







总览学习目录篇 链接地址:https://blog.csdn.net/xczjy200888/article/details/124057616
B站:李宏毅2020机器学习笔记 5 —— 分类Classification和逻辑回归Logistic Regression
一、分类器介绍
1. 简介
输入→函数处理→哪个类别

2. 理想分类器

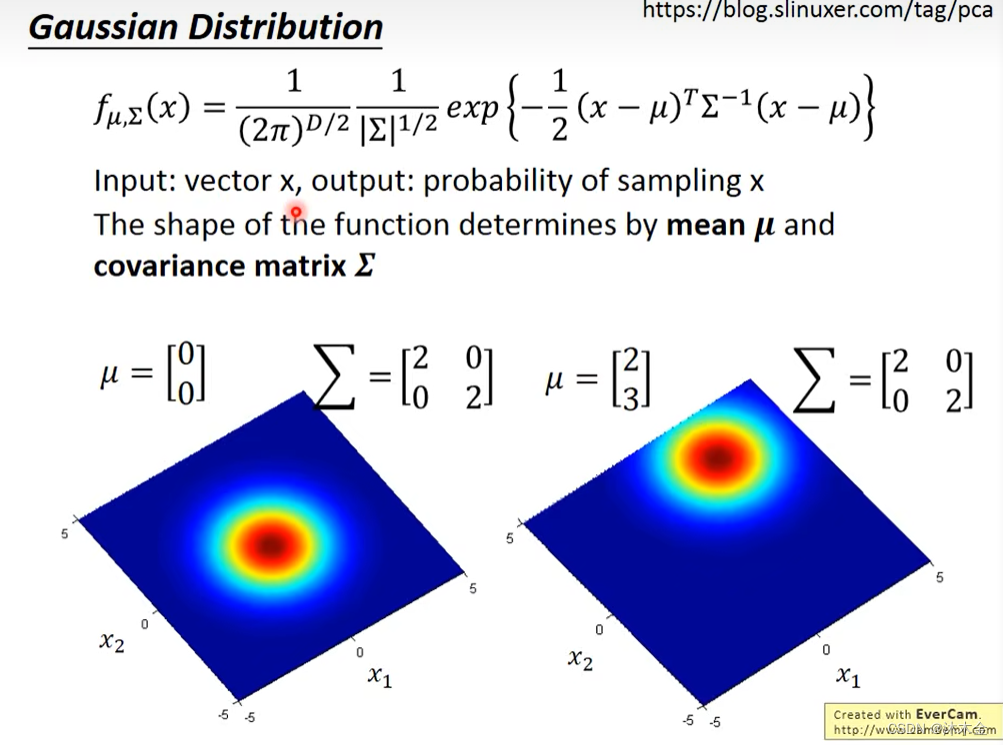
3. 高斯分布
- 输入:向量x
- 输出:x的抽样概率
- maximum likelihood 最大似然估计
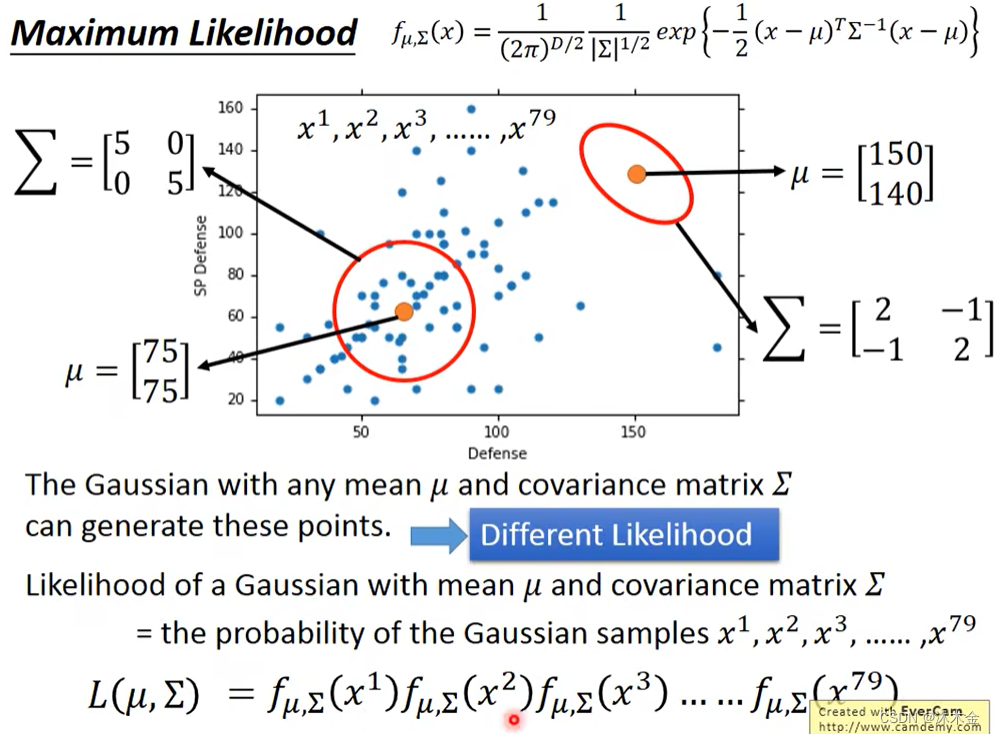
-
∑
\sum
∑表示协方差矩阵

二、概率模型的分类
1. 三个步骤

2. 概率分布选择
- 选择自己喜欢的概率分布
- 对于二元特征,可以使用伯努利分布(即0-1分布)
P ( x ) = p x ( 1 − p ) 1 − x = { p i f x = 1 1 − p i f x = 0 0 o t h e r w i s e P(x)=p^x(1-p)^{1-x}=\begin{cases} p & if x=1 \\ 1-p & if x=0 \\ 0 & otherwise \end{cases} P(x)=px(1−p)1−x=⎩ ⎨ ⎧p1−p0ifx=1ifx=0otherwise - 如果假设所有维度特征都是独立的,可以使用朴素贝叶斯分类器
P ( A ∣ B ) = P ( A B ) P ( B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B)=\frac{P(AB)}{P(B)}=\frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(AB)=P(B)P(B∣A)P(A)

3. 后验概率
- 计算过程只做了解即可




当
∑
1
\sum_1
∑1 =
∑
2
\sum_2
∑2 时,

三、逻辑回归
可回顾第一章的回归内容
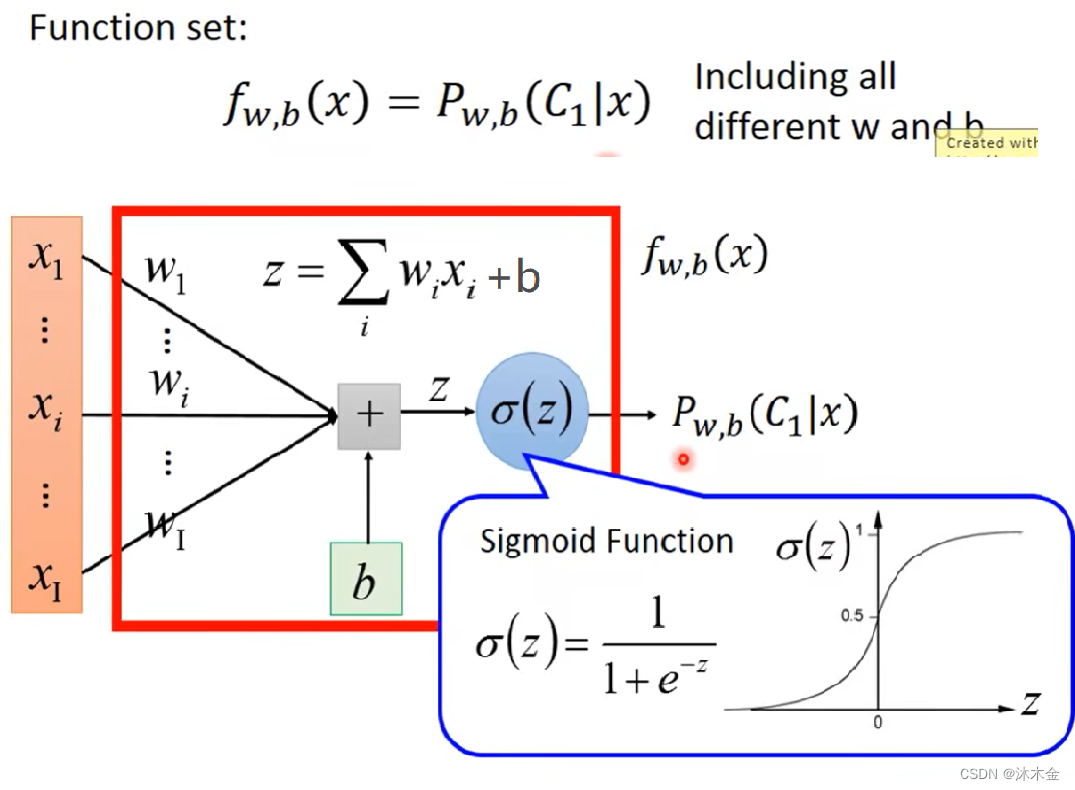
1. 步骤一:函数模型

2. 步骤二:判断函数模型好坏


上图,把
y
^
i
=
1
或者
0
代入,公式中部分项可消除
\hat{y}^i=1或者0代入,公式中部分项可消除
y^i=1或者0代入,公式中部分项可消除

3. 步骤三:寻找最好的函数模型
第一项的偏微分化简:

第二项的偏微分化简:
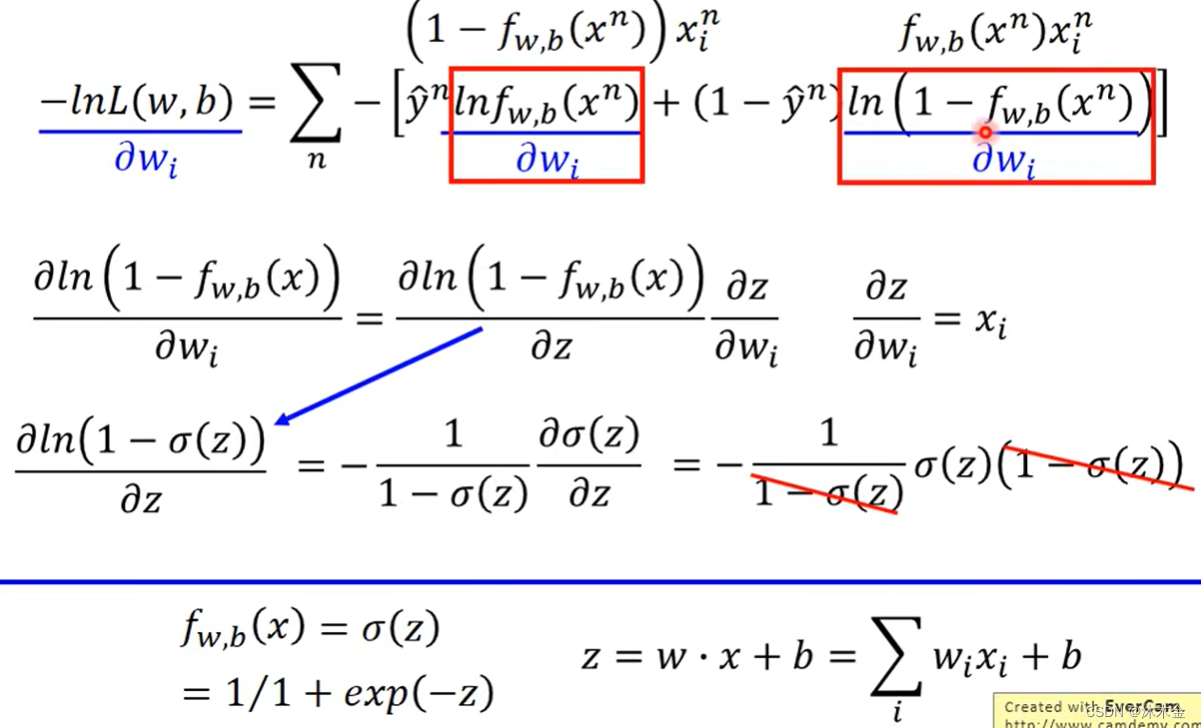
整理可得:

4. 逻辑回归vs线性回归
- 输出不同:逻辑回归为0或1,线性回归为任意值
- 损失函数不同:逻辑回归为概率交叉熵求和,线性回归为欧式距离
- 调优方式相同

四、其他思考
1. 逻辑回归+平方差

相较于交叉熵,使用平方差的缺点:
- 在预测值距离目标值较远时,交叉熵值比较大,便于更新优化。
- 在预测值距离目标值较近时,交叉熵值比较小,便于找到最优值。
- 在预测值距离目标值不论是近或远时,平方差都较小。
2. 判别式和生成式
判别式模型 (Discriminative Model) :直接对条件概率 P ( y ∣ x ) P(y|x) P(y∣x)进行建模,将最大的 P ( y ∣ x ) P(y|x) P(y∣x)作为新样本的分类。
- 常见判别模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 判别式模型更直接,目标性更强
- 判别式模型关注的数据的差异性,寻找的是分类面
生成式模型 (Generative Model) :对每个类型建立一个模型,计算每个类别的联合分布 P ( x , y ) P(x,y) P(x,y),根据贝叶斯公式,分别计算 P ( y ∣ x ) P(y|x) P(y∣x),选择三类中最大的 P ( y ∣ x ) P(y|x) P(y∣x)作为样本的分类。
- 常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
- 生成式模型关注数据是如何产生的,寻找的是数据分布模型
- 生成式模型更普适;
- 由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型

3. 多类别分类器
- 每个类别一个模型,将输入放入不同类别的模型,得到输出概率,并求每类概率的占比。
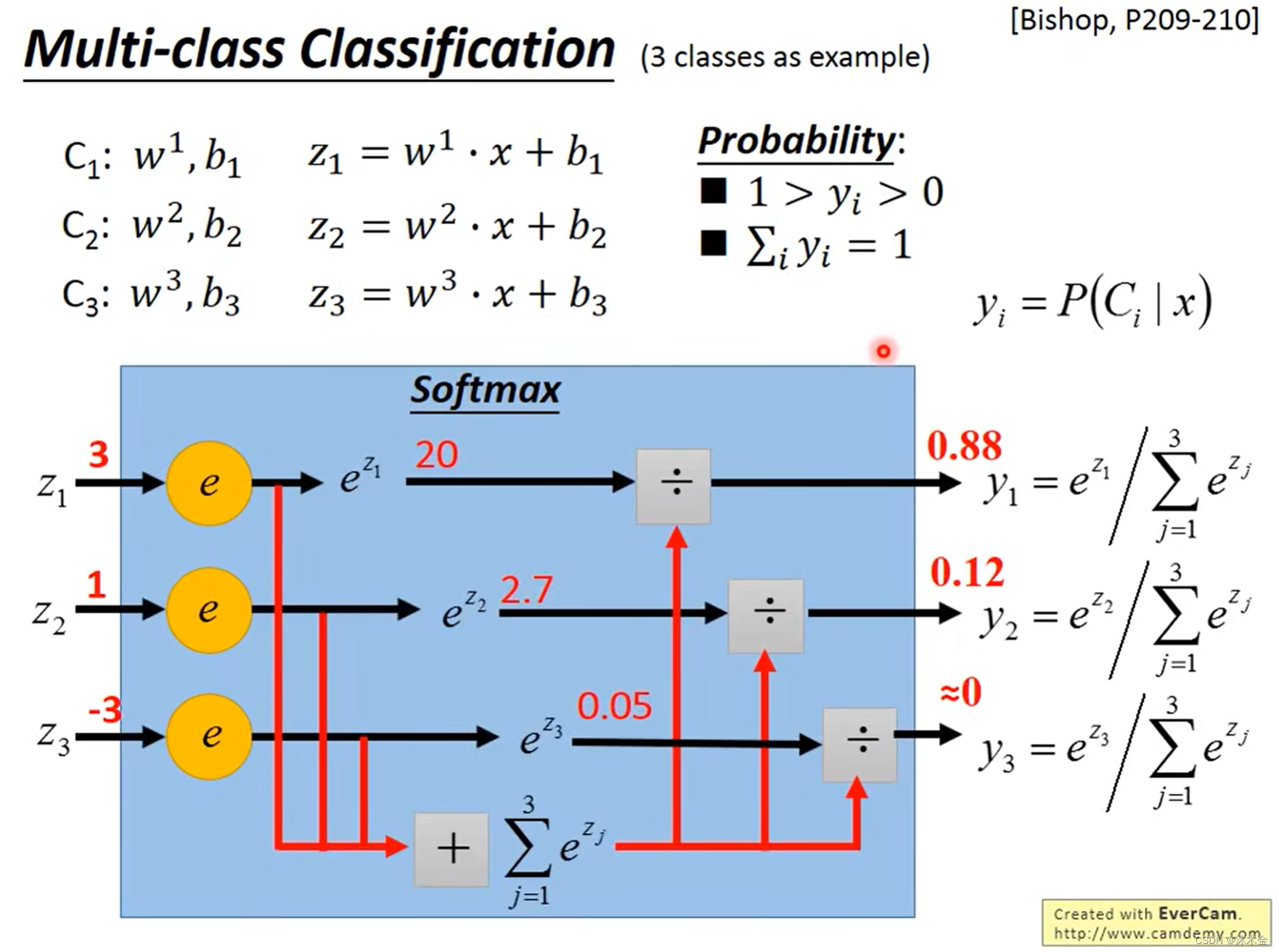
- 计算交叉熵,目标值设定(样本属于哪类,哪类为1,其余为0)
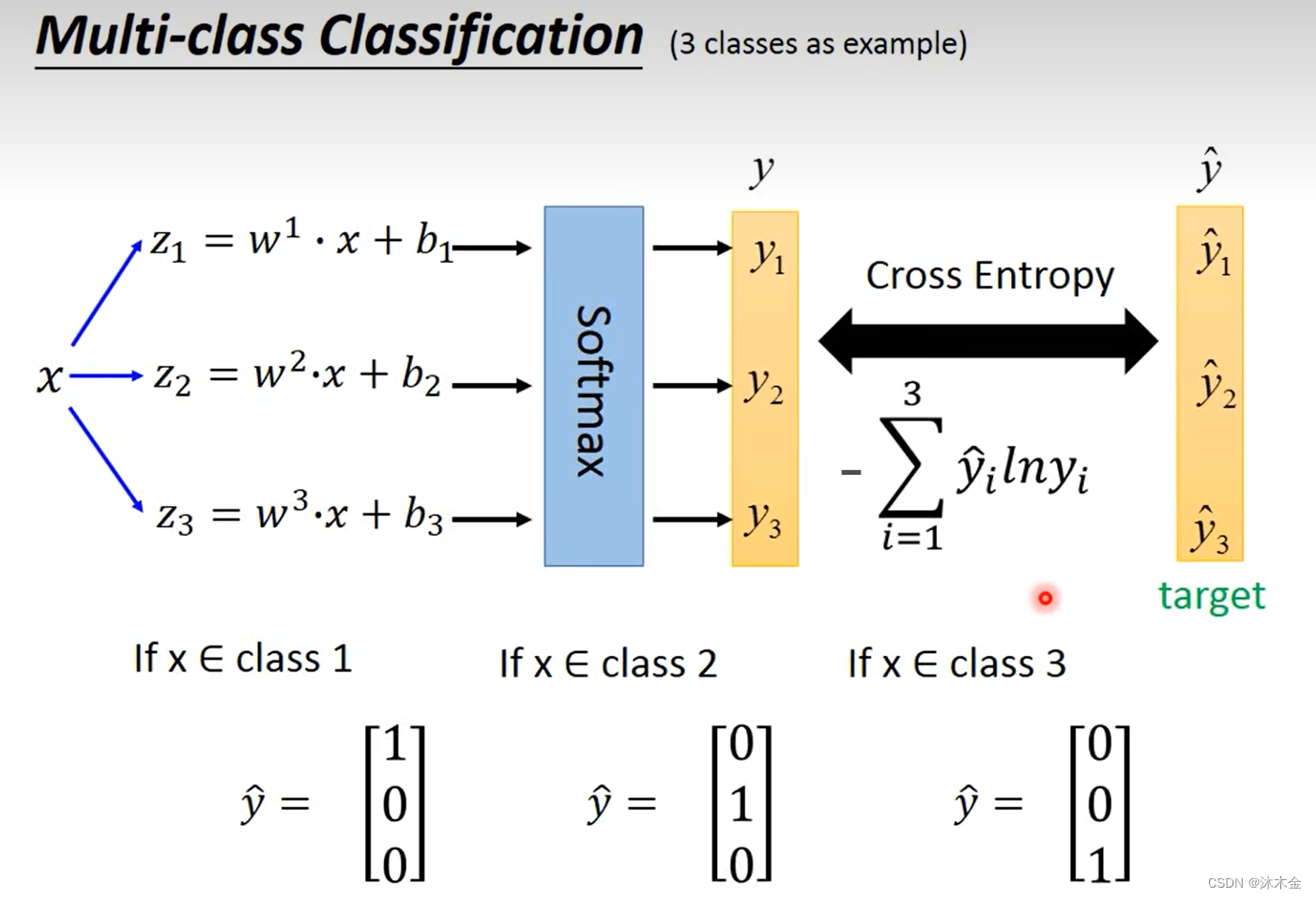
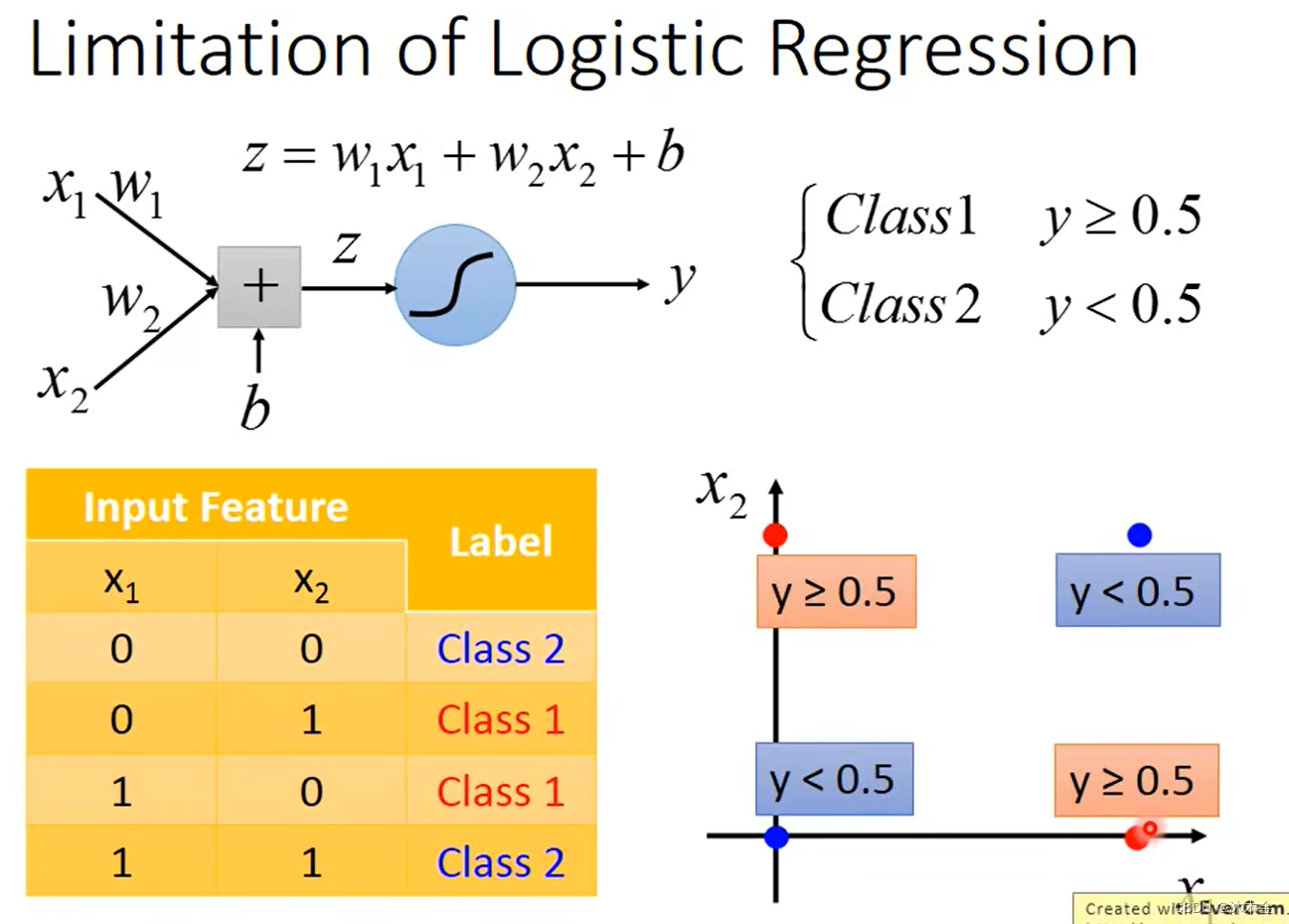
4. 逻辑回归的限制
-
逻辑回归无法区分class1和class2,因为逻辑回归是一种广义上的线性回归,只能在图上画一条直线,无法区分红色点和蓝色点。
-
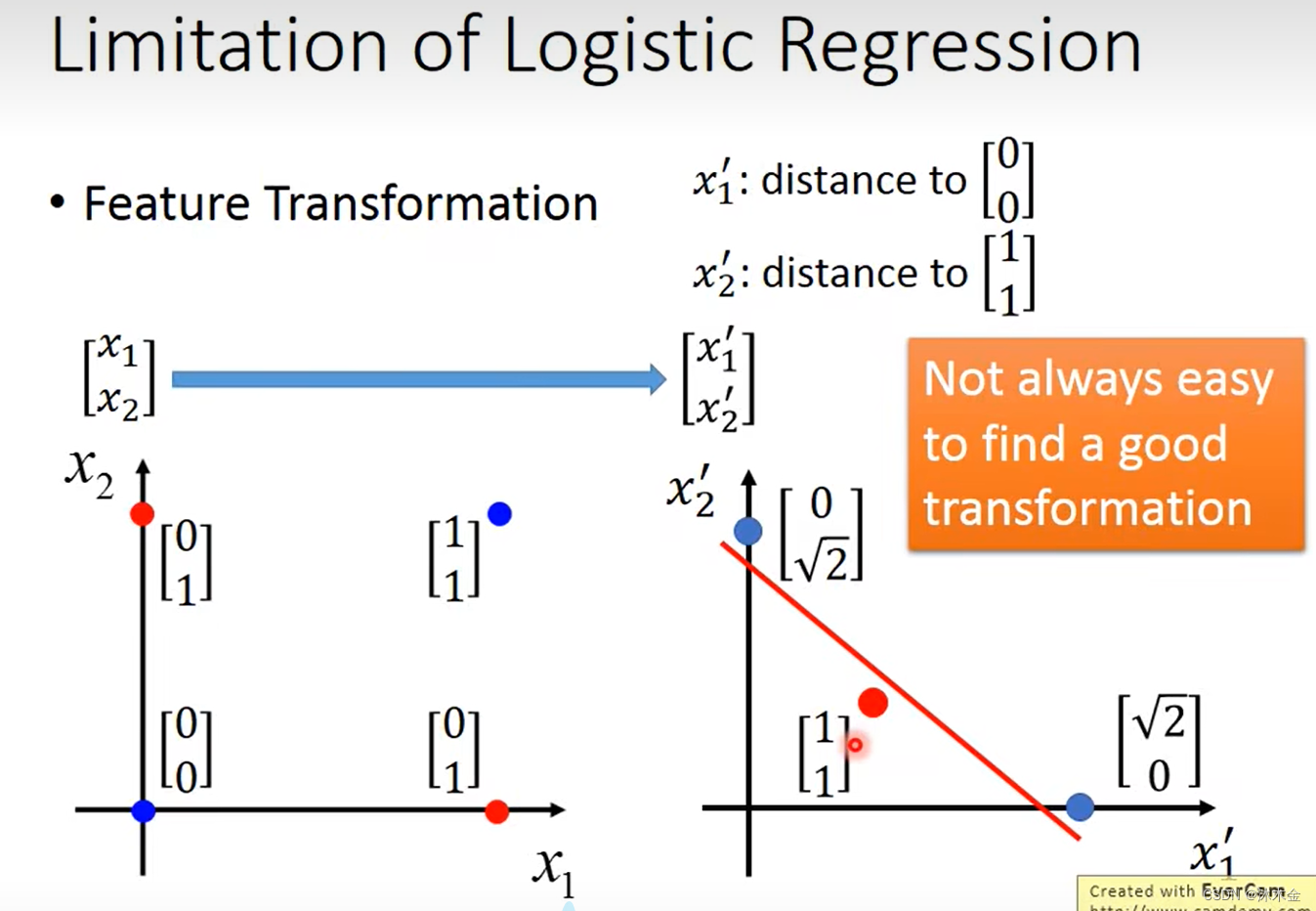
可以找一个转换函数,再使用逻辑回归。例如下图,分别计算属性x1的值为某个点到(0,0)的距离,属性x2为某个点到(1,1)的距离,就可以画出一条直线,进行红色点和蓝色点的区分。
-
但是要找到一个转换函数没有那么简单。所以要向,这个转换怎么让机器自己产生?
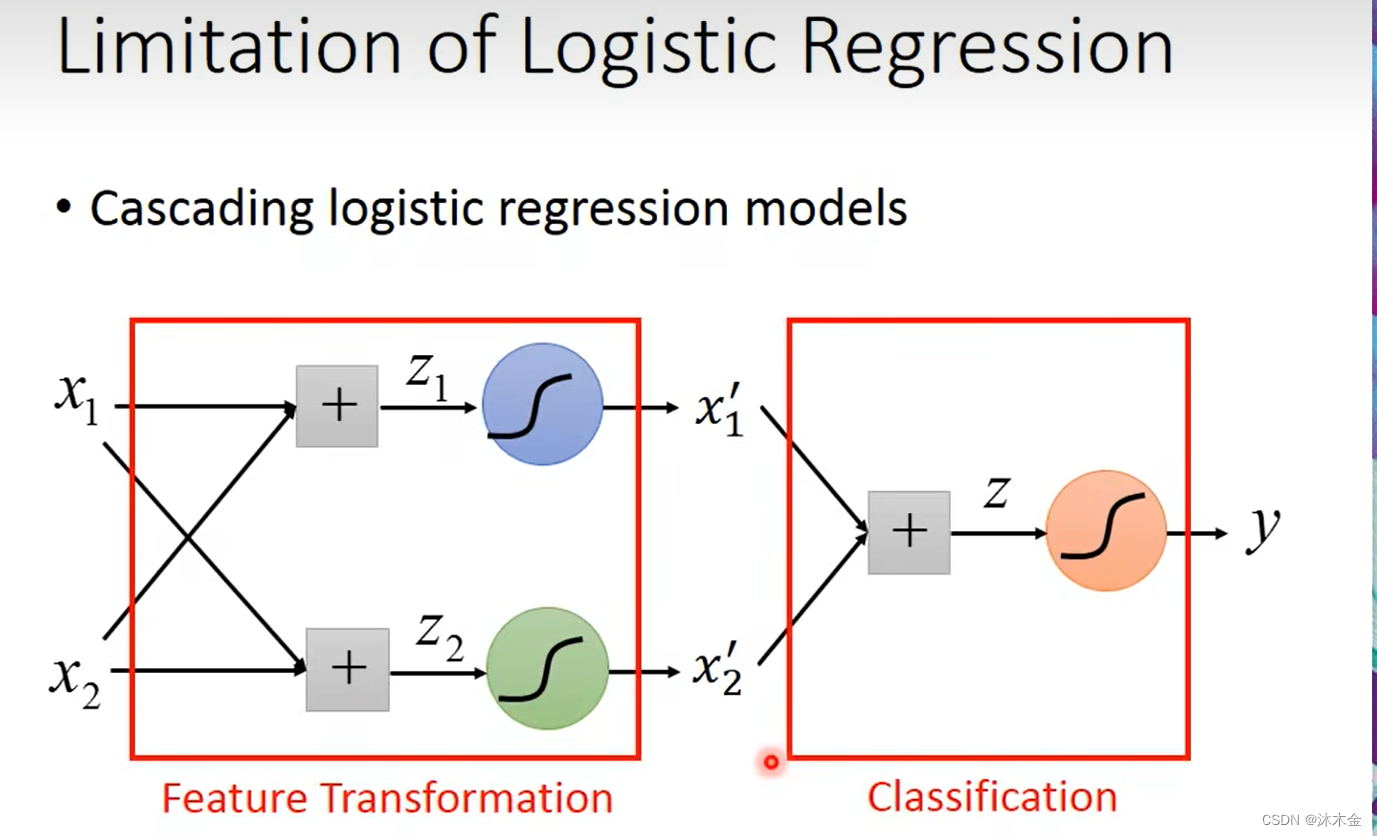
-
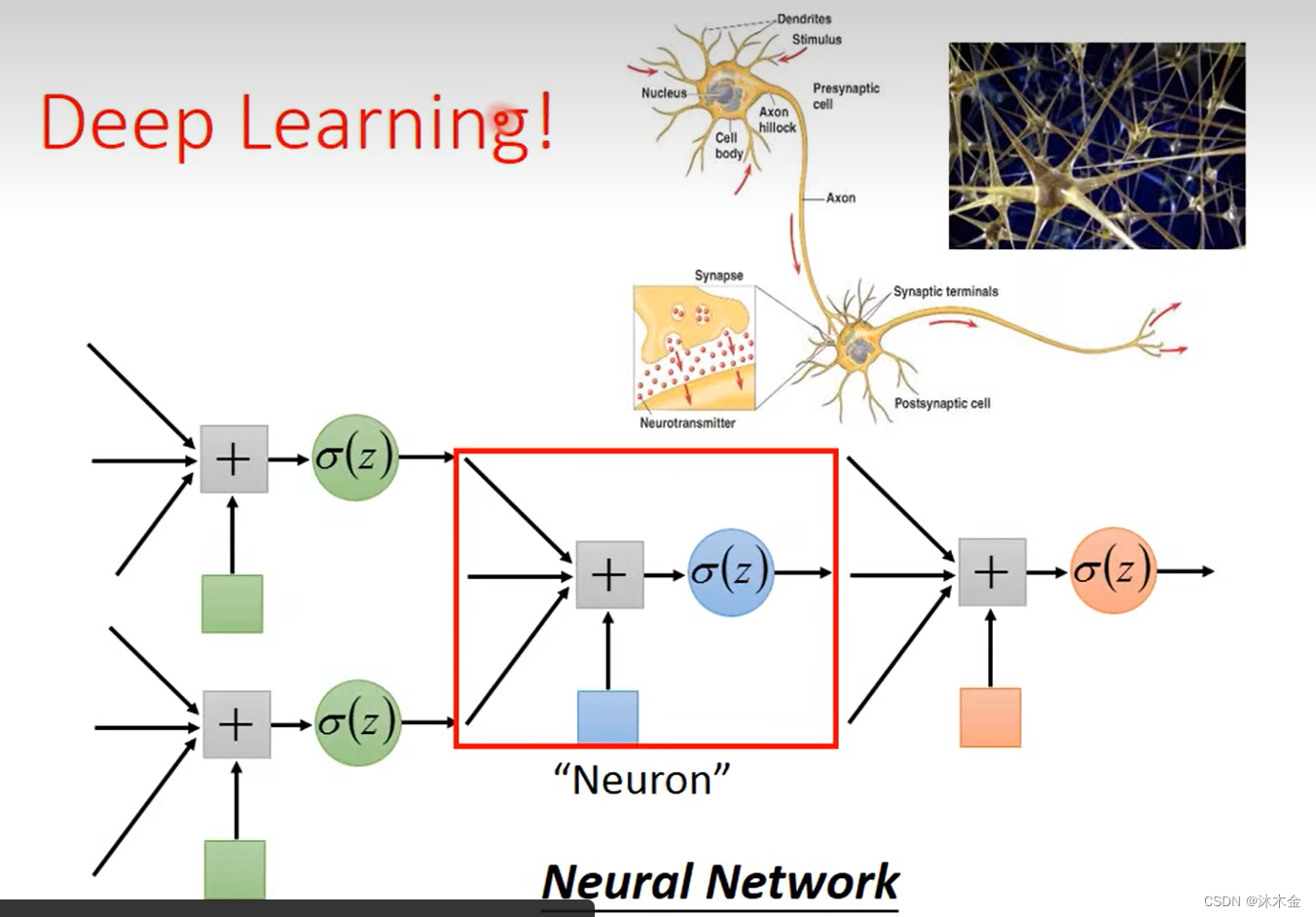
单层或多层的特征转换就形成了神经网络。















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











