







参考:http://blog.csdn.net/wangjian1204/article/details/50498287
一、概述:
基于内容的推荐系统(CBRSs)从item和用户的内容描述中提取出item的内容特征和用户偏好,根据用户对item的评价历史和item之间的语义(内容)相似度进行推荐。
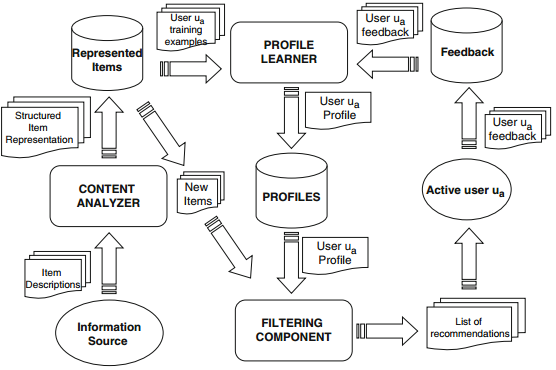
基于内容推荐系统的高层次结构如图所示,主要包括三部分内容(图中圆角矩形):Content Analyzer(内容分析),从无结构化的数据(如文本)中抽取出结构化数据(如词向量表示);Profile Learning(用户信息学习),从用户对item的评价历史中学习用户的偏好模型;Filtering Component(过滤组件),通过匹配用户偏好和item属性为用户推荐item。
二、关键词向量空间模型:
把一个文档集合(语料)用向量空间模型(Vector Space Model,简称VSM)进行表示,首先需要构造字典集合 T={t1,...tn} ,这是通过对语料中的文档进行分词、去停用词等操作后得到的关键词集合。有了词典,语料中的每一篇文档 dj 就可以表示成关键词向量的形式: [w1j,...,wnj] , wij 对应文档 dj 中单词 ti 的权重。接下来要解决的两个问题就是选择哪种权重计算方法以及相似度的度量方式。
TF-IDF(Term Frequency- Inverse Document Frequency)是最常用的权重机制之一,其计算公式如下:
fkj 是文档 dj 中单词 tk 出现的频次, N 是语料中文档数量, nk 是包含 tk 的语料数量。IDF项减弱了平凡单词的权重。通常会对TF-IDF做归一化处理得到关键词权重向量:
语料中的文档都表示成关键词向量以后,就可以用这个权重向量来度量文档之间的相似度了,cosine相似度是常用的一种度量方法:
另外需要注意的是,通常一个语料中的文档数量很多(百万甚至上亿),词典单词的数量也很多(数万或者更多),所以直接保存文档关键词向量的每一维会占用很大空间,一般采用稀疏的表示方法来保存数据和进行计算。
三、用户信息学习:
用户信息的学习可以看做一个简单的文本分类问题:对每一个用户,把文本分成用户感兴趣和不感兴趣两类。也可以把用户信息的学习看做一个多分类问题或者回归问题。
概率模型:
朴素贝叶斯通过先验和似然估计分类的后验概率:
由于对于所有的 cj , p(d) 都相同,所以这一项可以省略。 p(d|cj) 比较难得到,因为在同一个类里很难找到两篇文章是相同的。朴素贝叶斯假设同一篇文档内的单词相互之间是独立的,基于这个假设,可以得到:
N(di,tk) 是文档 dj 中单词 tk 出现的次数。
总体上来说朴素贝叶斯的分类效果并不是很好,但是朴素贝叶斯计算高效且容易实现,并且在某些情况下可以得到很好的结果,所以有比较广泛的应用。
相关性反馈:
Relevance feedback(相关性反馈)是一种在之前的搜索结果中增量调整查询的方法。例如让用户对推荐系统推荐的文档评分,然后推荐系统根据用户反馈调整用户偏好信息,例如Rocchino方法[2]。
k近邻:
给定一个新的文档,k近邻算法根据新文档的k近邻的类别信息对新文档进行分类。k近邻算法需要一个相似性函数来度量文档之间的近邻关系,例如前文提到的VSM的cosine相似度。k近邻算法的一大缺点是在分类阶段效率较低,因为需要在整个语料中寻找新文档的k个近邻。
四、基于内容的推荐系统优缺点:
和协同过滤算法相比,基于内容的推荐系统具有以下几个优点:
- 用户独立。基于内容的推荐系统不需要用户的近邻信息,而协同过滤方法根据相似用户的喜好进行推荐,被推荐的item只可能是近邻用户评价过的item,局限性较大。
- 可解释性。可以列出内容的特征或描述对推荐item进行解释,推荐结果更容易得到用户的信任。
- 新的item。基于内容的推荐系统可以对未被用户评分过的item进行推荐。
基于内容的推荐系统的缺点如下:
- 内容分析有限。基于内容的推荐系统受到特征数量和类型的限制。并且需要较多的领域知识,如电影推荐中需要知道电影的导演、演员、类型等信息。如果不能得到足够的信息(如笑话和诗歌),推荐效果会比较差。此外,一词多义、同义词、实体链接等也给推荐增加了难度。
- 推荐内容过分一致。基于内容的推荐系统根据用户的评分历史进行推荐,推荐的item可能与用户已评分item太过相似,缺少了新颖性。
- 新的用户。当一个新用户只对很少几个item进行过评分,基于内容的推荐系统很难给出可靠的推荐。
五、参考资料
[1]Recommender Systems Handbook
[2]Rocchino方法:Relevance Feedback Information Retrieval















 8125
8125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









