







目录
博主介绍:
计算机科班人,全栈工程师,掌握C、C#、Java、Python、Android等主流编程语言,同时也熟练掌握mysql、oracle、sqlserver等主流数据库,能够为大家提供全方位的技术支持和交流。
目前工作五年,具有丰富的项目经验和开发技能。提供相关的学习资料、程序开发、技术解答、代码讲解、文档报告等专业服务。
🍅文末获取源码🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到我哟
《精品项目实战》
Python的图像识别已经有一些第三方库可以使用,但是本文将详细介绍使用Python对图像验证码进行识别训练,以及我们对训练后的model的一个使用。
首先我们需要准备一些验证码图片并把图片命名为具体的验证码结果,我会将这些素材和源码一同打包,感兴趣的可以下载。
1、验证码识别原理
机器学习是人工智能的一个子集,它是利用统计技术提供了向计算机“学习”数据的能力,而不需要复杂的编程。简单来说,机器学习可以被定义为一种科学,它使计算机像人类一样行动和学习,并通过以实际交互和观察的形式向他们提供信息和数据,以独立的方式提高他们的学习能力。
1.1 Tensorflow 介绍
tensorflow 是由谷歌开发,使用比较广泛的深度学习框架,主要用来深度学习(机器学习也用)以及其他涉及大量运算,也是 Github 上最受欢迎的深度学习;tensorflow 在图像分类、音频处理,推荐系统和自然语言处理等领域应用十分广泛,谷歌几乎涉及深度学习或者机器学习的项目,都在使用 tensorflow作为运算框架;tensorflow 之所以能收到广大开发者的青睐,离不开 tensorflow底层优秀的封装,让开发人员能在不了解底层原理的情况下快速上手并且能直接开发。
1.2 Tensorflow 运行原理
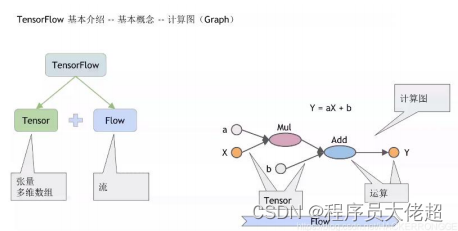
1.3 卷积神经网络 CNN(Convolutional Neural Networks)
CNN 是一种常用于图像识别、语音识别等领域的深度学习模型。CNN 是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。CNN 是由输入层、卷积层(convolutional layer)、池化层(pooling layer,也称为去样层)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层再连接一个卷积层,以此类推。与其他深度学习结构相比,卷积神经网路在图像和语音识别方面具有很强的优势。

(1) 卷积层: 通过卷积操作来提取图像特征
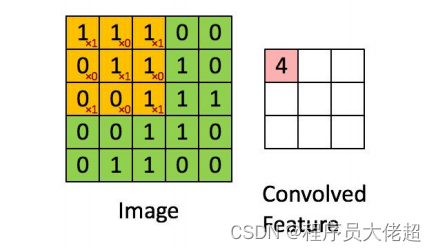
通过过滤器(卷积核)来过滤图像各个小区域,从而得到小区域的特征值。
(2)池化层: 下采样,数据降维,防止过拟合
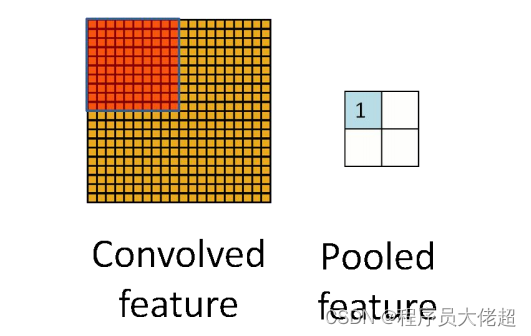
可以从上图中看到,原始图片 20x20 的,对其进行下采样,采样的窗口为10x10,最终将其下采样称为一个 2x2 大小的特征图。这么做的主要目的是因为有时候及时做完卷积,图像任然很大(由于卷积核比较小),为了降低数据维度,就进行了下采样。
总结:池化层相比卷积层可以更有效的降低数据维度,这么做不但可以大大减少运算量,还可以有效的避免过拟合。
(3)全连接层: 输出结果
经过卷积层和池化层处理过后的数据输入到全连接层,得到最终想要的结果。经过卷积层和池化层降维过的数据,全连接层才能“跑得动”。
2、验证码识别实现步骤
环境:Windows 10
开发工具: PyCharm
2.1 安装第三方模块
2.1.1 安装 TensorFlow 模块
根据 python 版本选择合适的 TensorFlow 版本,可按如下版本匹配:
| Python | TensorFlow | CUDA |
|---|---|---|
| 3.6.3(64 位,TensorFlow 只支持 64 位) | tensorflow-gpu | 1.10.0 9.0 |
# 普通的模块安装:
pip install tensorflow-gpu
# 使用镜像地址进行模块安装:
pip install tensorflow-gpu -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# 卸载模块:
pip uninstall tensorflow-gpu
# 指定模块版本进行安装:
pip install torch==1.6.0+cu101
# 使用以下下载好的 whl 进行安装:
pip install G:\whl\torch-1.6.0+cu101-cp36-cp36m-win_amd64.whl
2.2.2 安装 cuda
下载地址:https://developer.nvidia.com/cuda-toolkit-archive

安装完成运行 python 程序如果报如下错误:
ImportError: Could not find 'cudnn64_7.dll'. TensorFlow requires that this DLL be installed in a directory that is named in your
请继续下面的操作。
2.2.3 下载 cudnn
下载地址:https://developer.nvidia.com/rdp/cudnn-archive
选择合适的版本:
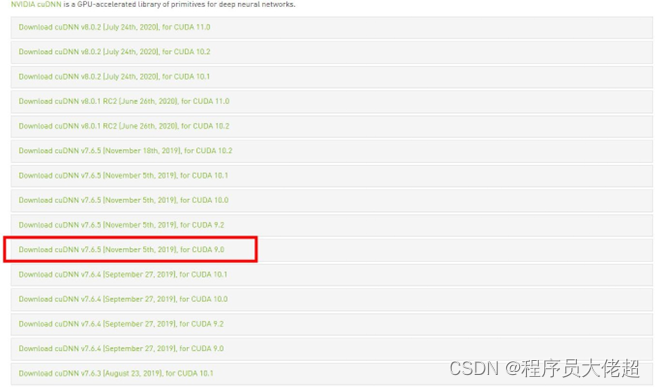
解压后把 bin\cudnn64_7.dll 文件拷贝到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin 目录下,运行程序,如果报错:ImportError: Matplotlib requires numpy>=1.15; you have 1.14.5,则升级 numpy。
2.2 读取验证码样本形成模型
2.2.1 图片进行预处理
一张原始的图片,并不一定每个点或者每个特征都是神经网络所必须 的。例如,一张彩色图片做文字识别,可能彩色的信息就不重要,但是为了存储颜色一般需要花费 3 倍的数据空间。或者在图像上有很多小小的噪音点, 这些点对图像的识别没有用处,反而有反效果。这种在正式处理运算之前对图像的操作,叫做图像数据的预处理。
灰度化:
将灰度图变为黑白图,黑白图上只有纯黑色和纯白色两种颜色。这种情况有助于过滤掉无关信息,而关注于主要的区域,或者图像区域的边界。
二值化:
二值化一般使用阈值法,即设置一个阈值,如果灰度大于阈值设为 255, 小于阈值设为 0,这时阈值的选择就成了关键。python 中二值化可以使用opencv 模块提供了threshold 方法对图片进行二值化,需要先安装 opencv 。
实现代码如下:
import os
import tensorflow as tf
import cv2
# 原始图片路径
img_path = 'F:\\train\\img\\'
# 灰度化的图片路径
gray_path = 'F:\\train\\gray\\'
def rgb_to_gray_scale():
# 读取immg下的图片
i = 0
for name in os.listdir(img_path):
i = i+1
if i > 500:
with tf.Session() as sess:
img = tf.read_file(img_path+name)
# 灰度化
img_data = tf.image.decode_jpeg(img, channels=3) # 解码
gray_img = sess.run(tf.image.rgb_to_grayscale(img_data.eval())) # 灰度化
# 二值化一般使用阈值法,即设置一个阈值
retval, im_at_fixed = cv2.threshold(gray_img, 185, 255, cv2.THRESH_BINARY)
cv2.imwrite(gray_path + name, im_at_fixed) # 保存图片
print("灰度化以及二值化完成")
rgb_to_gray_scale()
如下彩色图像
经过处理得到
2.2.2 使用预处理完成的图片训练生成模型
(1) 导入包并定于根据实际情况设置常量
import tensorflow as tf
import numpy as np
from PIL import Image
import os
import random
import cv2
train_data_dir = r'F:\train\gray' # 根据实际情况替换
test_data_dir = r'F:\train\img'
# 图片高度
IMAGE_HEIGHT = 23
# 图片宽度
IMAGE_WIDTH = 68
# 验证码的长度
MAX_CAPTCHA = 4
# 验证码字符集个数(如本次只有纯数字,所以字符集格式为10[0-9])
CHAR_SET_LEN = 10
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA * CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
(2) 灰度处理函数和标签处理函数
def conver2gray(img):
if len(img.shape)>2:
gray=np.mean(img,-1)
return gray
else:return img
def text2vec(text):
try:
text_len=len(text)
if text_len>MAX_CAPTCHA:
raise ValueError('longer than 4')
vector=np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
for i,c in enumerate(text):
idx=i*CHAR_SET_LEN+int(c) #[1,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0....]一共四十个元素 里面只有四个元素为1
vector[idx]=1
return vector
except Exception as e:
print(text)
(3) 获取验证码图片的缩影路径
#获取所有验证码图片
def _get_filenames_and_classes(dataset_dir):
photo_filenames = []
for filename in os.listdir(dataset_dir):
#获取文件路径
path = os.path.join(dataset_dir, filename)
photo_filenames.append(path)
return photo_filenames
(4) 由于 cnn 计算每次需要随机选择一批量的照片,所以需要批次提取照片函数
def gen_train_data(batch_size=32):
# 生成训练数据
train_file_name_list = os.listdir(train_data_dir)
selected_train_file_name_list = random.sample(train_file_name_list, batch_size)
batch_x=np.zeros([batch_size,IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y=np.zeros([batch_size,MAX_CAPTCHA*CHAR_SET_LEN])
i = 0
for selected_train_file_name in selected_train_file_name_list:
captcha_image = Image.open(os.path.join(train_data_dir, selected_train_file_name))
captcha_image = np.array(captcha_image)
image = conver2gray(captcha_image)
# 获取label
labels = selected_train_file_name.split('\\')[-1][0:4]
batch_x[i, :] = image.flatten() / 255
batch_y[i, :] = text2vec(labels)
i = i+1
return batch_x, batch_y
(5) cnn 训练算法
def cnn(w_alpha=0.01, b_alpha=0.1):
x=tf.reshape(X,shape=[-1,IMAGE_HEIGHT, IMAGE_WIDTH, 1])
w_c1=tf.Variable(w_alpha*tf.random_normal([3,3,1,32]))
b_c1=tf.Variable(b_alpha*tf.random_normal([32]))
conv1=tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x,w_c1,strides=[1,1,1,1],padding='SAME'),b_c1))
conv1=tf.nn.max_pool(conv1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2=tf.Variable(w_alpha*tf.random_normal([3,3,32,64]))
b_c2=tf.Variable(b_alpha*tf.random_normal([64]))
conv2=tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1,w_c2,strides=[1,1,1,1],padding='SAME'),b_c2))
conv2=tf.nn.max_pool(conv2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3=tf.Variable(w_alpha*tf.random_normal([3,3,64,64]))
b_c3=tf.Variable(b_alpha*tf.random_normal([64]))
conv3=tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2,w_c3,strides=[1,1,1,1],padding='SAME'),b_c3))
conv3=tf.nn.max_pool(conv3,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# 全连接层
w_d=tf.Variable(w_alpha*tf.random_normal([3*9*64, 1024]))
b_d=tf.Variable(w_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, shape=[-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
return out
(6) 训练函数
def train_cnn():
output = cnn()
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
step = 0
while True:
batch_x, batch_y = gen_train_data(64)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
print('step+loss', step, loss_)
# 每100 step计算一次准确率
if step % 10 == 0:
batch_x_test, batch_y_test = gen_train_data(100)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print('step+acc', step, acc)
# 如果准确率大于50%,保存模型,完成训练
if loss_ < 0.0001:
saver.save(sess, "./model/crack_capcha.model", global_step=step)
break
step += 1
执行训练
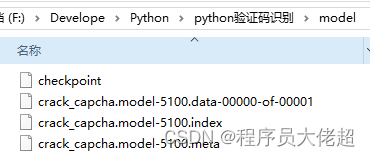
最终生成了我们需要的model,如下
3、使用训练出来的模型进行验证码识别
这里分别利用Python 的Django框架和.net 分别创建项目来进行调用,源码也一同打包,感兴趣的下载。
3.1 Django项目
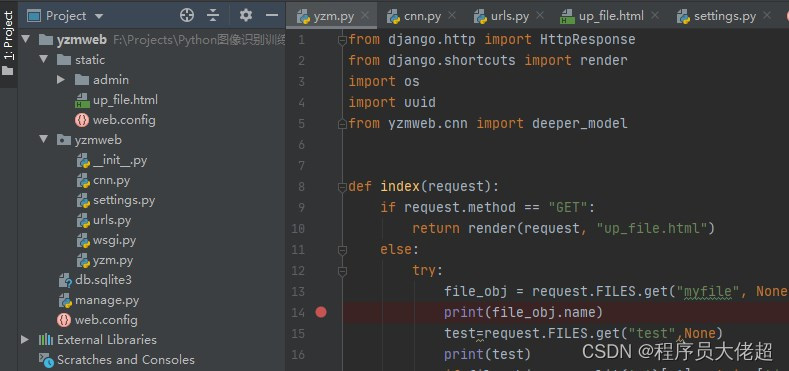
yzm.py
from django.http import HttpResponse
from django.shortcuts import render
import os
import uuid
from yzmweb.cnn import deeper_model
def index(request):
if request.method == "GET":
return render(request, "up_file.html")
else:
try:
file_obj = request.FILES.get("myfile", None)
print(file_obj.name)
test=request.FILES.get("test",None)
print(test)
if file_obj.name.split('.')[-1] not in ['jpeg', 'jpg', 'png']:
return HttpResponse('输入文件有误')
if not file_obj:
return HttpResponse("no files for upload")
file_id = uuid.uuid1()
name = file_obj.name
file_name = os.path.join("D:\\train\\upload", str(file_id)+'-'+name)
print(file_name)
with open(file_name, 'wb+') as f:
f.write(file_obj.read())
cnn_model = deeper_model() # 实例化
str22 = cnn_model.predict(file_name) # 调用模型,输出识别结果
return HttpResponse(str22)
except Exception as e:
print(e)
return HttpResponse("upload error!")
up_file.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form enctype="multipart/form-data" method="post">
<input type="file" name="myfile" id="avatar_file" />
<br/>
<input type="submit" value="upload">
{% csrf_token %}
</form>
</body>
</html>
启动项目
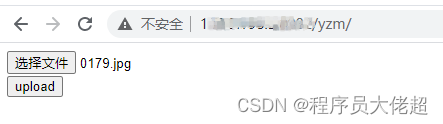
获取验证码接口:http://ip:端口/yzm/,如果请求方式为GET,弹出如下页面使用。
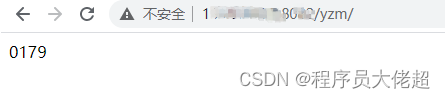
识别结果如下
3.2 .net项目

注:如果你的服务器使用CPU来处理图像,CPU和GPU图像处理能力有差别,所以如果连续快速识别可能会出现异常。
4、源码及素材下载地址
下载地址:https://download.csdn.net/download/xch_yang/89306923
技术交流
大家点赞、收藏、关注、评论啦!
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
《精品项目实战》
更多技术干货,请持续关注程序员大佬超。
原创不易,转载请务必注明出处。

















 4630
4630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











