









为什么每天都有解决不完的问题,一个问题延伸出来十个问题。虽然大都可以解决,但是也只是停留在解决的层面,终究不是学习之道。
技术不停变更,我相信最本质的原理也就那么几个,一定要挖祖坟 似的学习!
一步一步慢慢来吧~
首先来做几个简单的测试:
测试一
javac -encoding : -encoding <编码> ---- 指定源文件使用的字符编码
对于如下代码:
public class Demo {
public static void main(String[] args) {
System.out.println(System.getProperty("file.encoding"));
System.out.println("hello,中国");
}
}
格式以UTF-8无BOM类型保存
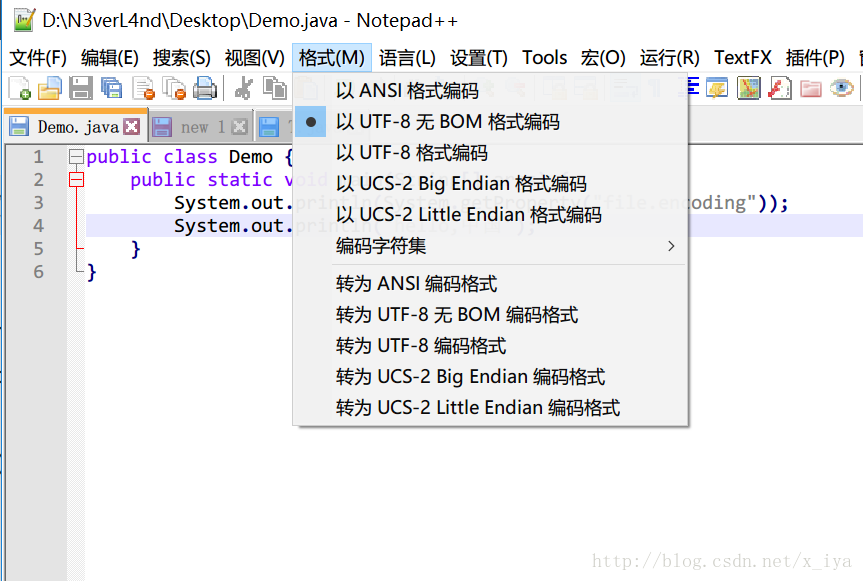
我们分别使用cmd(默认GBK编码)和MinTTY(UTF-8编码)来读取该文件
-encoding encoding Set the source file encoding name, such as EUC-JP and UTF-8. If -encoding is not specified, the platform default converter is used.
也就是说,如果不指定encoding,则使用平台默认的编码转换器。
在简体中文的Windows上,平台默认编码会是GBK,那么javac就会默认假定输入的Java源码文件是以GBK编码的。
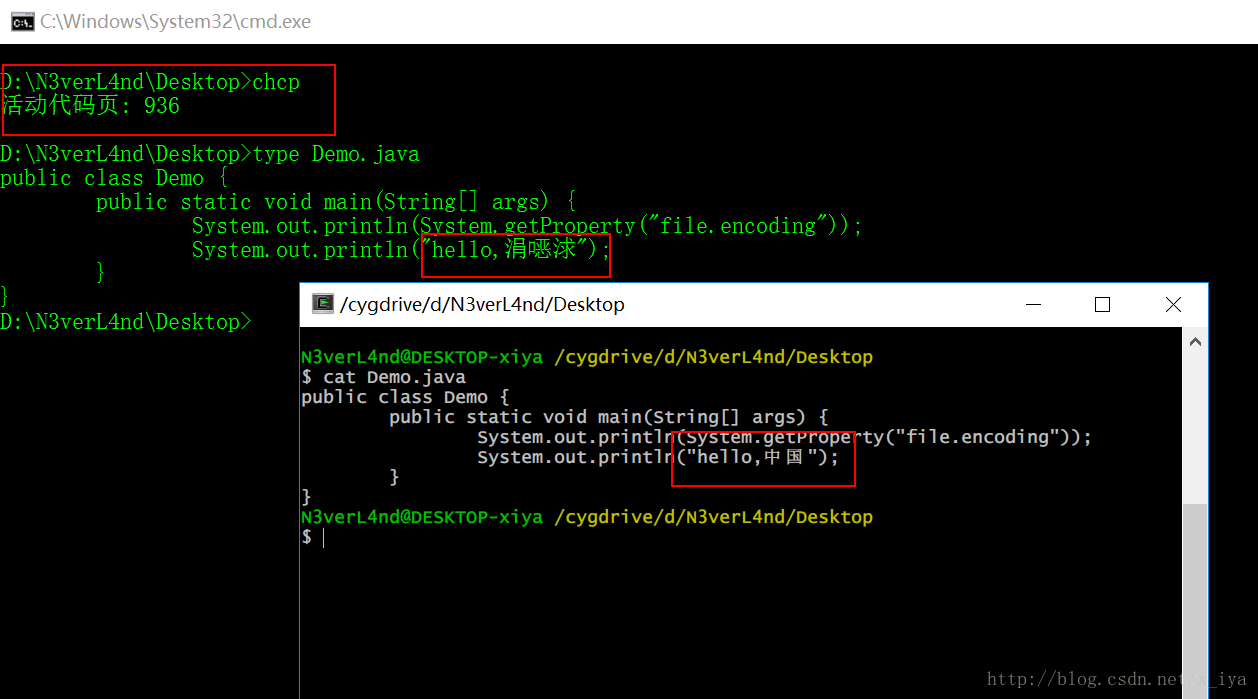
我们先来证明这句话:
javac Demo.java
对应的字节码文件:
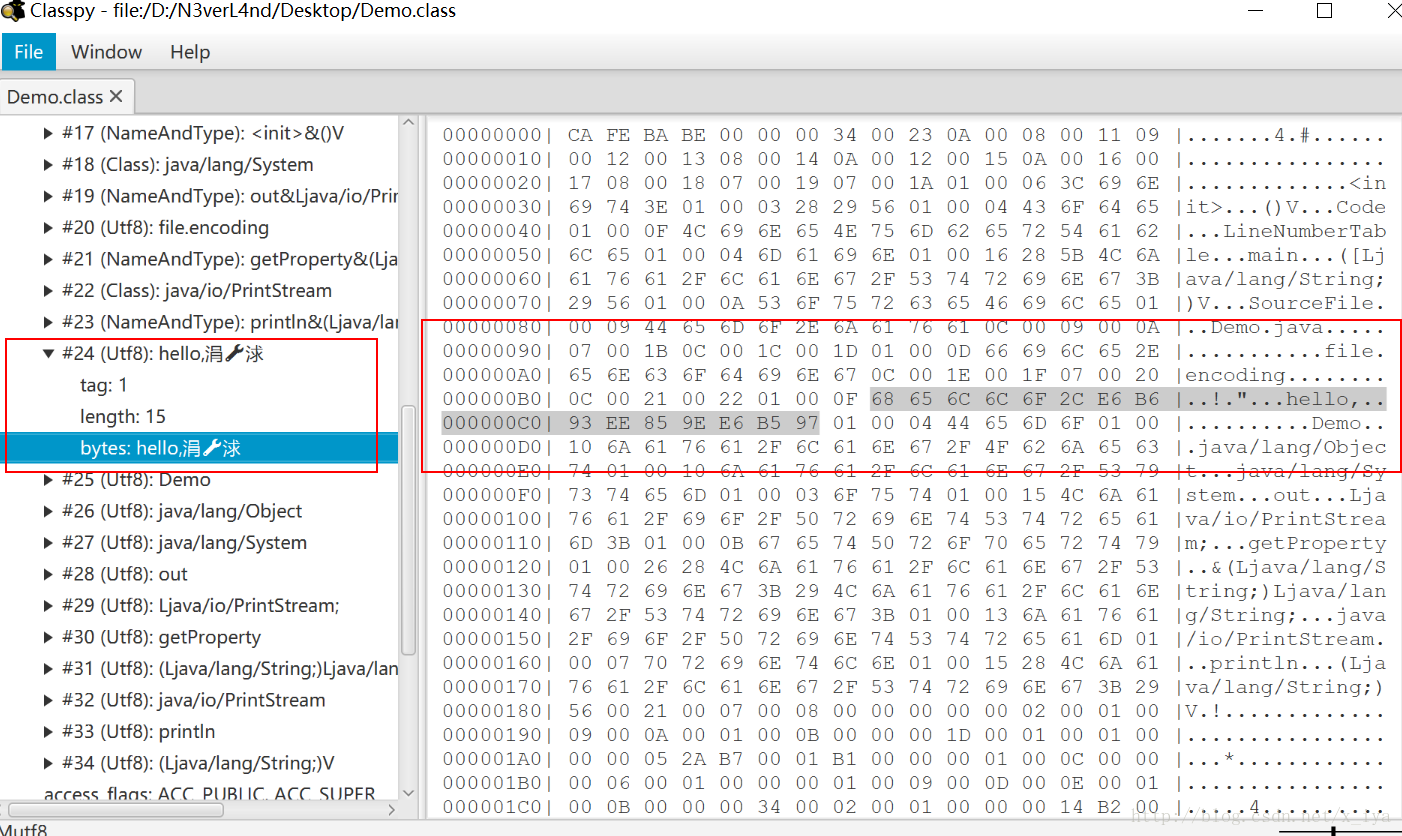
我们模拟下以上16进制的获得:
String str = new String("中国".getBytes("UTF-8"), "GBK");
System.out.println(str);//涓浗
System.out.println(DatatypeConverter.printHexBinary(str.getBytes("UTF-8")));//E6B693EE859EE6B597
javac -encoding GBK Demo.java
对应的字节码文件:
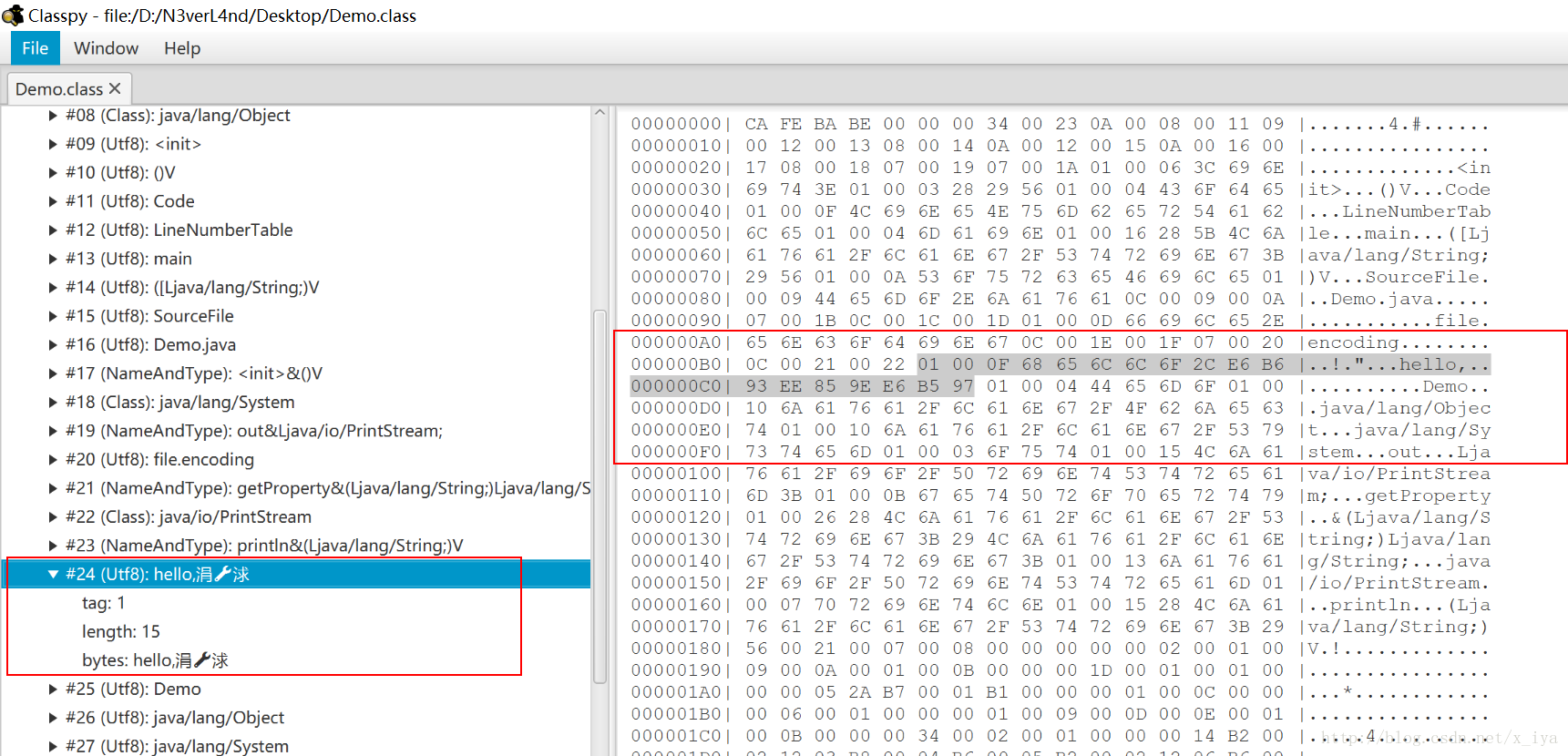
如果实际输入的确实是 GBK 编码(GBK兼容ASCII编码)的文件,那么一切都会正常。
但如果实际输入的是别的编码的文件,例如UTF-8编码的文件,那 javac 读进来的内容就会出问题,就“乱码”了。乱码的原因:使用 GBK 解码 UTF-8 编码的文件。
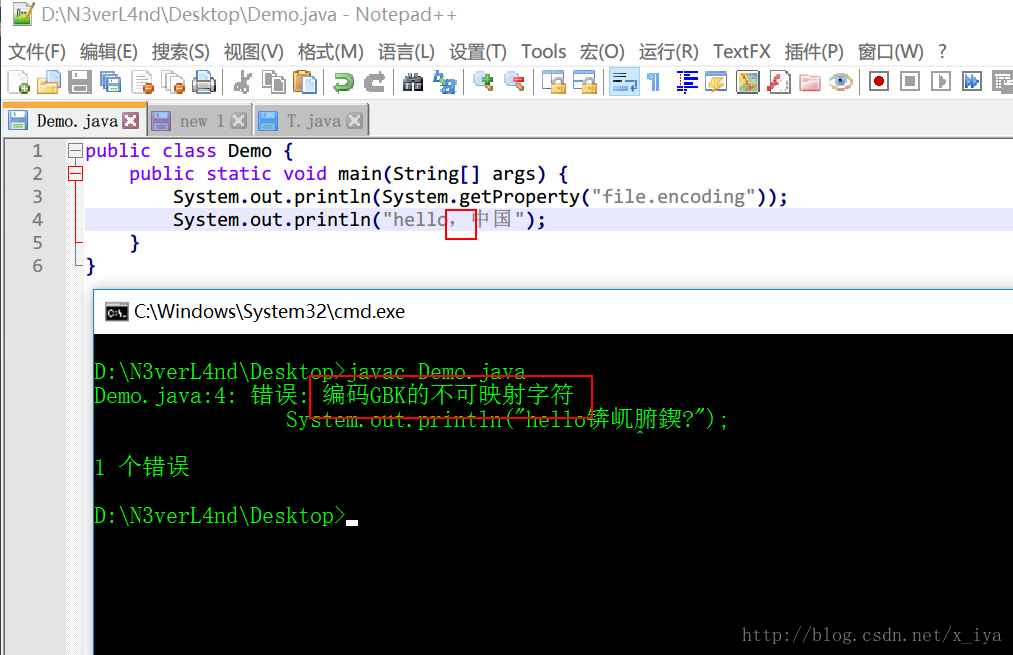
测试二
java -Dfile.encoding 是用来干什么的?
javac -encoding GBK Demo.java
在 windows 平台生成 class 文件,拖到 Ubuntu 操作系统中。
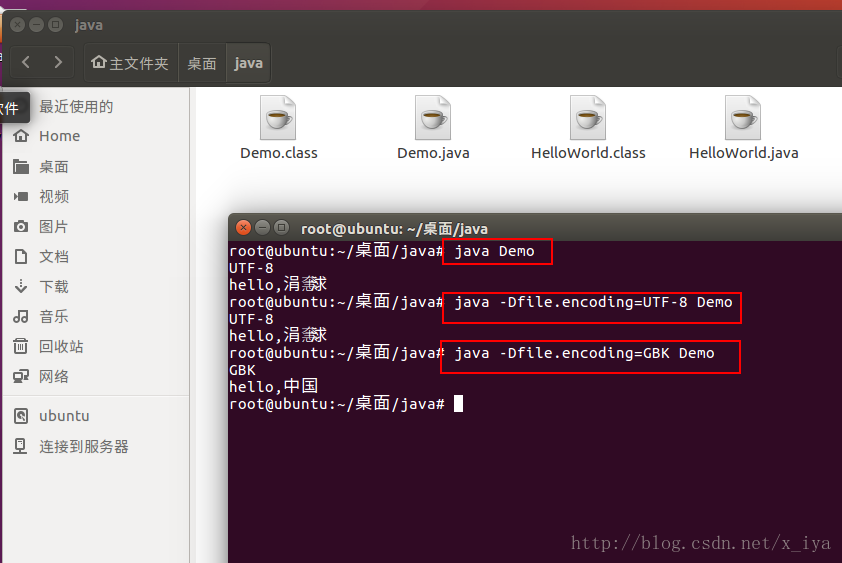
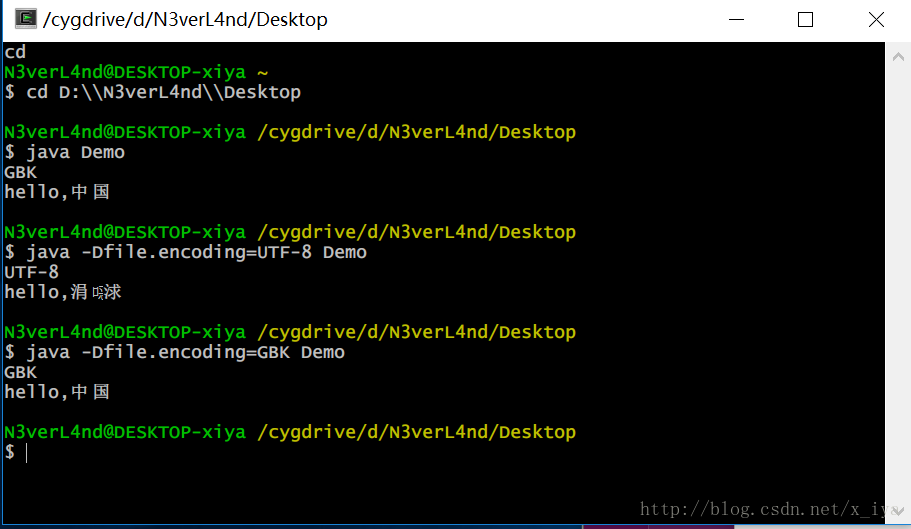
Cygwin下的测试结果:
cmd下的测试结果:
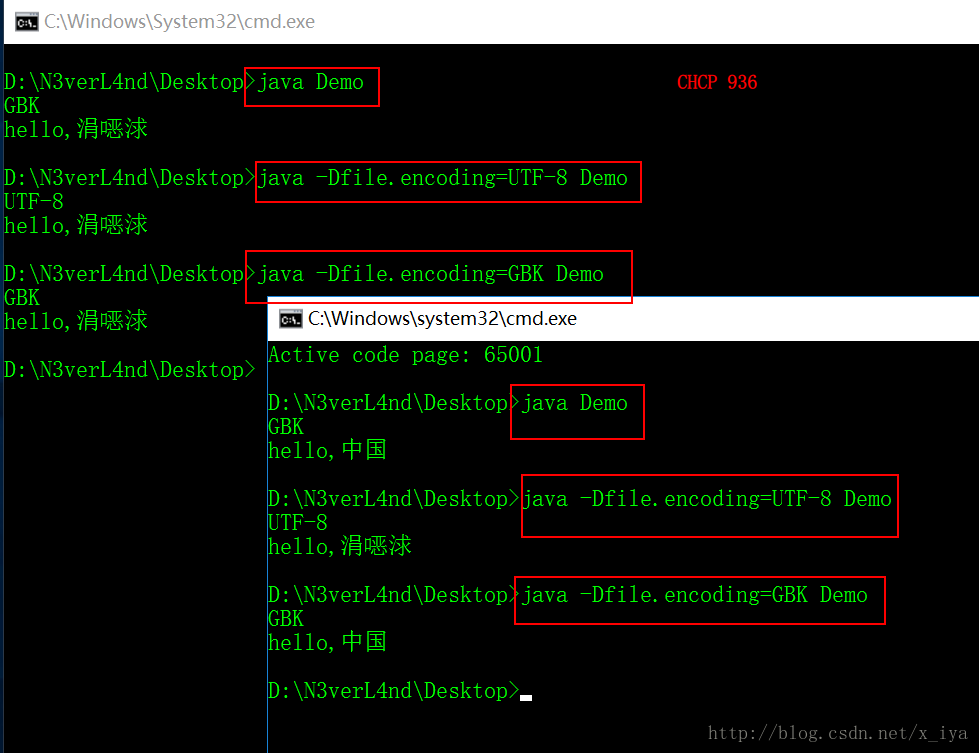
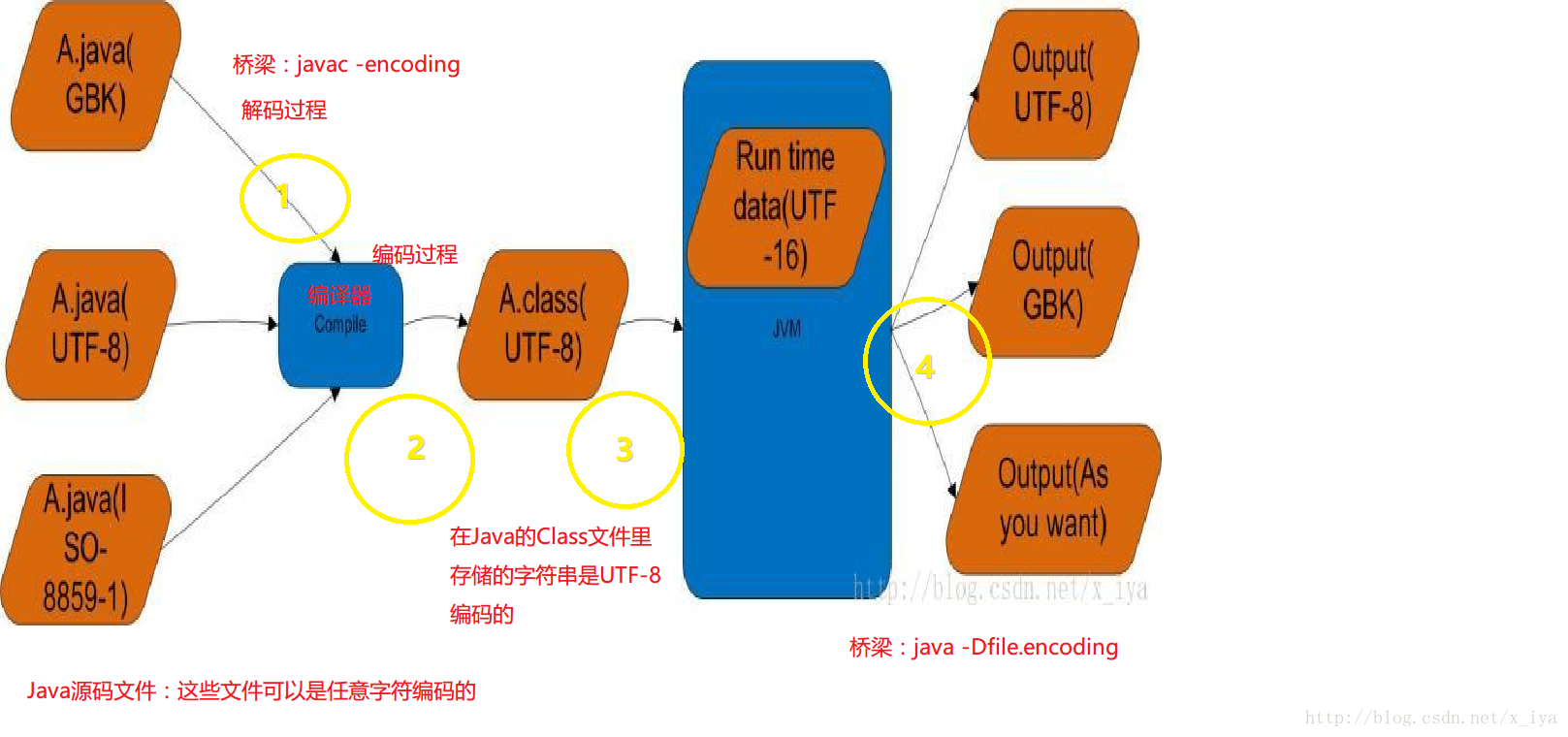
针对以上这个图做一些解释:
①、A.java就是一个文本文件(以某种编码格式来存储:UTF-8、GBK、ISO-8859-1等),java编译器要解析这个文本文件并编译生成.class文件。而要想解析它,就必须知道它的编码方式。(javac - encoding charset)
②:以不同编码方式编码的A.java经过Java编译器编译生成了同一个相同的A.class。(字符串以UTF-8格式存储)
字节码解读见:http://blog.csdn.net/x_iya/article/details/77073112
③:java虚拟机以二进制字节流的形式加载A.class,读取该字符串并构建String。
④:输出结果。
可以知道只有①和③才会导致乱码的产生。
④产生的乱码与接收环境有关,故不做讨论。
从上图可以理解不管采用哪种格式编码的源文件(.java),只要正确告诉编译器,编译器就会得到正确的结果(.class)。同时只要告诉JVM正确的输出流需要的编码格式,JVM总会返回正确编码格式的输出流。
那么要想不产生乱码要注意两个环节:
- 告诉编译器(javac -encoding)你的源文件编码格式。
- 告诉 JVM 字符串编码方式。(java -Dfile.encoding)
即两者保持一致。
对于以UTF-8编码的源文件A.java,只要:
javac -encoding UTF-8 A.java
java -Dfile.encoding=UTF-8 A
便可以解决乱码问题。
也许你会说命令行下依旧是乱码,那是命令行的问题(chcp 936),调整为chcp 65001, 或者在Cygwin命令行下使用。
另外String.getBytes() 等价于 String.getBytes(Charset.defaultCharset()) ,在实际编程中推荐使用带参数的。Charset.defaultCharset() 在Windows中文操作系统中是GBK。
当然也不是一成不变的,可以使用java -Dfile.encoding 指定。
@Test
public void testAvailableCharsets() {
//Java虚拟机编码方式
System.out.println("defaultCharset:" + Charset.defaultCharset().name());
//所有Java支持的字符集
Charset.availableCharsets().forEach((s, charset) -> System.out.println(s + ":" + charset));
}
模拟下Java读取、编译、运行*.java 的过程:
import javax.xml.bind.DatatypeConverter;
import java.io.UnsupportedEncodingException;
public class Test {
/**
* 模拟 javac -encoding
* 实现 *.java --> *.class
*
* @param str 字符串
* @param charset 实际字符串编码格式
* @param encoding 输入编码参数
* @return *.class 字节里的字节序列
*/
private static byte[] compile(String str, String charset, String encoding) {
try {
//读取(对应于图中的①)
str = new String(str.getBytes(charset), encoding);
//编码到*.class中(对应于图中的②)
return str.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
//模拟结果输出
private static String run(byte[] buf, String charset, String encoding) {
try {
//对应于图中的③
String str = new String(buf, "UTF-8");
//对应于图中的④
return new String(str.getBytes(encoding), charset);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "中国";
String charset = "UTF-8";
String encoding = "GBK";
//等价于 javac -encoding %encoding% *.java(以 charset 格式编码的源文件)
// compileBytes 数组即为 str 在 *.class 的表示
byte[] compileBytes = compile(str, charset, encoding);
System.out.println(DatatypeConverter.printHexBinary(compileBytes));
System.out.println(run(compileBytes, charset, encoding));
}
}
参考:
https://www.zhihu.com/question/30977092
http://abingsky37.github.io/java_encode.html
http://www.wuxinjian.com/2017/01/08/Java中的字符编码与乱码/
http://blog.csdn.net/u010234516/article/details/52842170
我们遇到的很多核心或者本质问题,也就那一小撮人能够解决。而我们要做的就是要成为那一小撮人。
在此感谢下RednaxelaFX大神。















 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











