







 本文介绍了SVM_Light的使用,包括如何在命令行下运行svm_learn.exe,以及详细解析了其各种选项,如分类、回归、参数C和γ等。还提到了数据输入格式和转导选项。提供了链接以获取源代码和示例数据。
本文介绍了SVM_Light的使用,包括如何在命令行下运行svm_learn.exe,以及详细解析了其各种选项,如分类、回归、参数C和γ等。还提到了数据输入格式和转导选项。提供了链接以获取源代码和示例数据。
对SVM的介绍,忽略,自行查找资料,可以参考李航博士的《统计学习方法》
源程序和软件到下面链接下载
http://www.cs.cornell.edu/People/tj/svm_light/
1、下载后解压得到两个.exe文件

再下载官网上的example,解压,放到与.exe同一目录下
直接点击是无法运行的,需要在命令行下执行
2、win+R输入cmd进入命令提示符窗口
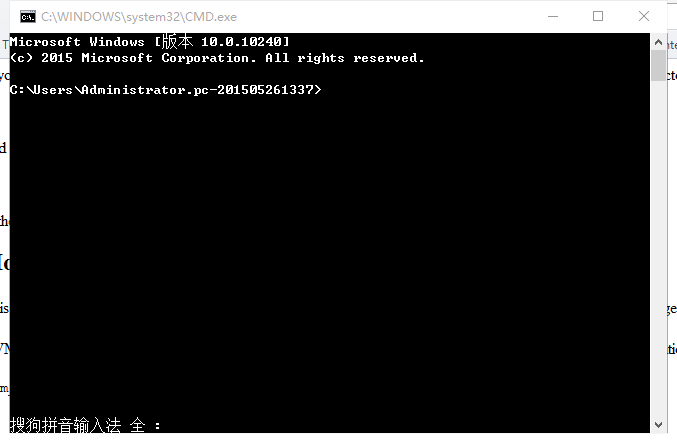
刚开始默认执行目录是c盘中的文件,修改执行目录到以上两个文件夹所在目录,方法参考以下链接
怎么用命令提示符进入某个指定的文件夹
最后应该是这样的

3、使用svm_learn.exe学习训练数据集
在命令窗口中输入下面这种格式
svm_learn [options] example_file model_file
svm_learn是.exe的名字
[options]有很多选项,在官网上有很详细的解释,这里贴出英文内容
Available options are:
可用的选型:
General options:
-? - this help
-v [0..3] - verbosity level (default 1) Learning options:
-z {c,r,p} - select between classification (c), regression (r), and
preference ranking (p) (see [Joachims, 2002c])
(default classification)
-c float - C: trade-off between training error
and margin (default [avg. x*x]^-1)
-w [0..] - epsilon width of tube for regression
(default 0.1)
-j float - Cost: cost-factor, by which training errors on
positive examples outweight errors on negative
examples (default 1) (see [Morik et al., 1999])
-b [0,1] - use biased hyperplane (i.e. x*w+b0) instead
of unbiased hyperplane (i.e. x*w0) (default 1)
-i [0,1] - remove inconsistent training examples
and retrain (default 0) Performance estimation options:
-x [0,1] - compute leave-one-out estimates (default 0)
(see [5])
-o ]0..2] - value of rho for XiAlpha-estimator and for pruning
leave-one-out computation (default 1.0)
(see [Joachims, 2002a])
-k [0..100] - search depth for extended XiAlpha-estimator
(default 0) Transduction options (see [Joachims, 1999c], [Joachims, 2002a]):
-p [0..1] - fraction of unlabeled examples to be classified
into the positive class (default is the ratio of
positive and negative examples in the training data) Kernel options:
-t int - type of kernel function:
0: linear (default)
1: polynomial (s a*b+c)^d
2: radial basis function exp(-gamma ||a-b||^2)
3: sigmoid tanh(s a*b + c)
4: user defined kernel from kernel.h
-d int - parameter d in polynomial kernel
-g float - parameter gamma in rbf kernel
-s float - parameter s in sigmoid/poly kernel
-r float - parameter c in sigmoid/poly kernel
-u string - parameter of user defined kernel Optimization options (see [Joachims, 1999a], [Joachims, 2002a]):
-q [2..] - maximum size of QP-subproblems (default 10)
-n [2..q] - number of new variables entering the working set
in each iteration (default n = q). Set n
补充:输入数据格式
参考:http://www.wfuyu.com/technology/22540.html
[label] [index1:value1] [index2:valude2]………………
实例如
+1 1:0.708 2:-1 3:1 4:-0.107
label:对应的是该组数据所属类别,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6894
6894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









