







1、延时队列
1.1、应用场景
- 订单支付失败,每隔一段时间提醒用户
- 用户并发量的情况,可以延时2分钟给用户发短信
1.2、如果队列空了?
**答:**客户端是通过队列的 pop 操作来获取消息,然后进行处理。处理完了再接着获取消息, 再进行处理。如此循环往复,这便是作为队列消费者的客户端的生命周期。
1.3、队列延迟
答: 用上面睡眠的办法可以解决问题。同时如果只有 1 个消费者,那么这个延迟就是 1s。如果有多个消费者,这个延迟会有所下降,因为每个消费者的睡觉时间是岔开来的。
解决办法
答: 那就是 blpop/brpop。这两个指令的前缀字符 b 代表的是 blocking,也就是阻塞读。阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消 息的延迟几乎为零。用blpop/brpop 替代前面的lpop/rpop,就完美解决了上面的问题。
1.4、空闲连接自动断开
答: 如果线程一直阻塞在哪里,Redis的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候 blpop/brpop 会抛出异常来。
2、位图
答: 位图是由多个二进制位组成的数组,数组中的每个二进制位都有与之对应的偏移量(从 0 开始),通过这些偏移量可以对位图中指定的一个或多个二进制位进行操作。

应用场景
- 用户行为记录器: 用用户
ID作为偏移量,若用户做了某种行为则通过SETBIT将二进制位设置为 1,通过GETBIT判断用户是否做了某种行为,通过BITCOUNT可以知道有多少用户执行了行为。 - 用户上线统计: 可以使用
SETBIT和BITCOUNT来实现,以用户ID作为key,假设今天是上线统计功能开放的第一天,ID为 1 的用户上线后就通过SETBIT 1 0 1。当要计算此用户的总共以来的上线次数时,使用BITCOUNT命令就可以得出的结果。
3、HyperlogLog
答: 在 Redis中每个键占用的内容都是 12K,理论存储近似接近 2^64 个值,不管存储的内容是什么。这是一个基于基数估计的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。但是这个估算的基数并不一定准确,是一个带有 0.81% 标准错误(standard error)的近似值。 但是,也正是因为只有 12K 的存储空间,所以,它并不实际存储数据的内容。
应用场景
答: 鉴于 HyperLogLog 不保存数据内容的特性,所以,它只适用于一些特定的场景。我这里给出一个最常遇到的场景需要:计算日活、7日活、月活数据。
分析:如果我们通过解析日志,把 Ip 信息(或用户Id)放到集合中,例如:HashSet。如果数量不多则还好,但是假如每天访问的用户有几百万。无疑会占用大量的存储空间。且计算月活时,还需要将一个整月的数据放到一个 Set 中,这随时可能导致我们的程序 OOM。
4、布隆过滤器
答:bloomfilter就类似于一个hashSet,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于**hash**算法和容器大小。如下所示:

4.1、应用场景
答: 准确快速的判断某个数据是否在大数据量集合中,并且不占用内存。
4.2、添加数据
介绍概念的时候,我们说可以将布隆过滤器看成一个容器,那么如何向布隆过滤器中添加一个数据呢?
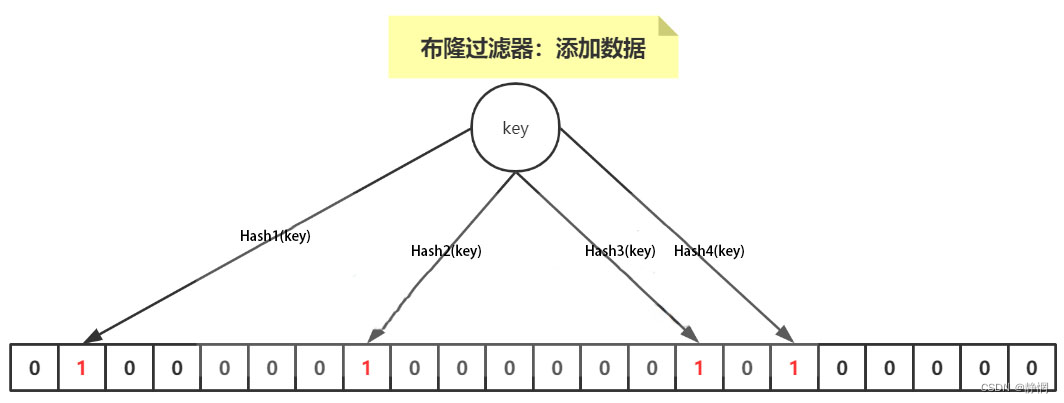
答: 如下图所示:当要向布隆过滤器中添加一个元素key时,我们通过多个hash函数,算出一个值,然后将这个值所在的方格置为1。
比如,下图hash1(key)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(key)=7,那么将第8个格子置位1,依次类推。
4.3、优缺点
优点: 优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
缺点: 随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
5、限流
5.1、简单限流
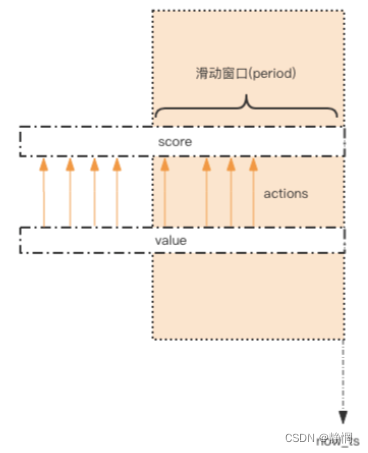
答: 限流需求中存在一个滑动时间窗口,适用 zset 数据结构的 score 值,可以通过 score来圈出这个时间窗口。而且我们只需要保留这个时间窗口,窗口之外的数据都 可以删除。每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。zset集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可 以了。
5.2、漏斗限流
答: 漏斗(funnel )限流是最常用的限流方法之一 。
漏洞的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。如果漏嘴流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率。
6、大海捞针——SCAN 系列命令注意事项?
SCAN的参数没有key,因为其迭代对象是DB内数据;- 返回值都是数组,第一个值都是下一次迭代游标;
- 时间复杂度:每次请求都是
O(1),完成所有迭代需要O(N),N是元素数量; - 可用版本:
version >= 2.8.0;
7、GeoHash
答:Redis3.2版本之后,新增了地理位置Geo模块。
应用场景
- 附近的
Mobike; - 美团和饿了么的“附近的餐馆”。















 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









