










目录
一、顺序查找Sequential Search
如果数据项保存在如列表这样的集合中,我们会称这些数据项具有线性或者顺序关系。
在python list中,这些数据项的存储位置称为下标,这些下标都是有序的整数。通过下标,我们可以按照顺序来访问和查找数据项,这种技术称为“顺序查找”。
要确定列表中是否存在需要查找的数据项。
首先从列表的第一个数据项开始,按照下标增长的顺序,逐个对比数据项,如果到最后一个都未发现要查找的项,那么查找失败。

顺序查找:无序表查找代码
def sequentialSearch(alist, item):
found = False
pos = 0
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos += 1
return found二、算法分析
要对查找算法进行分析,首先要确定其中的基本计算步骤。回顾前面的知识,基本计算步骤必须要足够简单,并且在算法中反复执行。在查找算法中,这种基本计算步骤就是进行数据项的比对(当前数据项是等于还是不等于查找数据项,比对的次数决定了算法复杂度)。
在顺序查找算法中,为了保证是讨论的一般情形,需要嘉定列表中的数据项并没有按值排列顺序,而是随机放置在列表中的各个位置。
换句话说,数据项在列表各处出现的概率是相等的。
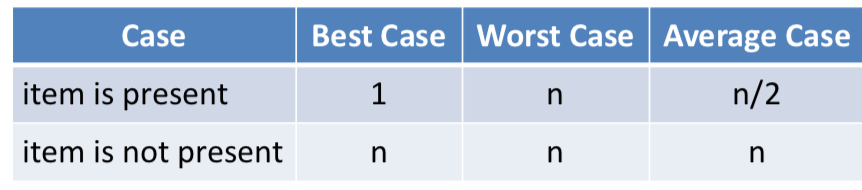
数据项是否在列表中,比对的次数是不一样的。如果数据项不在列表中,需要比对所有的数据项才能得知,比对的次数是n,如果数据项在列表中,需要比对的次数情况就比较复杂。最好的情况,第一次比对就找到,最坏的情况,要n次比对。
数据项在列表中,比对的一般情形如何?
因为数据项在列表中各个位置出现的概率是相等的,所以平均状态下,比对的次数是n/2。
所以顺序查找的算法复杂度是O(n)
这里我们假定列表中的数据项是无序的,那么如果数据项排了序,顺序查找算法的效率又如何呢?
实际的做法是,当数据项存在时,比对过程与无序表完全相同。不同之处在于,如果数据项不存在,比对可以提前结束。
如下图,查找数据项50,当看到54时,可以知道后面不可能存在50,可以提前退出查找。

三、顺序查找:无序表查找代码
def ordersequentialSearch(alist, item):
found = False
stop = False
pos = 0
while pos < len(alist) and not found and not stop:
if alist[pos] == item:
found = True
else:
if alist[pos] > item:
stop = True
else:
pos += 1
return found














 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









