







特征匹配
特征匹配算法大致可以分为两类。一类是线性扫描,逐个比较查找空间中每个点,也就是穷举,效率较低。另一类是根据数据内在结构建立数据索引。
索引树属于第二类,其对搜索空间进行层次划分以加快搜索速度。索引树可以分为两类,Clipping(无重叠划分)和Overlapping(有重叠划分)。其代表分别为K-Dimension树和R树。R树请参考从B树、B+树、B*树谈到R 树。
K-D Tree
K-D树是二叉搜索树的多维推广。相比与BSF,K-D树需要解决两个问题:
- 划分维度选择。在每次划分时,选择哪一维进行分割?选择的属性取值越分散,那么划分结果分辨率越好。因此,K-D树选择方差最大的属性。
- 划分点如何选择。BSF不是平衡二叉树,K-D树希望尽量平衡,因此其使用中位数划分左右子树。
K-D树算法描述如下:
- 在K维数据集合中选择具有最大方差的维度k,然后在该维度上选择中值m为对该数据集合进行划分,得到两个子集合;同时创建一个中间结点node,用于存储维度k和中值m
- 对两个子集合重复步骤1,直至所有子集合都不能再划分为止;如果某个子集合不能再划分时,则将该子集合中的数据保存到叶子结点。
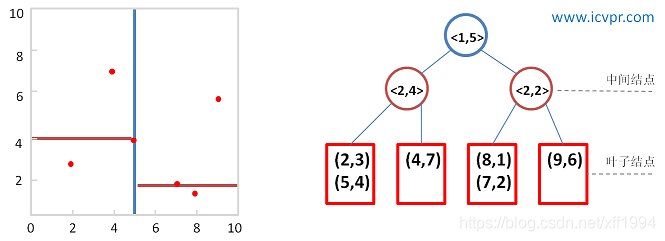
给定二维数据集合:(2,3), (5,4), (9,6), (4,7), (8,1), (7,2),构建的K-D树如上图。对于n个实例的k维数据来说,建立kd-tree的时间复杂度为O(knlogn)。
K-D 树的查找
Kd-Tree与二叉查找树之间的区别:
- 二叉查找树:数据存放在树中的每个结点(根结点、中间结点、叶子结点)中
- Kd-Tree:数据只存放在叶子结点,而根结点和中间结点存放一些空间划分信息(例如划分维度、划分值)
利用Kd-Tree进行最近邻查找的算法:
- 将查询数据Q从根结点开始,按照Q与各个结点的比较结果向下访问Kd-Tree,直至达到叶子结点。计算Q与叶子结点上保存的数据之间的距离,记录下当前最近邻点P_cur和最小距离D_cur。
- 进行回溯(Backtracking)操作,判断未被访问过的分支里是否还有离Q更近的点,它们之间的距离小于D_cur。回溯的判断过程是从下往上进行的,直到回溯到根结点为止。
比如在之前建立的K-D树中查找(8,3),过程如下:
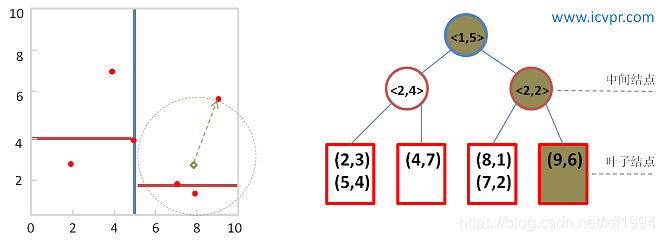
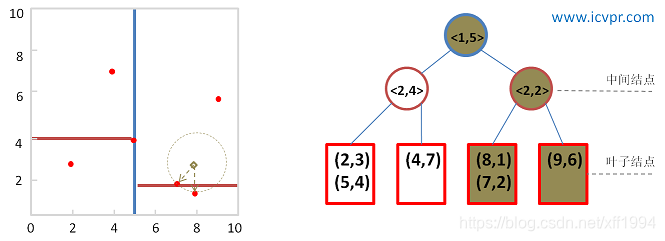
最后,查询点(8, 3)的近似最近邻点为(8, 1)和(7, 2) 。
K-D Tree with BBF
K-D树在维度较小时,算法的查找效率很高,然而当用于对高维数据时,查找效率会随着维度的增加而迅速下降。假设数据集的维数为D,一般来说要求数据的规模N满足
N
>
>
2
D
N>>2^D
N>>2D,才能达到高效的搜索效率。
Jeffrey S. Beis和David G. Lowe提出了一种改进算法——K-D Tree with BBF(Best Bin First),该算法能够实现近似K近邻的快速搜索,在保证一定查找精度的前提下使得查找速度较快。
先来看一下原始K-D 树为什么在低维空间中有效而到了高维空间后查找效率就会下降。为了能够找到查询点Q在数据集合中的最近邻点,有一个重要的操作步骤:回溯。该步骤是在未被访问过的且与Q的超球面相交的子树分支中查找可能存在的最近邻点。随着维度K的增大,与Q的超球面相交的超矩形(子树分支所在的区域)就会增加,这就意味着需要回溯判断的树分支就会更多,从而算法的查找效率便会下降很大。
一个很自然的思路是:限制回溯的次数上限,避免查找效率下降。但有两个问题需要解决:1)最大回溯次数怎么确定?2)怎样保证在最大回溯次数内找到的最近邻比较接近真实最近邻,即查找准确度不能下降太大。
问题1):最大回溯次数怎么确定?
最大回溯次数一般人为设定,通常根据在数据集上的实验结果进行调整。
问题2):怎样保证在最大回溯次数内找到的最近邻比较接近真实最近邻?
如果按照原来的回溯方法挨个地进行访问的话,那很显然最后的查找结果的精度很大程度上取决于数据的分布和回溯次数。实际上,在待回溯树分支中,离Q更近的树分支存在Q的最近邻的可能性更高。因此,我们需要区别对待每个待回溯的树分支,即采用某种优先级顺序来访问这些待回溯树分支,使得在有限的回溯次数中找到Q的最近邻的可能性很高。
基于BBF的Kd-Tree近似最近邻查找算法:
已知:Q:查询数据; KT:已建好的K-D Tree
- 查找Q的当前最近邻点P
1)从根结点开始,将Q与中间结点node(k,m)进行比较,根据比较结果选择某个分支;并将未被选择的另一个树分支所在的树中位置和它跟Q之间的距离一起保存到一个优先级队列中(按照距离从小到大的顺序排列);
2)按照步骤1)的过程,对树分支Branch进行如上比较和选择,直至访问到叶子结点,然后计算Q与叶子结点中保存的数据之间的距离,并记录下最小距离D以及对应的数据P。 - 基于BBF的回溯
已知:最大回溯次数BTmax
1)如果当前回溯的次数小于BTmax,且Queue不为空,则进行如下操作:从Queue中取出最小距离对应的Branch,然后按照1.1步骤访问该Branch直至达到叶子结点;计算Q与叶子结点中各个数据间距离,如果有比D更小的值,则将该值赋给D,该数据则被认为是Q的当前近似最近邻点;
2)重复1)步骤,直到回溯次数大于BTmax或Queue为空时,查找结束.
在之前建立的K-D树中查找(5.5, 5)的过程如下:
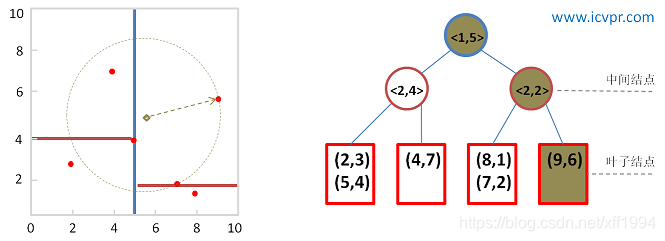
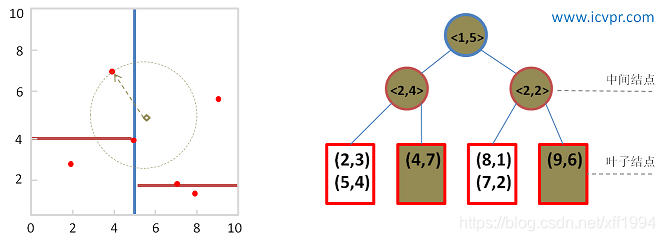

最后,查询点(5.5, 5)的近似最近邻点为(5, 4) 。

















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









