







官方文档:
https://flink.apache.org/2020/07/14/application-deployment-in-flink-current-state-and-the-new-application-mode/#application-submission
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/overview/
一、三种部署模式简介及提交命令
1.1 session模式
1.1.1 部署模式简介(main方法在客户端执行)
Session模式需要预分配好资源,也就是提前根据指定的资源参数初始化一个Flink集群,并常驻在YARN系统中,拥有固定数量的JobManager和TaskManager(注意JobManager只有一个)。提交到这个集群的作业可以直接运行,免去每次分配资源的overhead。但是Session的资源总量有限,多个作业之间又不是隔离的,故可能会造成资源的争用;如果有一个TaskManager宕机,它上面承载着的所有作业也都会失败。另外,启动的作业越多,JobManager的负载也就越大。所以,Session模式一般用来部署那些对延迟非常敏感但运行时长较短的作业。
1.1.2 启动命令
1.1.2.1 先启动yarn session
bin/yarn-session.sh \
-s 8 \
-jm 4g \
-tm 16g \
-nm yarn-session-flink \
-d
参数解释
| 参数 | 意义 |
|---|---|
| -s 8 | 每一个TaskManager上有8个slots |
| -jm 1024 | 表示jobmanager 1024M内存 |
| -tm 1024 | 表示taskmanager 1024M内存 |
| -nm,–name | 设置YARN上应用名字 |
| -d | 任务后台运行 |
| -D<property=value> | 动态属性 ,类似于-Dparallelism.default=3 |
| -q,–query | 显示可用的YARN资源(内存,内核) |
| -qu,–queue | 指定YARN队列 |
| -t,–ship | 指定YARN队列 |
| -nl,–nodeLabel | 为YARN应用程序指定YARN节点标签 |
| -z,–Zookeeper Namespace | 命名空间,用于创建高可用模式下的Zookeeper子路径 |
| -j,–jar | Flink jar文件的路径 |
1.1.2.2 将作业提交到创建好的yarn session上运行
flink run -t yarn-session -Dyarn.application.id=application_1650018331890_0001 -c org.apache.flink.examples.java.wordcount.WordCount examples/batch/WordCount.jar
1.2 per-job
1.2.1 部署模式简介(main方法在客户端执行)
在Per-Job模式下,每个提交到YARN上的作业会各自形成单独的Flink集群,拥有专属的JobManager和TaskManager。因此,以Per-Job模式提交作业的启动延迟可能会较高,但是作业之间的资源完全隔离,一个作业的TaskManager失败不会影响其他作业的运行,JobManager的负载也是分散开来的,不存在单点问题。当作业运行完成,与它关联的集群也就被销毁,资源被释放。所以,Per-Job模式一般用来部署那些长时间运行的作业。
1.2.2 提交命令
./flink run \
-m yarn-cluster \
-yjm 1024 \
-ytm 1024 \
-ynm wordcount \
-c org.apache.flink.examples.java.wordcount.WordCount \
-yj examples/batch/WordCount.jar
参数解释
| 参数 | 意义 |
|---|---|
| -m | 执行模式为yarn-cluster。也可以指定要连接的JobManager的地址,使用这个标志可以连接到配置中指定的不同的JobManager,注意:只有高可用性配置为NONE时才会考虑此选项。 |
| -yjm | 指定JobManager所在的Container内存。单位:MB |
| -ytm | 每一个TaskManager Container的内存,单位MB。 |
| -ys | 每一个TaskManager中slots的数量。 |
| -ynm | YARN中application的名称。 |
| -c | 指定Job对应的jar包中主函数所在类名。 |
| -yj,–yarnjar<arg> | jar包位置 |
| -yt,–yarnship | 传输指定目录下的文件(t用于传输) |
| -yqu,–yarnqueue<arg> | 指定yarn队列 |
| -yD <property=value> | 自定义参数 |
| -yid,–yarnapplicationId <arg> | 指定yarnid执行 |
| -yq,–yarnquery | 显示可用的YARN资源(内存,核心) |
| -d,–detached | 后台执行 |
1.2.3 新版本命令变动
./bin/flink run \
# 指定yarn的Per-job模式,-t等价于-Dexecution.target
-t yarn-per-job \
# yarn应用的自定义name
-Dyarn.application.name=wordcount \
# 未指定并行度时的默认并行度值, 该值默认为1
-Dparallelism.default=3 \
# JobManager堆的内存
-Djobmanager.memory.process.size=2048mb \
# TaskManager堆的内存
-Dtaskmanager.memory.process.size=2048mb \
# 每个TaskManager的slot数目, 最佳配比是和vCores保持一致
-Dtaskmanager.numberOfTaskSlots=2 \
# 防止日志中文乱码
-Denv.java.opts="-Dfile.encoding=UTF-8" \
# 支持火焰图, Flink1.13新特性, 默认为false, 开发和测试环境可以开启, 生产环境建议关闭
-Drest.flamegraph.enabled=true \
# 入口类
-c xxxx.MainClass \
# 提交Job的jar包
xxxx.jar
1.3 Application 模式
1.3.1 部署模式简介(main方法在集群中执行)
在Flink 1.11版本中,又引入了第三种全新的模式:Application 模式。Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。
1.3.2 提交命令
./bin/flink run-application \
-t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./MyApplication.jar
为了节省Flink分发资源的带宽,可以将作业jar包、flink客户端依赖包,预先上传至hdfs
在hdfs上新建目录
hdfs dfs -mkdir -p /remote-flink-dist-dir/{plugins,bin}
hdfs dfs -mkdir -p /job/jars
上传资源
#将flink lib目录和plugins目录下的所有依赖包上传
hdfs dfs -put ./lib/* /remote-flink-dist-dir/bin/
hdfs dfs -put ./plugins/* /remote-flink-dist-dir/plugins/
#将作业jar包上传
hdfs dfs -put MyApplication.jar /job/jars/
命令
./bin/flink run-application \
#部署目标
-t yarn-application \
#类的全包名
-c xxxx.MainClass \
#并发数
-Dparallelism.default=3 \ #也可以使用 -p 3
#JobManager 内存
-Djobmanager.memory.process.size=2048m \
#TaskManager 内存
-Dtaskmanager.memory.process.size=4096m \
#作业名字
-Dyarn.application.name="MyFlinkWordCount" \
#TaskManager slot数量
-Dtaskmanager.numberOfTaskSlots=3 \
#flink客户端依赖包上传地址
-Dyarn.provided.lib.dirs="hdfs://$NameNode:$port/remote-flink-dist-dir/lib;hdfs://myhdfs/remote-flink-dist-dir/plugins" \
#作业jar包上传地址
hdfs://$NameNode:$port/job/jars/MyApplication.jar
二、三种模式的特点及差异
三种部署模式的差异主要在于:
- 集群的生命周期和资源隔离保证
- main方法在客户端执行还是集群上执行
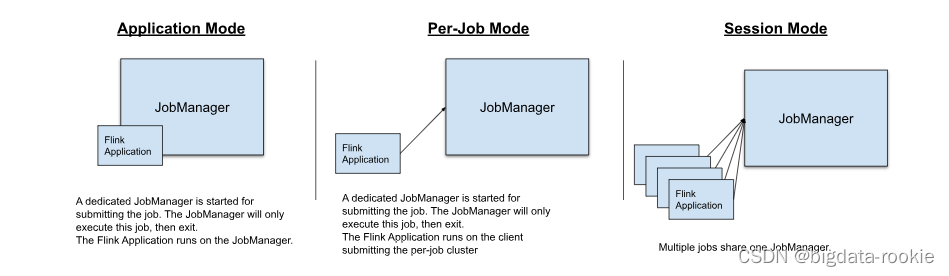
session:所有作业在一个集群,集群生命周期独立于集群上运行的任何作业的生命周期,并且资源在所有作业之间共享;集群只有一个JobManager,所以JobManager容易有负载瓶颈;main方法在客户端执行;
per-job:每个作业启动一个独立的集群,集群的生命周期与作业的生命周期绑定在一起,资源隔离有更好的保证;每个独立的集群都有一个Jobmanager,所以JoobManager负载均衡;main方法在客户端执行;
application:每个应用程序创建一个会话集群,集群的生命周期与应用的生命周期绑定在一起,集群中特定的作业之间共享资源,在应用粒度上资源隔离有保证;每个集群都有一个JobManager,所以JobManager负载均衡;main方法在集群上执行;
三、为什么要推出application 模式
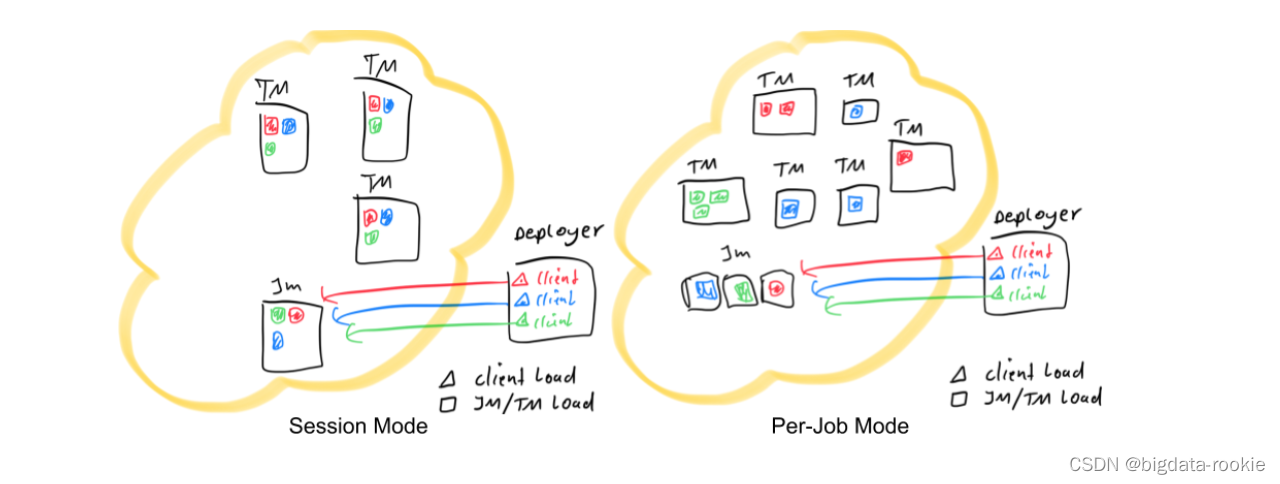
下面用简图描述三种模式的区别:
其中红色、蓝色和绿色的图形代表不同的作业,每个作业的并发度是3,黑色框框代表不同进程:JobManager、TaskManager、Deployer;彩色三角形表示客户端负载,彩色矩形表示JobManager和TaskManager负载;
- Deployer 指的是向yarn集群发起部署请求的节点,可理解为向yarn集群提交flink程序的客户端
Flink应用程序的执行包括两个阶段:pre 和 flight;用户执行flink命令,参数是run,将最终调用CliFrontend.java类的main()方法,当用户程序的main()方法被调用时为pre阶段,pre阶段需要完成一些工作:
- 本地下载作业所需的依赖项
- 通过执行mian()方法提取到JobGraph (StreamGraph —> JobGraph)
- 将依赖项和JobGraph上传至集群
直到以上工作都完成后,才会通过execute()触发Flink运行时真正开始执行作业(flight阶段)。
在session模式和per-job模式中,应用程序的main()方法在客户端执行,这使得客户端成为一个沉重的资源消费者,因为它可能需要大量的网络带宽来下载依赖项并将二进制文件发送到集群,并且需要CPU周期来执行main()。当跨用户共享客户机时,这个问题会更加明显。
开发人员和运维人员在提交Flink程序时可能会遇到提交十分缓慢的问题,这可能是Deployer所在的节点资源不足、服务器的性能不好、程序的jar包比较大,造成这一问题的原因就是pre阶段的速度受限于客户端服务器资源配置。基于这一观察,Flink 1.11引入了 application 模式作为部署选项,它支持轻量级的、更具可伸缩性的应用程序提交流程,能够在集群中的节点之间更均匀地分布应用程序部署负载。
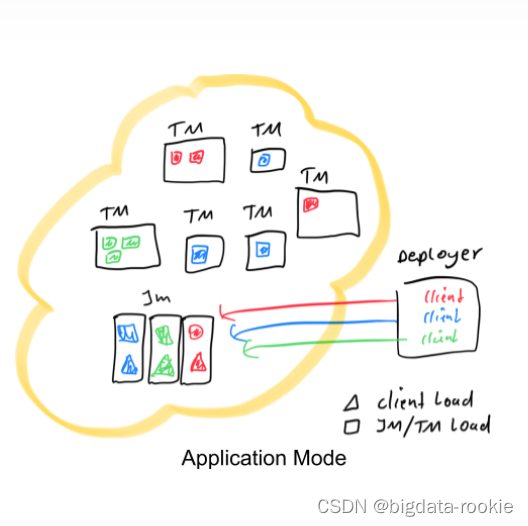
Application 模式为每个提交的应用程序创建一个集群,但是这一次,应用程序的main()方法在JobManager上执行,Deployer只是发起部署请求并将jar包上传,pre阶段的三件事交给了JobManager完成。如果一个main()方法中有多个env.execute()/executeAsync()调用,在Application模式下,这些作业会被视为属于同一个应用,在同一个集群中执行(如果在per-Job模式下,就会启动多个集群)。可以看作是创建一个会话集群,该会话集群仅在特定应用程序的作业之间共享,并在应用程序完成时关闭。使用这种体系结构,应用程序模式提供了与Per-Job模式相同的资源隔离和负载平衡保证,但是是在整个应用程序的粒度上。在JobManager上执行main()可以节省所需的CPU周期,还可以节省在本地下载依赖项所需的带宽。此外,由于每个应用程序有一个JobManager,因此它允许更均匀地分散网络负载,以便下载集群中应用程序的依赖项。
由此可见,Application模式本质上可以说是session模式和per-Job模式的结合。
















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









