






📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
近年来,自监督学习(Self-Supervised Learning,SSL)作为一种新兴的学习范式,在计算机视觉、自然语言处理等多个领域都取得了显著的进展。与传统的监督学习不同,自监督学习不依赖于人工标注的数据,而是通过从未标注的数据中自动生成标签,进而进行学习。这一特性使得自监督学习在数据稀缺的场景中展现出强大的潜力。本文将深入探讨自监督学习的基本概念、方法以及实际案例,以帮助读者更好地理解这一重要技术。
一、自监督学习的概念
自监督学习(Self-Supervised Learning, SSL)是一种无监督学习的分支,旨在通过利用数据自身的结构和特征来生成标签,从而进行模型训练。与传统的监督学习方法依赖于大量标注数据的需求不同,自监督学习通过设计特定的任务,利用未标注数据中的信息创造出伪标签,使模型可以在没有人工标注的情况下进行学习。这一特性使得自监督学习在处理大规模未标注数据时展现出了独特的优势。
1.1 自监督学习的基本原理
自监督学习的核心在于通过创造性地设计学习任务,使得模型能够从数据中自动学习特征。这些任务通常基于数据的内在结构,目的是帮助模型理解数据的潜在规律。例如,模型可以通过以下几种方式来生成伪标签:
-
数据变换任务:对输入数据进行一定的变换或生成不同的视图,模型的目标是重建原始输入或识别变换的类型。例如,在图像数据中,图像旋转、裁剪或翻转等操作都可以被视为自监督任务,模型需要学习如何恢复或识别这些变换。
-
上下文预测任务:模型通过预测输入数据的某个部分或上下文来学习数据的结构。例如,在文本数据中,模型可以通过掩码某些单词并预测它们来学习语言结构。
-
对比学习:通过对比不同样本之间的相似性和差异性,模型可以学习到有用的表示。例如,在图像领域,可以将同一图像的不同增强版本视为正样本,而不同图像视为负样本,通过对比学习来优化模型。
1.2 自监督学习的任务设计
自监督学习的任务设计是成功的关键。通过合理的任务设计,模型能够有效学习到数据的特征和规律。以下是常见的任务类型:
-
图像重建任务:模型通过将输入的图像进行局部遮挡或变换,训练模型重建原始图像。这种方法可以帮助模型学习到图像的空间结构和特征。例如,掩码自编码器(Masked Autoencoders)就是通过这种方式进行训练的。
-
语言模型任务:在自然语言处理中,常见的自监督任务是掩码语言模型任务(Masked Language Model),模型通过上下文预测被掩码的单词。这种方式使得模型在训练过程中学习到词语之间的关系和语义信息。
-
动量对比学习:在对比学习中,使用动量编码器来生成正样本,模型通过对比这些样本来优化特征表示。这样的设计可以提高模型的稳定性,并有效利用未标注数据。
1.3 自监督学习的优势
自监督学习具有多种显著的优势,这也是它近年来受到极大关注的原因之一:
-
减少标注数据的需求:标注数据的获取通常需要大量的时间和精力,而自监督学习能够利用未标注的数据进行训练,从根本上降低了对标注数据的依赖。
-
提高模型的泛化能力:通过在未标注数据上学习,模型能够捕捉到更丰富的特征表示,从而提高其在实际应用中的泛化能力。自监督学习的表示学习能力使得模型在不同任务之间具有良好的迁移性。
-
适应性强:自监督学习可以应用于各种类型的数据,包括图像、文本、音频等。无论是在计算机视觉还是自然语言处理领域,自监督学习都展现出了极大的适用性和灵活性。
1.4 自监督学习的应用前景
自监督学习不仅在学术界引起了广泛关注,也在工业界得到了应用。随着大规模未标注数据的普及,自监督学习在许多领域中展现出巨大的潜力。以下是一些具体的应用前景:
-
计算机视觉:在计算机视觉领域,自监督学习被广泛应用于图像分类、目标检测和图像生成等任务。通过自监督学习,模型可以从海量未标注的图像中学习到有效的特征表示。
-
自然语言处理:自监督学习在自然语言处理中也取得了显著进展,特别是在语言模型的训练上。模型如BERT和GPT等都利用自监督学习的思想在各类NLP任务中表现出色。
-
音频处理:在音频处理领域,自监督学习可以用于语音识别、音乐生成等任务,通过学习未标注的音频数据来提升模型性能。
综上所述,自监督学习是一种强大且灵活的学习方法,通过利用未标注数据生成伪标签,帮助模型学习到丰富的特征表示。随着技术的不断发展,自监督学习将在未来的人工智能应用中扮演越来越重要的角色。
二、自监督学习的主要方法
自监督学习(Self-Supervised Learning, SSL)拥有多种有效的方法,可以帮助模型从未标注的数据中学习有用的特征表示。以下是一些主要的自监督学习方法及其具体实现方式:
2.1 对比学习(Contrastive Learning)
对比学习是一种通过比较样本之间的相似性和差异性来学习特征表示的方法,其基本思想是将相似样本(正样本)之间的距离拉近,而将不相似样本(负样本)之间的距离拉远。这种方法通常涉及到以下几个关键步骤:
-
样本生成:首先,从训练集中的每个样本生成多个增强视图。这些增强操作可以包括随机裁剪、颜色变换、旋转等。
-
特征提取:将这些增强后的样本输入到神经网络(如卷积神经网络)中,提取出特征表示。
-
相似度计算:使用某种相似度度量(例如余弦相似度)计算正样本和负样本之间的相似度。
-
损失函数:通过对比损失函数(如NT-Xent损失函数)来优化模型,使得正样本的相似度尽量高,而负样本的相似度尽量低。
实际案例:SimCLR
SimCLR(Simple Framework for Contrastive Learning of Visual Representations)是谷歌提出的一种对比学习方法。SimCLR的训练过程包括以下几个步骤:
-
数据增强:对输入图像进行多种数据增强,例如随机裁剪、颜色抖动、图像旋转等,生成多个视图。
-
特征提取:将每个增强后的图像输入到一个基础网络(如ResNet)中,提取特征表示。
-
对比学习:计算所有样本特征之间的对比损失,以最大化正样本对之间的相似性,最小化负样本对之间的相似性。
SimCLR在多个图像分类任务中表现出色,证明了对比学习在无监督特征学习中的有效性。
2.2 生成模型(Generative Models)
生成模型是一种通过学习数据分布来生成新样本的方法。在自监督学习中,生成任务通常通过重建输入数据来进行训练。生成模型的常见类型包括生成对抗网络(GAN)、变分自编码器(VAE)等。
实际案例:DALL-E
DALL-E是OpenAI提出的一种文本到图像的生成模型,能够根据文本描述生成高质量的图像。该模型的训练过程可以视为一种自监督学习,主要步骤包括:
-
数据收集:收集大量带有文本描述的图像数据集。
-
模型训练:模型通过学习图像和文本之间的映射关系来生成新的图像。在训练过程中,模型会根据文本描述生成图像,并通过优化损失函数来提高生成图像的质量。
-
生成与评估:训练完成后,用户可以输入文本描述,DALL-E便能生成对应的图像。模型的生成效果通常会结合人类评估来进行优化。
DALL-E的成功展示了生成模型在自监督学习中的应用潜力,特别是在创意生成和多模态学习方面。
2.3 任务重构(Task Reconstruction)
任务重构方法是通过对输入数据进行变换,要求模型恢复原始数据的过程。典型的任务重构方法包括图像重建、文本填空等。通过这种方式,模型能够学习数据的内在结构和特征。
实际案例:BERT
BERT(Bidirectional Encoder Representations from Transformers)是自然语言处理领域的一种重要模型,其自监督学习的关键在于“掩码语言模型”(Masked Language Model)任务。具体步骤如下:
-
掩码处理:在输入文本中随机选择一部分单词进行掩码,形成部分失真的文本。
-
预测任务:模型的目标是根据上下文预测被掩码的单词。通过训练,模型学习到单词在上下文中的语义信息。
-
训练与优化:使用交叉熵损失函数,通过反向传播更新模型参数,使得模型能够准确预测被掩码的单词。
BERT的掩码语言模型任务极大地提升了模型对上下文的理解能力,推动了自然语言处理领域的多项任务的进步。
2.4 变换学习(Transformation Learning)
变换学习是通过对输入数据施加特定变换,以学习模型对这些变换的理解能力。变换学习可以帮助模型更好地理解数据的几何结构和数据之间的关系。
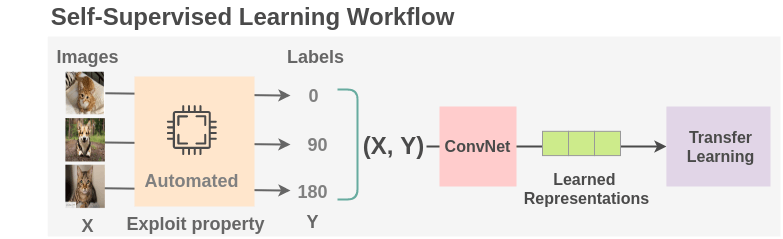
实际案例:旋转预测
旋转预测是一种自监督学习的任务,其中模型需要预测输入图像的旋转角度。具体过程如下:
-
图像变换:首先,随机旋转输入图像(如0度、90度、180度和270度),生成多个变换后的图像。
-
预测模型:训练一个分类器来预测图像的旋转角度。模型通过学习图像的特征来推断其旋转状态。
-
损失函数:使用交叉熵损失函数来优化模型,使其能够准确预测旋转角度。
这种变换学习方法不仅能够提高模型对图像的认知能力,还能够增强其对图像几何特征的理解。
2.5 其他自监督学习方法
除了上述主要方法,自监督学习还有许多其他的策略和方法,包括:
-
自回归模型:通过生成下一个数据点来学习序列数据的表示,例如语言模型(如GPT系列)通过预测下一个单词进行训练。
-
图像分割任务:在计算机视觉中,模型可以通过对图像进行分割的方式(如实例分割)来学习物体的边界特征和上下文信息。
-
图像掩码重建:在图像中随机选择一部分区域进行掩码,训练模型重建这些掩码区域,从而学习到图像的全局和局部特征。
自监督学习方法的多样性使其在各个领域的应用中大放异彩。通过对比学习、生成模型、任务重构等多种策略,模型能够有效地从未标注数据中提取有用的特征表示。这些方法不仅降低了对标注数据的依赖,还推动了众多实际应用的进展。随着技术的不断发展,自监督学习将在未来的人工智能领域中扮演越来越重要的角色。
三、自监督学习的应用场景
自监督学习的广泛应用使得它成为许多前沿研究的重要方向。以下是一些具体的应用场景:
3.1 计算机视觉
在计算机视觉领域,自监督学习被广泛应用于图像分类、目标检测和图像分割等任务。通过自监督学习,模型能够从大量未标注的图像中提取特征,从而提升下游任务的性能。例如,使用SimCLR进行图像分类任务时,模型能够在没有标签的情况下实现高准确率。
3.2 自然语言处理
在自然语言处理领域,自监督学习的方法被应用于文本理解、情感分析、机器翻译等任务。以BERT为例,通过学习上下文信息,BERT在多项自然语言处理任务上取得了显著的性能提升,推动了NLP领域的快速发展。
3.3 语音处理
自监督学习在语音识别和自然语言处理中的应用也愈加普遍。通过对未标注的音频进行特征学习,模型能够有效识别和处理语音信息。例如,Wav2Vec是一种自监督学习框架,能够在大量未标注音频上进行训练,从而提升语音识别的性能。
四、总结
自监督学习作为一种有效的学习范式,正逐渐成为深度学习研究的热点。通过利用未标注数据生成伪标签,自监督学习能够在各种任务中发挥重要作用。在计算机视觉、自然语言处理和语音处理等领域,自监督学习已展现出其强大的适用性和性能优势。

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









