







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
python爬取ts分段视频,以韩国TV网站为例
前言
提示:这里可以添加本文要记录的大概内容:
一.本文展示如何用python代码爬取不可以直接下载的视频文件。其中韩剧TV中的视频是切片成ts的,一个个,所以我们要知道一系列的地址,下方为该网站截图。
二。在文件合并时,要注意文件命名的顺序安装如图所示的样式,字符宽度的输出,不可以1,2,3,4…这种,因为默认合并顺序会报错文件会以这种顺序合并:1,11,111…,2,22,222…达不到正确的合并顺序这一点尤为注意

假如我要爬取这个视频《娱乐天下》,那么我就这样定位,然后找到url
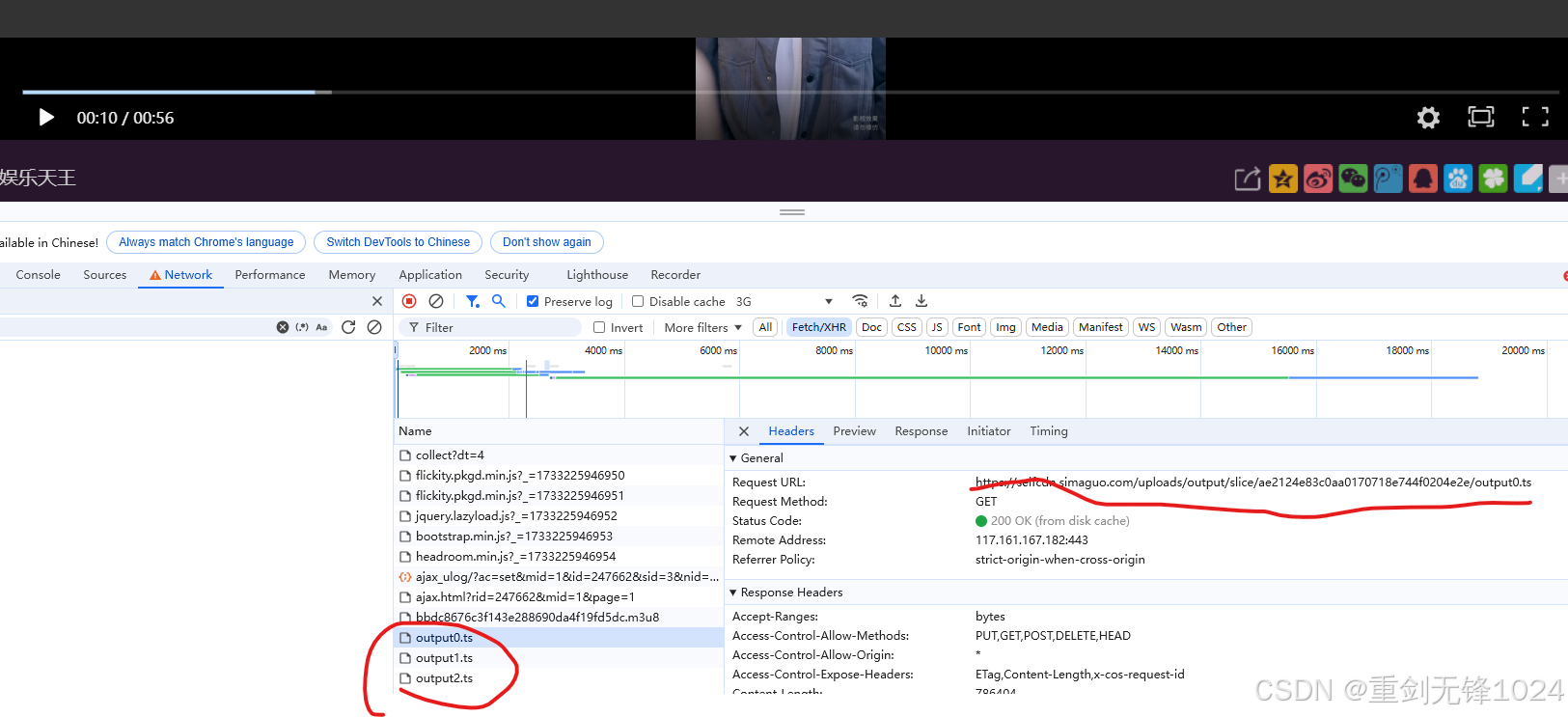
一、download函数
下方函数的url替换成自己想要爬取视频的url。timeout的设置代表是给它多少时间完成,下载归为一个列表,下次再进行下载,此外我们开启了多线程下载。
def download(num, flag=0):
# https://*****/20200508/19312_c9d456ff/1000k/hls/output1.ts
url = f'https://***************************************/output{
num}.ts'
print(url)
r = requests.get(url, headers=headers, timeout=10)
if r.status_code == 200:
with open(path + "download\\" + str(f'{
num:04d}.ts'), 'wb') as f:
try:
r.encoding = 'utf-8'
print(f'正在下载第{
num}个片段成功。')
f.write(r.content)
if flag == 1:
failure_list 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2243
2243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









