
xhr是中心图像域中像素的坐标,
s
h
r
s_{hr}
shr是像素的相应RGB值。
编码器
E
ϕ
E_ϕ
Eϕ将输入图像映射到2D特征图作为其LIIF表示。 然后使用坐标
x
h
r
x_{hr}
xhr对LIIF表示进行查询,其中
f
θ
f_θ
fθ基于LIIF表示预测这些坐标中的每个坐标的RGB值。
2.4 Architecture Details
以下为 EDSR-baseline-LIIF的网络结构。
编码器
E
ϕ
E_ϕ
Eϕ:头部将输入三通道图像映射到64通道特征图,主体使用16个残差块对64通道特征图学习。
(encoder): EDSR(
(sub_mean): MeanShift(3, 3, kernel_size=(1, 1), stride=(1, 1))
(add_mean): MeanShift(3, 3, kernel_size=(1, 1), stride=(1, 1))
(head): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(body): Sequential(
(0): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(1): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(2): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(3): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(4): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(5): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(6): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(7): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(8): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(9): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(10): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(11): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(12): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(13): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(14): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(15): ResBlock(
(body): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(16): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
神经隐式函数 f θ f_θ fθ:5层的MLP,输入维数 580 = 64 ∗ 3 ∗ 3 + 2 + 2 580=64*3*3+2+2 580=64∗3∗3+2+2,输出维数3(RGB)。
(imnet): MLP(
(layers): Sequential(
(0): Linear(in_features=580, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=256, bias=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=256, bias=True)
(7): ReLU()
(8): Linear(in_features=256, out_features=3, bias=True)
)
)
前向运算主要过程:self.feat为之前编码器 E ϕ E_ϕ Eϕ提取的特征,coord为坐标点,cell为单元编码。
def query_rgb(self, coord, cell=None):
feat = self.feat
if self.imnet is None:
ret = F.grid_sample(feat, coord.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :] \
.permute(0, 2, 1)
return ret
if self.feat_unfold:
feat = F.unfold(feat, 3, padding=1).view(
feat.shape[0], feat.shape[1] * 9, feat.shape[2], feat.shape[3])
if self.local_ensemble:
vx_lst = [-1, 1]
vy_lst = [-1, 1]
eps_shift = 1e-6
else:
vx_lst, vy_lst, eps_shift = [0], [0], 0
# field radius (global: [-1, 1])
rx = 2 / feat.shape[-2] / 2
ry = 2 / feat.shape[-1] / 2
feat_coord = make_coord(feat.shape[-2:], flatten=False).cuda() \
.permute(2, 0, 1) \
.unsqueeze(0).expand(feat.shape[0], 2, *feat.shape[-2:])
preds = []
areas = []
for vx in vx_lst:
for vy in vy_lst:
coord_ = coord.clone()
coord_[:, :, 0] += vx * rx + eps_shift
coord_[:, :, 1] += vy * ry + eps_shift
coord_.clamp_(-1 + 1e-6, 1 - 1e-6)
q_feat = F.grid_sample(
feat, coord_.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :] \
.permute(0, 2, 1)
q_coord = F.grid_sample(
feat_coord, coord_.flip(-1).unsqueeze(1),
mode='nearest', align_corners=False)[:, :, 0, :] \
.permute(0, 2, 1)
rel_coord = coord - q_coord
rel_coord[:, :, 0] *= feat.shape[-2]
rel_coord[:, :, 1] *= feat.shape[-1]
inp = torch.cat([q_feat, rel_coord], dim=-1)
if self.cell_decode:
rel_cell = cell.clone()
rel_cell[:, :, 0] *= feat.shape[-2]
rel_cell[:, :, 1] *= feat.shape[-1]
inp = torch.cat([inp, rel_cell], dim=-1)
bs, q = coord.shape[:2]
pred = self.imnet(inp.view(bs * q, -1)).view(bs, q, -1)
preds.append(pred)
area = torch.abs(rel_coord[:, :, 0] * rel_coord[:, :, 1])
areas.append(area + 1e-9)
tot_area = torch.stack(areas).sum(dim=0)
if self.local_ensemble:
t = areas[0]; areas[0] = areas[3]; areas[3] = t
t = areas[1]; areas[1] = areas[2]; areas[2] = t
ret = 0
for pred, area in zip(preds, areas):
ret = ret + pred * (area / tot_area).unsqueeze(-1)
return ret















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









