






文章目录
前言
善始者繁多,克终者盖寡。
目前市面上已经拥有很多深度学习的框架了,我们调用框架中的几行代码就可以实现较为复杂的操作和功能,但是想要更加熟练的运用这些框架以满足自己的实际需求,我们还是得需要从基础入手。下面和大家分享一下如何手写一个简易的BP神经网络。
一、BP神经网络
1.1 感知机与神经网络
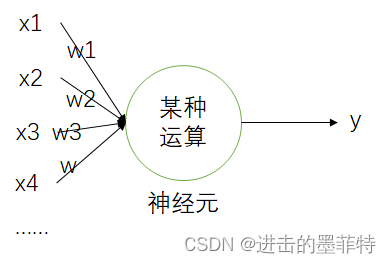
1957年美国学者Frank提出了“感知机”算法,感知机模仿人类生理上的“神经细胞”,感知机接收多个信号,输出一个信号,其结构如图所示。
 一个神经元可以接收多个信息,我们称之为输入,使用x表示;
一个神经元可以接收多个信息,我们称之为输入,使用x表示;
每个信息对最终输出信息的影响程度有所差异,我们称之为权重,使用w表示;
同时还需考虑未知因素的影响,我们称之为偏置,使用b表示。
最终输出信息可以表示为:
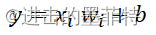
但是,并不是输入了信号就一定有信号输出,以人类生理上的“神经细胞”为例,只有给予的刺激到达了一定程度,神经细胞才会做出反馈,当刺激太小时神经细胞并不会有反应,那么一个神经元可以表示为:
我们常说的“神经网络”、“人工神经网络”就是模拟人类的神经细胞,感知机是神经网络算法的重要基础。
1.2 激活函数
1.1中提及的“某种操作”我们仍通过函数实现,我们称之为激活函数,在正向传播过程中需要使用到,使用f(x)表示,那么最终输出信息表示为:

1.2.1 sigmod函数
在BP神经网络的隐含层中常用的激活函数是sigmod函数:
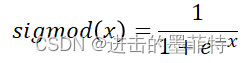
1.2.2 softmax函数
在BP神经网络的输出层中常用的激活函数是softmax函数,softmax函数就是对输出的结果进行“归一化”:

1.2.2 sigmod函数导数
在反向传播过程中需要使用相应激活函数的导函数,sigmod函数的导函数为:
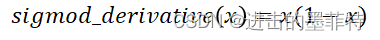
1.3 BP神经网络工作流程
BP((Back Propagation)神经网络是神经网络算法中的一种,它的工作流程主要有四个步骤:
前向传播->计算误差->反向传播->更新参数
其核心在于反向传播,即BP
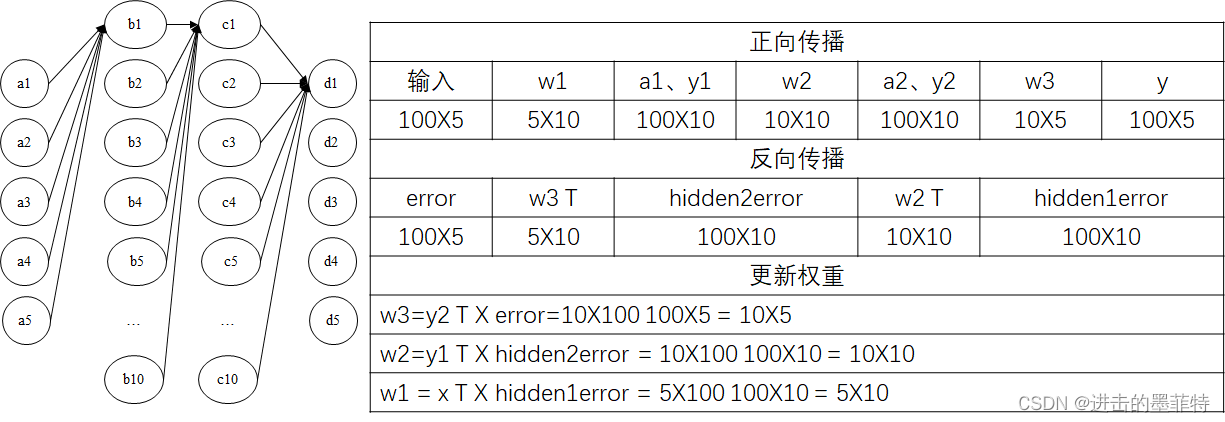
以一个包含两个隐含层的BP神经网络为例,为简化描述和计算后续操作未加入偏置,其结构图为:

①输入层神经元个数就是输入数据的维度,例如可以从ABCDE这5个方面评价一个人的学习能力,对于每一条数据而言,A维度数据放入a1,B维度数据放入a2,以此类推;
②隐含层神经元个数可以自行指定;
③对于二分类问题,输出层一个神经元就足够;
④对于多分类问题,输出层神经元个数与分类个数相同,哪个神经元输出的数字大,就认为被分到了哪个类。
1.3.1 前向传播
以1.3中包含两个隐含层的神经网络为例,其前向传播过程可以表示为:

1.3.2 计算误差
误差反映了模型实际输出(真实值)与期望值(标签)之间的差异,可以直接表示为:
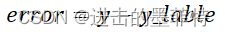
随着模型训练的进行,我们希望模型实际输出与期望值之间的差异越来越小,也就是希望误差越来越小,根据经验我们可以利用当前得到的误差去尝试调整模型中各层的权重w,以期下次得到的误差更小。
1.3.3 反向传播
反向传播是BP神经网络工作时最重要的一个环节,这个环节模拟了1.3.2中“根据误差调整权重”的操作。
我们可以将误差理解为信号,从整体上看,反向传播就是将这个信号从输出层传到输入层,并在传递的过程中调整各层权重;从每一层上看,每一层的信息量就是上层传来的信息量乘以激活函数的导数。反向传播过程可以表示为:

其中X表示矩阵相乘,*表示普通乘法;
矩阵相乘需要遵守严格的形状,W3T、W2T保证了矩阵相乘的正常进行。
1.3.4 更新权重
计算出每一层的误差后就可以更新每一层的权重了,参照反向传播,更新权重可以从后往前进行:

更新权重时将矩阵转置也是为了矩阵相乘能够正常进行;
learn作名词,译为“学习率”,用其控制参数更新的快慢,学习率大,每次更新权重时权重的变化率就大,依据经验,学习率的取值通常为0.01。
1.4 从形状上理解BP神经网络
以1.3中包含两个隐含层的BP神经网络为例,现将100条数据作为神经网络的输入,输入数据将被分为5个类别,则输入形状为100X5,输出形状为100X5,对于每一条记录(每一行)而言d1至d2输出的是该记录被分为该类别的“概率”(只是使用softmax归一化而言,说概率有一点不准确),我们认为概率最大的神经元的编号就是该条记录所属的类别。
二、python代码
2.1 二分类问题
构建一个包含两个隐含层的BP神经网络,解决二分类和多分类问题,二分类与多分类就是通过控制输出层神经元个数实现的,当输出层只有一个神经元时可以将其理解为二分类问题,当输出层包含3个及以上神经元时可以将其理解为多分类问题。
2.1.1 初始化参数
初始化操作主要是对神经网络中各层的权重进行初始化,使用random函数生成随机值生成权f重。
'''
input,hidden,output分别表示输入层、隐含层、输出层神经元的个数
'''
def __init__(self,input,hidden,output):
self.weight1 = numpy.random.randn(input,hidden)
self.weight2 = numpy.random.randn(hidden,hidden)
self.weight3 = numpy.random.randn(hidden,output)
#准确度,训练后预测正确数目与样本总数之比
self.accuracy = []
#精确度,对训练结果而言,模型正确预测某一类别的样本数与模型预测为该类的样本数之比
self.precision = []
#召回率,对原始样本而言,样本中某个类别有多少被正确预测了
self.recall = []
#损失值
self.loss = []
2.1.2 激活函数
分别创建softmax、sigmod及其导函数。
#sigmod激活函数
def sigmod(self,x):
return 1/(1 + numpy.exp(-x))
#sigmod函数的导数
def sigmod_derivative(self, x):
return x * (1 - x)
#softmax激活函数
def softmax(self,x):
#按行计算每一个样本
exps = numpy.exp(x - numpy.max(x,axis=1,keepdims=True))
#为避免指数溢出numpy能够表示的上限,使其减去当前数据中的最大值
return exps/numpy.sum(exps,axis=1,keepdims=True)
2.2.3 前向传播
使用numpy中的dot函数实现两矩阵相乘,计算每层每个神经元的输入后在使用激活函数计算其输出。
#前向传播
def forword(self,data):
#存储每一层的输入和输出
self.hidden1_input = numpy.dot(data, self.weight1)
self.hidden1_output = self.sigmod(self.hidden1_input)
self.hidden2_input = numpy.dot(self.hidden1_output,self.weight2)
self.hidden2_output = self.sigmod(self.hidden2_input)
self.output_input = numpy.dot(self.hidden2_output,self.weight3)
self.output_output = self.softmax(self.output_input)
return self.output_output
2.2.4 反向传播(最重要步骤)
此方法中包含了计算误差、反向传播、更新参数三个步骤,是BP神经网络中最重要的算法,此处代码皆为1.3中公式的具体实现。
#后向传播
def backword(self,data,label,learning_ration):
#首先计算误差(损失),交叉熵的导函数
output_error = self.output_output - label
#输出层误差项(包含了误差、激活函数导数两部分信息)
output_delta = output_error
#将输出层的误差传入隐藏层2
hidden2_error = numpy.dot(output_delta,self.weight3.T) * self.sigmod_derivative(self.hidden2_output)
#将隐藏层2的误差传入隐藏层1
hidden1_error = numpy.dot(hidden2_error,self.weight2.T) * self.sigmod_derivative(self.hidden1_output)
#三层误差已经得出,可以开始更新权重了
self.weight1 -= numpy.dot(data.T,hidden1_error) * learning_ration
self.weight2 -= numpy.dot(self.hidden1_output.T, hidden2_error) * learning_ration
self.weight3 -= numpy.dot(self.hidden2_output.T, output_error) * learning_ration
2.2.5 训练模型与预测结果
训练模型其实就是让正向传播、计算误差、反向传播、更新参数的操作重复执行很多次而言,经过多轮前后传播,各层的权重也从最开始随机的取值变为了我们期望的样子;
预测结果就是使用已经调好的权重,计算输入数据的结果。
#训练数据集
def train(self,data,label,learning_ration,epoch):
for i in range(epoch):
output = self.forword(data)
self.backword(data,label,learning_ration)
self.loss.append(self.loss_cross_entropy(label,output))
accuary = self.caculate_accuracy(output,label)
self.accuracy.append(accuary)
# print("accuary:",accuary)
# self.show_weights()
def predict(self,data):
return self.forword(data)
2.2 多分类问题(一定要看)
到目前为止,我们完成了一个简单的BP神经网络并可以解决二分类问题,但是对于多分类问题,输出层包含多个神经元,使用2.2.5中的predict函就有些力不从心了,在2.1的基础上,我们还需要添加一些额外的方法。
独热编码
现有一个5分类问题,假设某次输入[1,2,3,4,5],[2,4,6,8,10] 两条记录,程序的实际输出分别为[0.1,0.2,0.3,0.4,0.5],[0.7,0.15,0.3,0.47,0.56],根据肉眼判断,第一条记录被分为第5类的概率最大,第二条记录被分为第1类的概率最大。对于这样的信息,我们关注的只有概率最大的那一个值,其他的信息都属于无用信息,所有我们可以将程序的两个实际输出转换为[0,0,0,0,1],[1,0,0,0,0]的形式。变换后概率最大的类别上取值为1,其余都为0,我们称此种编码方式为独热编码。
此方法可以很方便实现实际值与期望值的比较
def one_hot_encoding(self,data:list):
max = data[0]
max_index = 0
for i in range(len(data)):
if data[i]>max:
max = data[i]
max_index = i
for i in range(len(data)):
if i==max_index:
data[i]=1
else:
data[i]=0
return data
#使用训练好的数据预测结果
def predict_ont_hot(self,data:list):
data = self.predict(data)
result = []
for i in range(len(data)):
#将numpy.ndarray转换为普通的List
temp = self.one_hot_encoding(data[i].tolist())
result.append(temp)
return result
2.3 模型性能分析
2.3.1 准确率、召回率、精确度
以二分类问题入手,我们将样本划分为正类和负类两个类别,将模型输出(实际值)与标签(真实值)对比,我们可以得到如此矩阵:
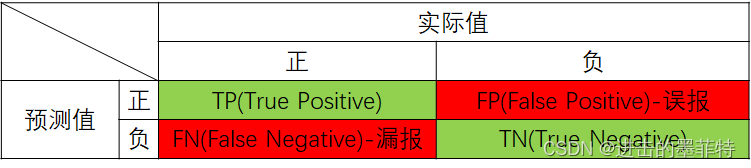 TP:将正类预测为正类的情况。(预测正确)
TP:将正类预测为正类的情况。(预测正确)
TN:将负类预测为负类的情况。(预测正确)
FP:将负类预测为正类的情况。(预测错误)
FN:将正类预测为负类的情况。(预测错误)
准确率:从整体上反映了模型预测的准确情况,其数值等于正确预测数除以样本总数。
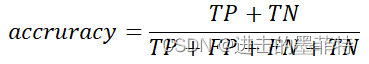
召回率:对原始数据的描述,反映了原始样本中被正确分类的比例,其数值等于被正确分类的正类个数除以样本中的正类个数。

精确度:对预测数据的描述,反映了预测样本中被正确分类的比例,其数值等于被正确分类的正类个数除以预测为正类的个数。

对于上述三项指标,理应是越大越好。
2.3.2 损失函数
损失同误差一样描述了模型输出(实际值)与标签(期望值)之间的差距,只是计算方式不同,损失函数就是对应损失的计算公式,常见的损失函数有交叉熵、方差。
交叉熵计算公式:

y表示样本的真实值(标签);
p是predict的缩写,表示模型的预测值。
方差计算公式:
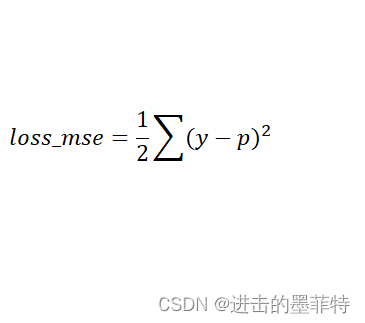
y表示样本的真实值(标签);
p是predict的缩写,表示模型的预测值;
添加1/2的目的是方便求导。
2.3.3 代码实现
#比较两个列表是否相同
def compare(self,list1:list,list2:list):
if len(list1)!= len(list2):
return
for i in range(len(list1)):
if list1[i]!=list2[i]:
return 0
return 1
def caculate_accuracy(self,actual_label,label):
true_count = 0
false_count = 0
result = []
for i in range(len(actual_label)):
# 将numpy.ndarray转换为普通的List
temp = self.one_hot_encoding(actual_label[i])
result.append(temp)
actual_label = result
size = len(label)
for i in range(size):
rs = self.compare(actual_label[i],label[i])
if rs==1:
true_count += 1
else:
false_count += 1
# print(f"正确个数为{true_count},总个数为{size}")
return true_count/size
def loss_cross_entropy(self,y,p):
'''
:param y: 真实标签
:param p: 预测标签
:return: 交叉熵
'''
# p = self.softmax(p)
#为了避免出现log(0)的情况,计算时加上一个极小值
min_data = 1e-15
# return -1 * numpy.sum(y*numpy.log(p+min_data))
return -numpy.mean(y*numpy.log(p+min_data))
def loss_cross_entropy_derivative(self,label_true,label_predict):
return label_true - label_predict
#使用均方差作为损失函数
def loss_mse(self,x,y):
return 1/2*numpy.sum((x-y)*(x-y))
def show_loss(self):
# print(self.loss)
pyplot.title("LOSS")
pyplot.xlabel("epoch")
pyplot.ylabel("ration")
pyplot.plot(self.loss)
pyplot.show()
def show_accuracy(self):
# print(self.loss)
pyplot.title("Accuaracy")
pyplot.xlabel("epoch")
pyplot.ylabel("ration")
pyplot.plot(self.accuracy)
pyplot.show()
三、程序测试
3.1 数据集
测试数据集已上传,大家可以下载使用。有些小伙伴经常听别人说数据集、训练数据集时常常感觉很迷惑,下面我们直接来看一下数据集掌什么样子,数据在python是如何表示的。以前三条记录为例,excel中前三条记录为:
 那么对应的输入使用嵌套列表表示为:
那么对应的输入使用嵌套列表表示为:
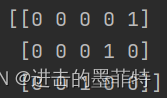
 对应标签也就是“评级分”表示为:
对应标签也就是“评级分”表示为:
3.2 加载数据
我们学习神经网络肯定希望能够使用自己的数据集来训练网络,那么加载数据的操作就是必不可少的,在多分类问题中,加载数据一个重要的操作是将分类转换为独热编码!
按照国人习惯,分类序号从1开始。
def load_data():
df = pandas.read_excel("data.xlsx")
data_temp = df[["A","B","C","D","E"]]
label_temp = df["评级分"]
data = []
label = []
DIMENSION = len(data_temp.columns)
for i in range(df.shape[0]):
data.append(data_temp.iloc[i].to_list())
#对训练集标签进行独热编码
temp = []
for j in range(DIMENSION):
temp.append(0)
index = label_temp[i]-1
temp[index] = 1
# temp.append(label_temp[i])
label.append(temp)
data = numpy.array(data)
label = numpy.array(label)
return data,label
3.3 构建网络并训练模型
构建一个形状为“51010*5”的BP神经网络,数据前75%用作训练集,后25%用作测试集,使其训练50000次。(通常按80%,20%的比例分,如何分根据个人经验)
if __name__ == '__main__':
data,label = load_data()
# print(data,"\n",label)
#划分训练集与测试集
data_train = data[0:int(len(data)*3/4)]
data_train_train = data_train[0:int(len(data_train)*3/4)]
data_train_test = data_train[int(len(data_train)*1/4)*(-1):-1]
data_test = data[int(len(data)*1/4)*(-1):-1]
label_train = label[0:int(len(label) * 3 / 4)]
label_train_train = label_train[0:int(len(data_train) * 3 / 4)]
label_train_test = label_train[int(len(data_train) * 1 / 4) * (-1):-1]
label_test = label[int(len(label) * 1 / 4) * (-1):-1]
# print(len(data_train),len(data_test))
#构建一个包含两层隐含层的神经网络
network = BPNet.BPNetwork(5,10,5)
#训练神经网络
# network.train(data_train_train,label_train_train,0.02,50000)
network.train(data_train,label_train,0.01,50000)
network.show_loss()
network.show_accuracy()
# print(f"最终准确率是{network.accuracy[-1]}")
#预测结果-训练集中的验证集
# print(network.predict(data_train_test))
# print(network.predict_ont_hot(data_train_test))
# print(f"准确率是:{network.caculate_accuracy(network.predict_ont_hot(data_train_test),label_train_test)}")
#测试集
# print(network.predict(data_test))
result = network.predict_ont_hot(data_test)
print(result)
print(label_test)
acc = network.caculate_accuracy(result,label_test)
print(f"测试集上的准确率是{acc}")
注意:文中实现的BP神经网络隐含层神经元的个数与目标分类数目相同,隐含层神经元个数可自行指定。
例如:假设隐含层神经元个数为20,对于一个三分类问题,输入数据包含4个维度,则代码应为network = BPNet.BPNetwork(4,20,3);对于一个8分类问题,输入数据包含7个维度,则代码应为network = BPNet.BPNetwork(7,20,8)
除此之外有些小伙伴也常常理不清训练集、验证集、测试集,我们可以通过下图帮助理解,本文使用的数据集较小,所有并没有在训练集上进行划分。

为了验证我们构建的模型的效果,我们将原始数据集划分为了训练集和测试集两个部分,在训练集上训练模型(更新权重),训练完毕后,将测试集输入模型验证效果(将实际输出与测试集中数据的标签对比,看看精度、准确率如何);
通常情况下模型需要进行多次调整,训练好模型后直接使用测试集测试太过浪费时间和资源,于是,我们将训练集又划分为了两个部分,一个是训练集一个是验证集,当模型在验证集上的效果较好时,才去测试集上测试(因为验证集样本数量远少于测试集,所有更加节省时间和资源)
3.4 模型效果分享
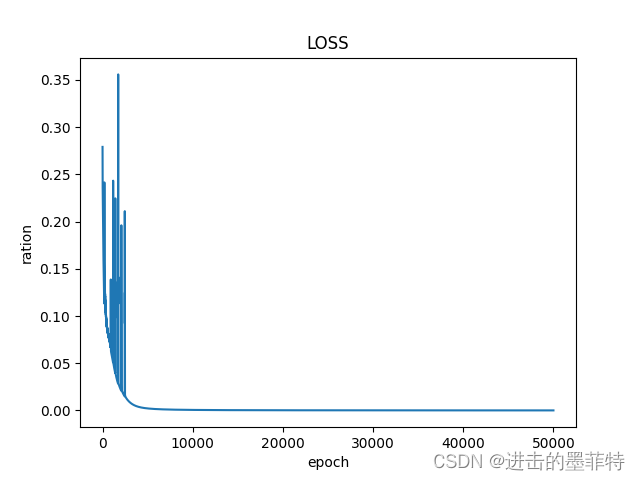
3.4.1 损失分布
随着训练的进行,损失值逐步减少。
3.4.2 准确率分布
随着训练的进行,模型在测试集上的准确率逐步提高,最终到达100%。

3.4.3 测试集准确率
该模型在训练集上表现良好,在测试集上却极其拉胯,还有很多地方可以优化!!!

四、完整代码
4.1 BP神经网络
import numpy
from matplotlib import pyplot
'''
构建一个包含两个隐含层的BP神经网络
'''
class BPNetwork:
'''
input,hidden,output分别表示输入层、隐含层、输出层神经元的个数
'''
def __init__(self,input,hidden,output):
self.weight1 = numpy.random.randn(input,hidden)
self.weight2 = numpy.random.randn(hidden,hidden)
self.weight3 = numpy.random.randn(hidden,output)
#准确度,训练后预测正确数目与样本总数之比
self.accuracy = []
#精确度,对训练结果而言,模型正确预测某一类别的样本数与模型预测为该类的样本数之比
self.precision = []
#召回率,对原始样本而言,样本中某个类别有多少被正确预测了
self.recall = []
#损失值
self.loss = []
#比较两个列表是否相同
def compare(self,list1:list,list2:list):
if len(list1)!= len(list2):
return
for i in range(len(list1)):
if list1[i]!=list2[i]:
return 0
return 1
def caculate_accuracy(self,actual_label,label):
true_count = 0
false_count = 0
result = []
for i in range(len(actual_label)):
# 将numpy.ndarray转换为普通的List
temp = self.one_hot_encoding(actual_label[i])
result.append(temp)
actual_label = result
size = len(label)
for i in range(size):
rs = self.compare(actual_label[i],label[i])
if rs==1:
true_count += 1
else:
false_count += 1
# print(f"正确个数为{true_count},总个数为{size}")
return true_count/size
def one_hot_encoding(self,data:list):
max = data[0]
max_index = 0
for i in range(len(data)):
if data[i]>max:
max = data[i]
max_index = i
for i in range(len(data)):
if i==max_index:
data[i]=1
else:
data[i]=0
return data
#sigmod激活函数
def sigmod(self,x):
return 1/(1 + numpy.exp(-x))
#sigmod函数的导数
def sigmod_derivative(self, x):
return x * (1 - x)
#softmax激活函数
def softmax(self,x):
#按行计算每一个样本
exps = numpy.exp(x - numpy.max(x,axis=1,keepdims=True))
#为避免指数溢出numpy能够表示的上限,使其减去当前数据中的最大值
return exps/numpy.sum(exps,axis=1,keepdims=True)
def loss_cross_entropy(self,y,p):
'''
:param y: 真实标签
:param p: 预测标签
:return: 交叉熵
'''
# p = self.softmax(p)
#为了避免出现log(0)的情况,计算时加上一个极小值
min_data = 1e-15
# return -1 * numpy.sum(y*numpy.log(p+min_data))
return -numpy.mean(y*numpy.log(p+min_data))
def loss_cross_entropy_derivative(self,label_true,label_predict):
return label_true - label_predict
#使用均方差作为损失函数
def loss_mse(self,x,y):
return 1/2*numpy.sum((x-y)*(x-y))
#前向传播
def forword(self,data):
#存储每一层的输入和输出
self.hidden1_input = numpy.dot(data, self.weight1)
self.hidden1_output = self.sigmod(self.hidden1_input)
self.hidden2_input = numpy.dot(self.hidden1_output,self.weight2)
self.hidden2_output = self.sigmod(self.hidden2_input)
self.output_input = numpy.dot(self.hidden2_output,self.weight3)
self.output_output = self.softmax(self.output_input)
return self.output_output
#后向传播
def backword(self,data,label,learning_ration):
#首先计算误差(损失),交叉熵的导函数
output_error = self.output_output - label
#输出层误差项(包含了误差、激活函数导数两部分信息)
output_delta = output_error
#将输出层的误差传入隐藏层2
hidden2_error = numpy.dot(output_delta,self.weight3.T) * self.sigmod_derivative(self.hidden2_output)
#将隐藏层2的误差传入隐藏层1
hidden1_error = numpy.dot(hidden2_error,self.weight2.T) * self.sigmod_derivative(self.hidden1_output)
#三层误差已经得出,可以开始更新权重了
self.weight1 -= numpy.dot(data.T,hidden1_error) * learning_ration
self.weight2 -= numpy.dot(self.hidden1_output.T, hidden2_error) * learning_ration
self.weight3 -= numpy.dot(self.hidden2_output.T, output_error) * learning_ration
#训练数据集
def train(self,data,label,learning_ration,epoch):
for i in range(epoch):
output = self.forword(data)
self.backword(data,label,learning_ration)
self.loss.append(self.loss_cross_entropy(label,output))
accuary = self.caculate_accuracy(output,label)
self.accuracy.append(accuary)
# print("accuary:",accuary)
# self.show_weights()
#使用训练好的数据预测结果
def predict_ont_hot(self,data:list):
data = self.predict(data)
result = []
for i in range(len(data)):
#将numpy.ndarray转换为普通的List
temp = self.one_hot_encoding(data[i].tolist())
result.append(temp)
return result
def predict(self,data):
return self.forword(data)
def show_weights(self):
print(f"{self.weight1}\n{self.weight2}\n{self.weight3}")
def show_loss(self):
# print(self.loss)
pyplot.title("LOSS")
pyplot.xlabel("epoch")
pyplot.ylabel("ration")
pyplot.plot(self.loss)
pyplot.show()
def show_accuracy(self):
# print(self.loss)
pyplot.title("Accuaracy")
pyplot.xlabel("epoch")
pyplot.ylabel("ration")
pyplot.plot(self.accuracy)
pyplot.show()
if __name__ == '__main__':
# 创建训练数据集
X_train = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_train = numpy.array([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
# 创建测试数据集
X_test = numpy.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y_test = numpy.array([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
learning_ration = 0.01
network = BPNetwork(2,10,4)
network.train(X_train,y_train,learning_ration,10000)
# print(network.predict(X_test))
print(network.predict_ont_hot(X_test))
network.show_loss()
network.show_accuracy()
# print(network.predict([0,1,1]))
4.2 测试程序
import pandas
import BPNet
import numpy
def load_data():
df = pandas.read_excel("data.xlsx")
data_temp = df[["A","B","C","D","E"]]
label_temp = df["评级分"]
data = []
label = []
DIMENSION = len(data_temp.columns)
for i in range(df.shape[0]):
data.append(data_temp.iloc[i].to_list())
#对训练集标签进行独热编码
temp = []
for j in range(DIMENSION):
temp.append(0)
index = label_temp[i]-1
temp[index] = 1
# temp.append(label_temp[i])
label.append(temp)
data = numpy.array(data)
label = numpy.array(label)
return data,label
if __name__ == '__main__':
data,label = load_data()
# print(data,"\n",label)
#划分训练集与测试集
data_train = data[0:int(len(data)*3/4)]
data_train_train = data_train[0:int(len(data_train)*3/4)]
data_train_test = data_train[int(len(data_train)*1/4)*(-1):-1]
data_test = data[int(len(data)*1/4)*(-1):-1]
label_train = label[0:int(len(label) * 3 / 4)]
label_train_train = label_train[0:int(len(data_train) * 3 / 4)]
label_train_test = label_train[int(len(data_train) * 1 / 4) * (-1):-1]
label_test = label[int(len(label) * 1 / 4) * (-1):-1]
# print(len(data_train),len(data_test))
#构建一个包含两层隐含层的神经网络
network = BPNet.BPNetwork(5,10,5)
#训练神经网络
# network.train(data_train_train,label_train_train,0.02,50000)
network.train(data_train,label_train,0.01,50000)
network.show_loss()
network.show_accuracy()
# print(f"最终准确率是{network.accuracy[-1]}")
#预测结果-训练集中的验证集
# print(network.predict(data_train_test))
# print(network.predict_ont_hot(data_train_test))
# print(f"准确率是:{network.caculate_accuracy(network.predict_ont_hot(data_train_test),label_train_test)}")
#测试集
# print(network.predict(data_test))
result = network.predict_ont_hot(data_test)
print(result)
print(label_test)
acc = network.caculate_accuracy(result,label_test)
print(f"测试集上的准确率是{acc}")
















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











