







Easy Excel
- 官网:https://easyexcel.opensource.alibaba.com/docs/current/
- 为什么要使用Easy Excel
使Java更好的操作excel
官方:
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便

- 怎么使用
两种读方式:
1.确定表头:建立对象,和表头形成映射关系
2.不确定表头:每一行数据映射为Map<String,Object>
先导入pom.xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.1</version>
</dependency>
创建一个对象(与excel中的行数据做个映射)
@Getter
@Setter
@EqualsAndHashCode
public class DemoData {
private String string;
private Date date;
private Double doubleData;
}
自定义监听器
@Slf4j
public class DemoDataListener implements ReadListener<DemoData> {
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(DemoData data, AnalysisContext context) {
System.out.println(data);
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
System.out.println("已解析完成");
}
}
创建excel文件(最好不要又中文路径)
读取数据
- 自定义监听器
public class ImportExcel {
public static void main(String[] args) {
String fileName = "D:\\demo.xlsx";
// 这里默认每次会读取100条数据 然后返回过来 直接调用使用数据就行
// 具体需要返回多少行可以在`PageReadListener`的构造函数设置
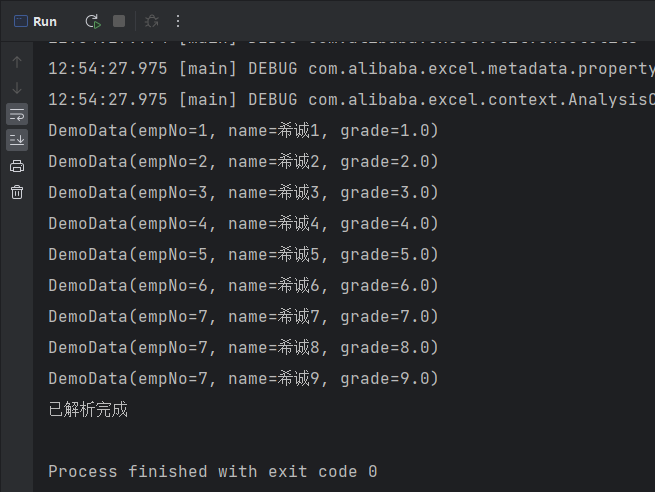
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
}
- 不创建监听器
public class ImportExcel {
public static void main(String[] args) {
String fileName = "D:\\demo.xlsx";
// 这里默认每次会读取100条数据 然后返回过来 直接调用使用数据就行
// 具体需要返回多少行可以在`PageReadListener`的构造函数设置
// EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
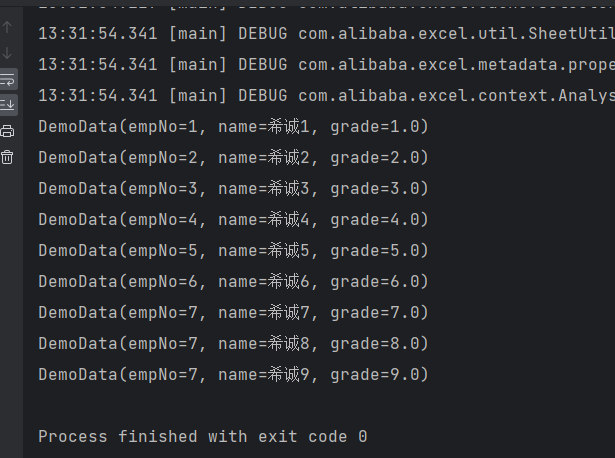
List<DemoData> lists = EasyExcel.read(fileName).head(DemoData.class).sheet().doReadSync();
for (DemoData list : lists) {
System.out.println(list);
}
}
}
- 监听器:先创建监听器、在读取文件时绑定监听器。单独抽离处理逻辑,代码清晰易于维护;一条一条处理,适用于数据量大的场景。
- 同步读:无需创建监听器,一次性获取完整数据。方便简单,但是数据量大时会有等待时常,也可能内存溢出。
测试项目导入数据
- 监听器
package com.xc.usercentor.once;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.util.ListUtils;
import com.xc.usercentor.model.domains.User;
import com.xc.usercentor.service.UserService;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
@Slf4j
public class DemoDataListener implements ReadListener<User> {
private UserService userService;
/**
* 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 10000;
public DemoDataListener(UserService userService) {
this.userService = userService;
}
/**
* 缓存的数据
*/
// private List<User> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
List<List<User>> lists = ListUtils.newArrayListWithExpectedSize(100);
List<User> list = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
/**
* 这个每一条数据解析都会来调用
*
* @param user one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(User user, AnalysisContext context) {
if (list.size() >= BATCH_COUNT) {
lists.add(new ArrayList<>(list));
list = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
list.add(user);
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData(lists);
log.info("所有数据解析完成!");
}
/**
* 加上存储数据库
*/
private void saveData(List<List<User>> lists) {
for(int i = 0; i < lists.size(); i++){
List<User> users = lists.get(i);
userService.saveBatch(users);
}
}
}
- 测试
@Test
void contextLoads() {
String fileName = "D:\\demo.xlsx";
// 写法1:JDK8+ ,不用额外写一个DemoDataListener
// since: 3.0.0-beta1
// 这里默认每次会读取100条数据 然后返回过来 直接调用使用数据就行
// 具体需要返回多少行可以在`PageReadListener`的构造函数设置
long start = System.currentTimeMillis();
EasyExcel.read(fileName, User.class, new DemoDataListener(userService)).sheet().doRead();
long end = System.currentTimeMillis();
System.out.println(end-start);
}
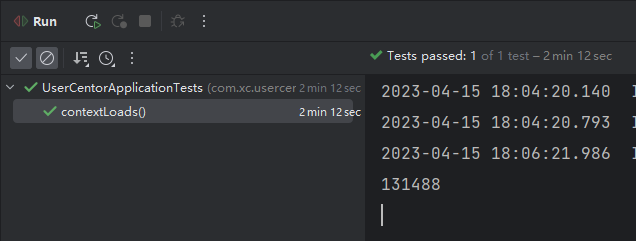
100w条数据导入数据库时间131秒
使用自定义线程池+CompletableFuture并发编程提高了导入数据库性能
- 监听器
package com.xc.usercentor.once;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.read.listener.ReadListener;
import com.alibaba.excel.util.ListUtils;
import com.xc.usercentor.model.domains.User;
import com.xc.usercentor.service.UserService;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
@Slf4j
public class DemoDataListener implements ReadListener<User> {
private UserService userService;
/**
* 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 10000;
public DemoDataListener(UserService userService) {
this.userService = userService;
}
/**
* 缓存的数据
*/
// private List<User> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
List<List<User>> lists = ListUtils.newArrayListWithExpectedSize(100);
List<User> list = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
/**
* 这个每一条数据解析都会来调用
*
* @param user one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(User user, AnalysisContext context) {
if (list.size() >= BATCH_COUNT) {
lists.add(new ArrayList<>(list));
list = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
list.add(user);
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 这里也要保存数据,确保最后遗留的数据也存储到数据库
saveData(lists);
log.info("所有数据解析完成!");
}
/**
* 加上存储数据库
*/
private void saveData(List<List<User>> lists) {
List<CompletableFuture<Void>> futureList = new ArrayList<>();
for(int i = 0; i < lists.size(); i++){
List<User> users = lists.get(i);
CompletableFuture<Void> future = CompletableFuture.runAsync(()->{
userService.saveBatch(users,10000);
});
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
}
}
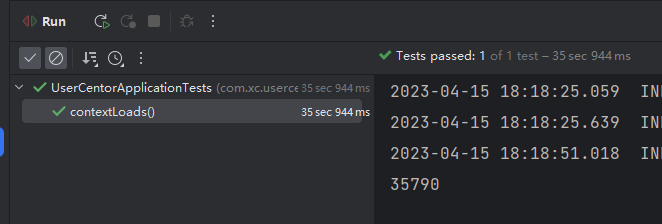
最后用时35秒
CompletableFuture<Void> future = CompletableFuture.runAsync(()->{
userService.saveBatch(users,10000);
});
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
}
}















 1275
1275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









