







- CVPR2021
- https://github.com/yinboc/liif
- 问题引入
- 图像普遍都是使用像素来表示的,而现实世界是连续的,所以本文借鉴3D中neural implicit representation的思想,以连续的方式表示图像;
- 模型输入坐标值和坐标附近的特征,得到该坐标处的像素值,而坐标是连续的,从而得以连续的表示图像;
- 因为连续的特性,使得可以以任意scale来完成超分辨率的任务;
- 方法
- 本文中一张连续图片
I
(
i
)
I^{(i)}
I(i)由2d的feature map
M
(
i
)
∈
R
H
×
W
×
D
M^{(i)}\in \mathbb{R}^{H\times W\times D}
M(i)∈RH×W×D和decoding function
f
θ
f_\theta
fθ组成,其中
s
=
f
θ
(
z
,
x
)
s = f_\theta(z,x)
s=fθ(z,x),
s
s
s表示像素值,
z
z
z表示某坐标的feature vector,
x
x
x表示坐标,对于某点的连续图像上指定坐标点
x
q
x_q
xq的像素值的求取分两种情况:
– 没有local ensemble, I ( i ) ( x q ) = f θ ( z ∗ , x q − v ∗ ) I^{(i)}(x_q) = f_\theta(z^*,x_q-v^*) I(i)(xq)=fθ(z∗,xq−v∗),其中 z ∗ z^* z∗表示离所求点最近的feature vector, v ∗ v^* v∗是对应的坐标;
– 有local ensemble,主要是上面那种求解方法会导致对于求解的点对应的latent code vector在中间线突变的情况,所以采取的类似于差值的操作: I ( i ) ( x q ) = ∑ t ∈ { 00 , 01 , 10 , 11 } S t S ⋅ f θ ( z ∗ , x q − v ∗ ) I^{(i)}(x_q) = \sum_{t\in\{00,01,10,11\}}\frac{S_t}{S}\cdot f_\theta(z^*,x_q-v^*) I(i)(xq)=∑t∈{00,01,10,11}SSt⋅fθ(z∗,xq−v∗),也就是距离所求点的左上、左下、右上、右下四个点求像素值然后做加权和,其权值是所求点和当前点所围矩形的对角矩形的面积,权值进行了归一化,这样就是距离所求点越近的点的权重越大;下面两点式对模型的两点补充; - 为了丰富latent code包含的信息,进行了feature unfolding的操作,使得 M ( i ) → M ^ ( i ) M^{(i)}\rightarrow \widehat{M}^{(i)} M(i)→M (i),现在的latent code是原来latent code 3 × 3 3\times 3 3×3范围内的latent code的拼接: M ^ j k ( i ) = C o n c a t ( { M j + l , k + m ( i ) } l , m ∈ { − 1 , 0 , 1 } ) \widehat{M}^{(i)}_{jk} = Concat(\{{M}^{(i)}_{j+l,k+m}\}_{l,m\in \{-1,0,1\}}) M jk(i)=Concat({Mj+l,k+m(i)}l,m∈{−1,0,1});边缘补0;
- 在预测某个坐标点的像素值的时候,只给定坐标值,此时忽略了像素的尺寸,所以还加上cell decoding操作,将原来的decoding操作变为 s = f c e l l ( z , [ x , c ] ) s = f_{cell}(z,[x,c]) s=fcell(z,[x,c])
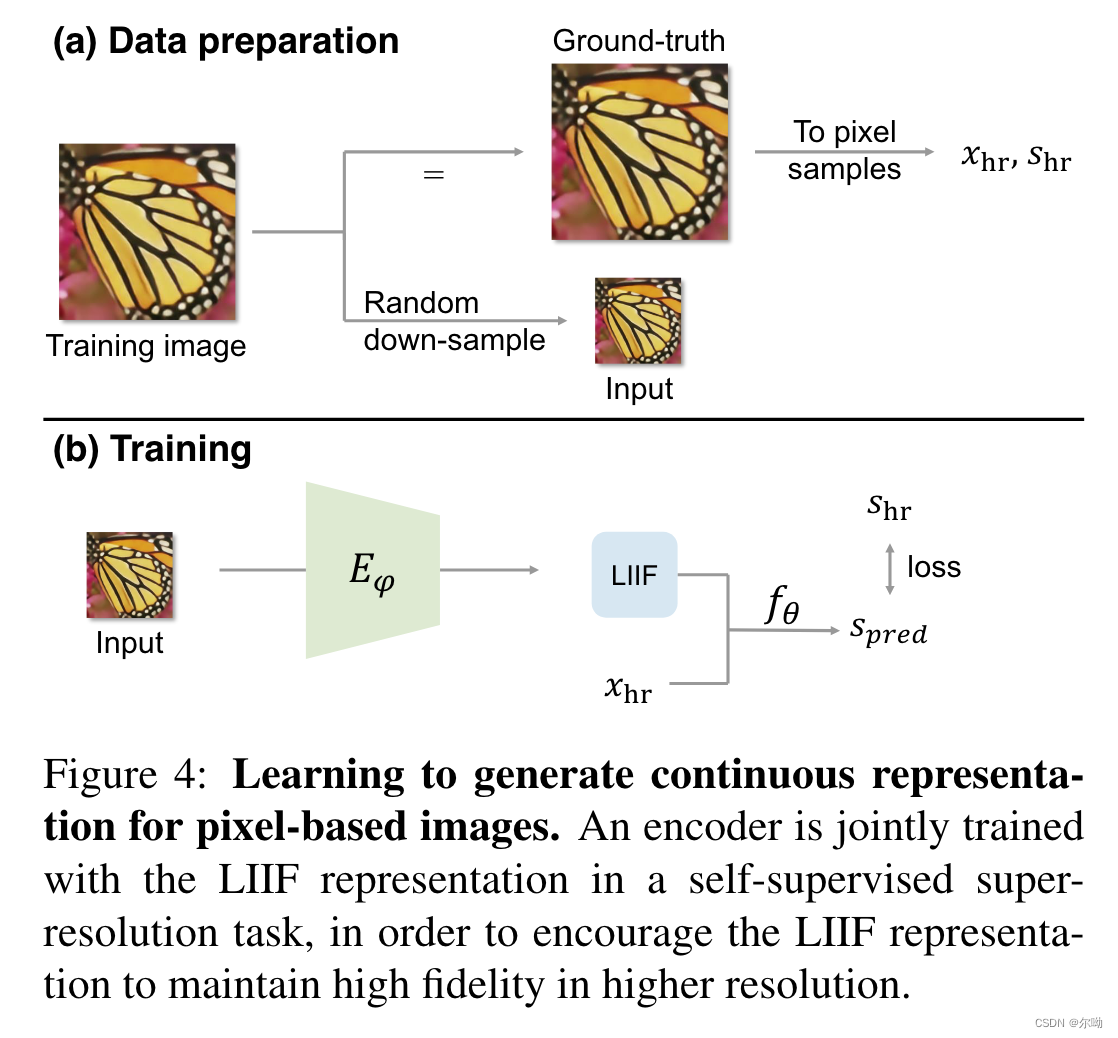
- 模型的训练:首先有一张高分的图片,作为gt,得到的有
x
h
r
,
s
h
r
x_{hr},s_{hr}
xhr,shr,然后随机选择一个scale,对高分图片进行降采样得到模型的输入;模型包含两部分,encoder
E
ψ
E_\psi
Eψ,将降采样之后的图片编码得到其LIIF表示,还有是
f
θ
f_\theta
fθ是一个mlp;有了坐标
x
h
r
x_{hr}
xhr和latent code之后经过
f
θ
f_\theta
fθ得到预测的像素值,和真实的像素值计算损失;
- 实验
- 数据集:训练(DIV2K dataset),评测(DIV2K dataset,Set5, Set14, B100, Urban100);
- 评测的时候除了评测scale 1x-4x的,还评测了训练中没有的6x-30x,主要对比的方法是MetaSR;
- 实现细节:输入固定为 48 × 48 48\times 48 48×48,假设bs为 B B B,那么采样 B B B个scale r 1 ∼ B r_{1\sim B} r1∼B,之后再原高分图上crop出 { 48 r i × 48 r i } i = 1 B \{48r_i\times 48r_i\}^B_{i=1} {48ri×48ri}i=1B个对应的高分图像作为gt,对于bs的每一项,都采样 4 8 2 48^2 482个sample来计算损失;















 3721
3721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









