







本地缓存(cookie、session、localStrorage、sessionStrorage)
cookie
保存方式:cookie保存在浏览器端
生命周期:如果不在浏览器中设置过期时间,cookie被保存在内存中,生命周期随浏览器的关闭而结束,这种cookie简称会话cookie。如果在浏览器中设置了cookie的过期时间,cookie被保存在硬盘中,关闭浏览器后,cookie数据仍然存在,直到过期时间结束才消失。
作用:用来跟踪浏览器用户身份的会话方式
版本:HTML4本地存储
存储的大小:单个cookie保存的数据不能超过4kb
应用场景:
(1)判断用户是否登陆过网站,以便下次登录时能够实现自动登录(或者记住密码)。如果我们删除cookie,则每次登录必须从新填写登录的相关信息。
(2)保存上次登录的时间等信息。
(3)保存上次查看的页面
(4)浏览计数
存储内容:只能保存字符串类型,以文本的方式;
缺点:
(1)大小受限4KB
(2)用户可以操作(禁用)cookie,使功能受限
(3)安全性较低
(4)有些状态不可能保存在客户端。
(5)每次访问都要传送cookie给服务器,浪费带宽。
(6)cookie数据有路径(path)的概念,可以限制cookie只属于某个路径下。
session
保存方式:session保存在服务器端
生命周期:默认失效时间为20分钟(当没有被访问时才开始计算)
作用:用来跟踪浏览器用户身份的会话方式
版本:HTML4本地存储
存储的大小:大小没有限制。
应用场景:保存每个用户的专用信息,变量的值保存在服务器端,通过SessionID来区分不同的客户。
(1)网上商城中的购物车
(2)保存用户登录信息
(3)将某些数据放入session中,供同一用户的不同页面使用
(4)防止用户非法登录
存储内容:通过类似与Hashtable的数据结构来保存,能支持任何类型的对象(session中可含有多个对象)
缺点:
(1)Session保存的东西越多,就越占用服务器内存,对于用户在线人数较多的网站,服务器的内存压力会比较大。
(2)依赖于cookie(sessionID保存在cookie),如果禁用cookie,则要使用URL重写,不安全
i9 c vwesx
(3)创建Session变量有很大的随意性,可随时调用,不需要开发者做精确地处理,所以,过度使用session变量将会导致代码不可读而且不好维护。
localStorage
保存方式:将数据保存在客户端本地的硬件设备(通常指硬盘,也可以是其他硬件设备)中,即使浏览器被关闭了,该数据仍然存在,下次打开浏览器访问网站时仍然可以继续使用。(保存在客户端,不与服务器进行交互通信。)
生命周期:永久保存
作用:同cookie,session一样只不过是他们的一个升级版
版本:HTML5本地存储
存储大小:5MB
应用场景:常用于长期登录(+判断用户是否已登录),适合长期保存在本地的数据
存储内容:只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理
sessionStorage
保存方式:将数据保存在session对象中。所谓session,是指用户在浏览某个网站时,从进入网站到浏览器关闭所经过的这段时间,也就是用户浏览这个网站所花费的时间。session对象可以用来保存在这段时间内所要求保存的任何数据(保存在客户端,不与服务器进行交互通信。)
生命周期:临时保存
作用:同cookie,session一样只不过是他们的一个升级版
版本:HTML5本地存储
存储大小:5MB
应用场景:敏感账号一次性登录;
存储内容:只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理
区别
cookie的生命周期随浏览器关闭而关闭。sessionStrorage是临时保存。localStrorage永久保存。
cookie传输不安全,浪费带宽(客户端请求服务端的时候要带上cookie所以浪费带宽)
sessionStrorage与localStrorage不与服务器通信所以相当节省资源以及更安全
cookie传输只有4KB,有限制大小。而sessionStrorage与localStrorage是5MB更大一些。
cookie只能传输字符串文本形式。而sessionStrorage与localStrorage支持任何类型对象
强缓存和协商缓存
当浏览器去请求某个文件的时候,服务端就在respone header里面对该文件做了缓存配置。缓存的时间、缓存类型都是由服务端控制。具体表现为:
respone header 的cache-control,常见的设置是max-age public private no-cache no-store等
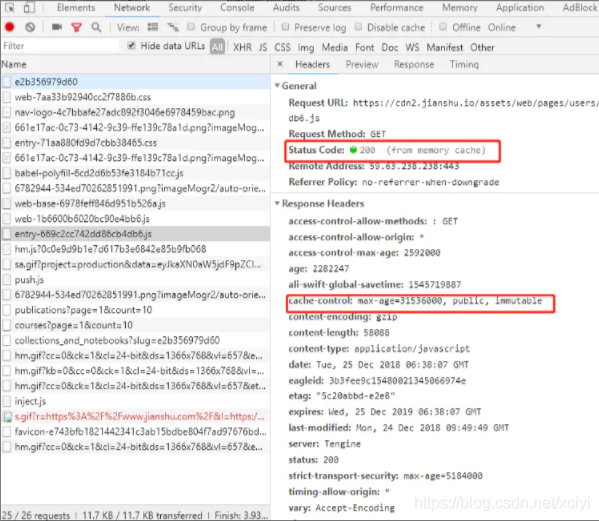
强缓存总结
-
cache-control: max-age=xxxx,public
客户端和代理服务器都可以缓存该资源;
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,如果用户做了刷新操作,就向服务器发起http请求 -
cache-control: max-age=xxxx,private
只让客户端可以缓存该资源;代理服务器不缓存
客户端在xxx秒内直接读取缓存,statu code:200 -
cache-control: max-age=xxxx,immutable
客户端在xxx秒的有效期内,如果有请求该资源的需求的话就直接读取缓存,statu code:200 ,即使用户做了刷新操作,也不向服务器发起http请求 -
cache-control: no-cache
跳过设置强缓存,但是不妨碍设置协商缓存;一般如果你做了强缓存,只有在强缓存失效了才走协商缓存的,设置了no-cache就不会走强缓存了,每次请求都回询问服务端。 -
cache-control: no-store
不缓存,这个会让客户端、服务器都不缓存,也就没有所谓的强缓存、协商缓存了。
强缓存就是为了给客户端自给自足用的
协商缓存
客户端请求该资源时发现其过期了,这是就会去请求服务器了,而这时候去请求服务器的这过程就可以设置协商缓存。这时候,协商缓存就是需要客户端和服务器两端进行交互的。
response header里面的设置
etag: '5c20abbd-e2e8'
last-modified: Mon, 24 Dec 2018 09:49:49 GMTetag:每个文件有一个,改动文件了就变了,就是个文件hash,每个文件唯一,就像用webpack打包的时候,每个资源都会有这个东西,如: app.js打包后变为 app.c20abbde.js,加个唯一hash,也是为了解决缓存问题。
last-modified:文件的修改时间,精确到秒
每次请求返回来 response header 中的 etag和 last-modified,在下次请求时在 request header 就把这两个带上,服务端把你带过来的标识进行对比,然后判断资源是否更改了,如果更改就直接返回新的资源,和更新对应的response header的标识etag、last-modified。如果资源没有变,那就不变etag、last-modified,这时候对客户端来说,每次请求都是要进行协商缓存了
协商缓存过程:发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->没过期-->返回304状态码-->客户端用缓存的老资源。
当然,当服务端发现资源真的过期的时候,会走如下流程:
发请求-->看资源是否过期-->过期-->请求服务器-->服务器对比资源是否真的过期-->过期-->返回200状态码-->客户端如第一次接收该资源一样,记下它的cache-control中的max-age、etag、last-modified等。
为什么要有etag?
HTTP1.1中etag的出现(也就是说,etag是新增的,为了解决之前只有If-Modified的缺点)主要是为了解决几个last-modified比较难解决的问题:
-
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新获取;
-
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),if-modified-since能检查到的粒度是秒级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
-
某些服务器不能精确的得到文件的最后修改时间。

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









