







Power BI卡诺模型——从用户需求到产品创新
欢迎来到Powerbi小课堂,上期课程我们完成了全动态客户增减分析模型的制作,本期我将带大家制作Kano模型,卡诺模型是由日本学者狩野纪昭(Noriaki Kano)在1980年代提出的一种用于分析和分类顾客需求与产品功能之间关系的模型。
该模型帮助企业更好地理解哪些产品特性能够满足顾客的基本需求,哪些能够带来惊喜,以及哪些是无关紧要的。卡诺模型作为一种高效工具,能够帮助企业深入理解并分类顾客需求,进而优化产品设计,显著提升顾客满意度。通过合理应用卡诺模型,企业可以更好地满足顾客需求,提升市场竞争力。
接下来,让我们直接进入今天的实用技巧分享环节。如果您在实践过程中遇到任何问题,欢迎留言交流。
想要一份这样的可视化看板吗?想学吗?我教你呀!
一、案例背景:
卡诺模型将质量属性的充分与否跟客户满意程度之间的线性关系划分为五种形态:魅力、期望、必备、无差异和反向属性,这五种形态所构成的四象限图,就是KANO模型。
五种质量属性的释义
1)魅力质量属性:当其特性不充足并且是无关紧要的特性(非重要特性)时,顾客无所谓。当其特性充足时,顾客感到惊奇,并超出期望的满意。
有魅力的质量往往是质量的竞争性元素(或者是产品的魅力点、卖点),通常有以下特点:
a.具有全新的功能,以前从未见过;
b.性能极大提高;
c.引进一种以前从没有见过的新机制、服务新政策等,顾客忠诚度得到极大提高;
d.一种非常新颖的风格。
2)期望质量属性:该质量属性的充足程度与满意程度呈直线关系。以手机为例,“待机时间”“接收信号”是手机的质量特性之一,如果待机时间长,可以方便顾客,减少顾客的充电时间,电池的寿命也长;接收信号强,手机的接通率就高,顾客就会很满意。相反,待机时间短、接收信号弱,顾客就会不满意。
3)必备质量属性:当质量属性不充足(不满足顾客要求)时,顾客很不满意;当其充足(满足顾客要求)时,顾客认为是应该的,充其量也就是不抱怨。必备质量属性是基线质量要求。以手机为例,手机通话这一特性是理所当然的质量,若手机不能通话,顾客肯定会很不满意,因为通话是手机最基本的质量,否则就不能成为手机了。同样,安全自然也是手机最基本的质量,这是隐含或必须履行的需求。若出现漏电、短路乃至爆炸、燃烧等,人们会非常不满意,因为安全是最起码的要求。
4)无差异质量属性指的是,无论其充分与否,客户满意度基本不变,被视为可有可无的“鸡肋”特性,例如手机壳与手机捆绑销售时,是否配备手机壳,对多数人而言并无影响。
5)反向质量属性意味着,该属性越充分,客户满意度越低,如手机重量,在性能相当的情况下,手机越重,用户越感不便,不满情绪随之增加。
KANO模型的使用前提:
KANO模型是一个质量工具,它的目的是将产品/服务的质量特性进行分类,以帮助团队将有限的资源放在需要优先侧重设计/改善的产品/服务的质量特性上来,所以在使用KANO模型之前,我需要事先明确产品/服务的质量特性有哪些。
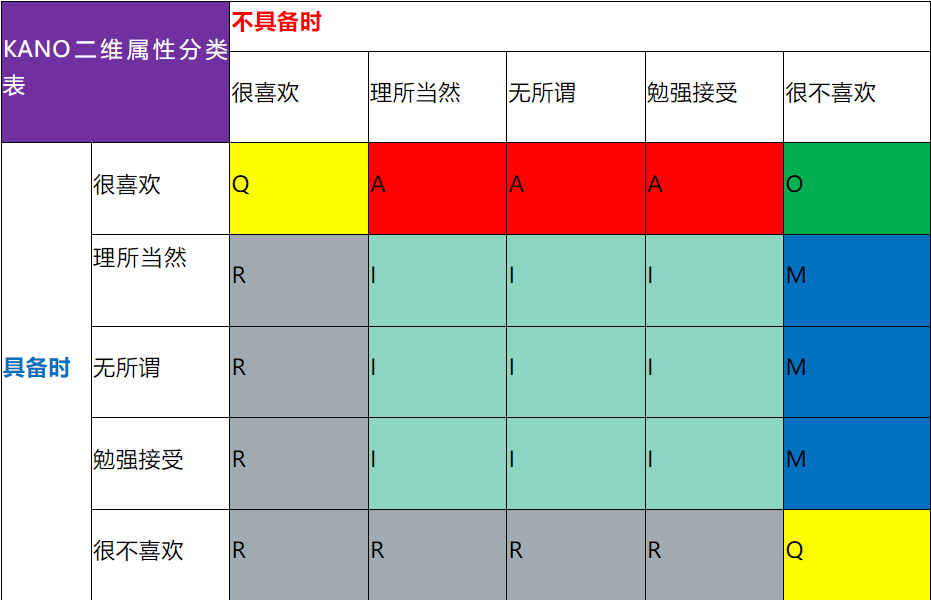
设计KANO调查问卷:
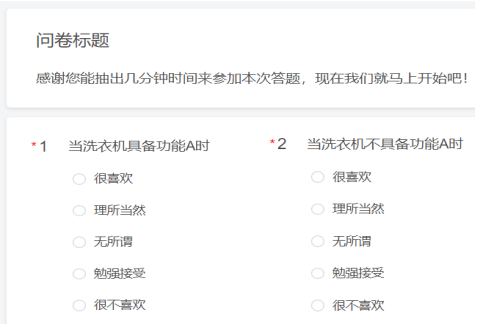
在质量特性确定之后,我们就可以按照如下方式将质量特性以KANO问卷的形式展开调查,进行数据统计。注意,每个产品/服务的质量属性都要以“具备时”和“不具备时”进行正反两次的调查。
问卷示例:
KANO模型实际运用过程中的注意事项:
KANO模型应用过程中最重要的一环是KANO问卷调查表,问卷调查表的选项务必能够让调查对象可以直观、准确地把握其含义。调查手表拍照功能时,最佳实践是让用户体验后填写问卷,而非依赖想象、图片或视频等抽象方式。
KANO模型不仅适用产品/服务的新功能,也适应对于产品的原有的功能的调查。KANO模型的五个质量属性可转变,例如手机拍照从2000年的魅力属性转变为2022年的必备属性。我们可以利用KANO模型来对产品/服务的现有功能进行重新梳理,以此来协助公司产品的战略调整,与时俱进;
二、设计思路:
(1)准备数据(问卷采集)
(2)数据清洗(逆透视、M函数)
(3)关系视图建立
(4)数据建模(Cronbach's Alpha系数、表函数)
(5)可视化制作
![]()
★准备数据
设计问卷,并采集问卷数据,问卷设计需合理,避免冗长,确保填写时长不超过10分钟,采集数据如下:
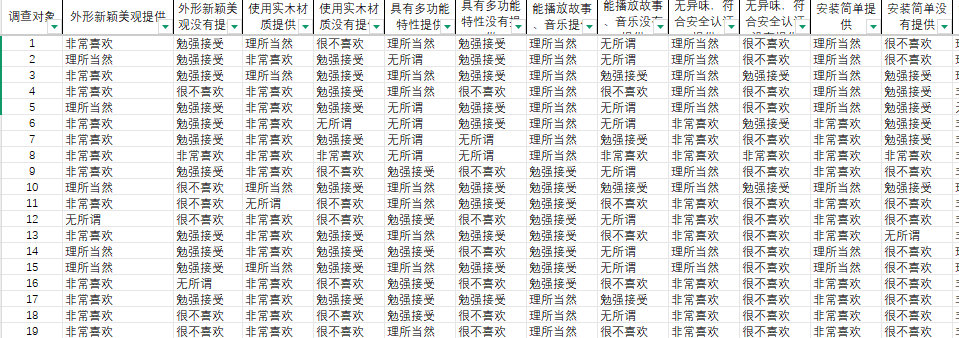
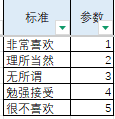
以下图为准输入转换标准
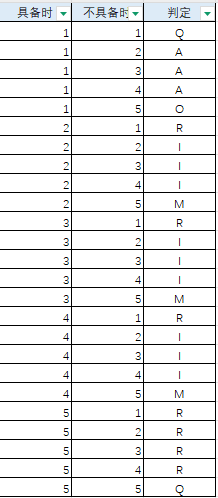
以下图为准输入判断矩阵
将问卷中涉及调研项目建立一个维度表

![]()
★数据清洗
1、进入power query界面,选择问卷调查数据,选中调查对象列,转换选项卡,选择逆透视其他列,
2、选中调查项目列,右键选择重复列,将列中文本提供、没有提供替换为空,
3、添加自定义列,使用M函数,将调查项目列中的文本提供、没有提供提取出来,重命名为调查类型,
公式:
= Table.AddColumn(替换的值1,
"自定义", each if Text.Contains([调查项目], "没有提供")
then "没有提供" else if Text.Contains([调查项目], "提供")
then "提供"else null)
公式解析:
Table.AddColumn:这是一个函数,用于在表格中添加新列。
替换的值1:这是要操作的表格名称。
"自定义":这是新列的名称。
each:表示对表格中的每一行进行操作。
Text.Contains([调查项目], "没有提供"):检查当前行的 "调查项目" 列中是否包含 "没有提供" 这个文本。
如果包含,则在新列中填入 "没有提供"。
Text.Contains([调查项目], "提供"):检查当前行的 "调查项目" 列中是否包含 "提供" 这个文本。
如果包含,则在新列中填入 "提供"。
else null:如果以上条件都不满足,则在新列中填入
null(空值)。
如下图建立一对多关系

![]()
★数据建模
1、新建列公式,文本转换数据
公式:
数值转换 = RELATED('转换标准'[参数]) 公式解析:
将问卷文本转换成可运算的数值,RELATED匹配查找函数
2、新建表公式,建立转换属性矩阵
公式:
属性转换矩阵 =
SUMMARIZE(
'原始数据',
'原始数据'[调查对象],
'原始数据'[功能],
"提供",
CALCULATE(
SUM('原始数据'[数值转换]),
'原始数据'[调查类型] = "提供"
),
"没有提供",
CALCULATE(
SUM('原始数据'[数值转换]),
'原始数据'[调查类型] = "没有提供"
)
)公式解析:
SUMMARIZE 函数:用于创建一个新的表格,按指定的列进行分组。这里按 '原始数据'[调查对象] 和 '原始数据'[功能] 两列进行分组。
"提供" 和 "没有提供":这是两个新列的名称,分别表示 “提供” 和 “没有提供” 两种调查类型的 数值转换 的总和。
CALCULATE 函数:用于在特定条件下计算表达式的值。在这里,它计算 '原始数据'[数值转换] 列的总和,但仅针对 '原始数据'[调查类型] 为 “提供” 或 “没有提供” 的行。
SUM('原始数据'[数值转换]):计算 '原始数据'[数值转换] 列的总和。
'原始数据'[调查类型] = "提供" 和 '原始数据'[调查类型] = "没有提供":这是筛选条件,分别限制只计算 调查类型 为 “提供” 或 “没有提供” 的行。
3、新建列公式,数据转换属性
公式:
属性 = LOOKUPVALUE('判定矩阵'[判定],'判定矩阵'[具备时],
'属性转换矩阵'[提供],'判定矩阵'[不具备时],'属性转换矩阵'[没有提供])公式解析:
通过LOOKUPVALUE函数,在判断矩阵表中查找判断列,条件为:当判断矩阵的'具备时'列与属性转换矩阵的'提供'列相匹配,且判断矩阵的'不具备时'列与属性转换矩阵的'没有提供'列相匹配时,将数据转换为相应的判定属性
4、建立度量值
公式:
A = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="A")
I = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="I")
M = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="M")
O = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="O")
Q = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="Q")
R = CALCULATE( COUNT('属性转换矩阵'[属性]),'属性转换矩阵'[属性]="R")
公式解析:
按不同属性,对属性转换矩阵表中的属性列进行计数
5、计算满意度和重要度
公式:
满意度 = DIVIDE([O]+[A],[M]+[O]+[A]+[I])
重要度 = DIVIDE([O]+[M],[M]+[O]+[A]+[I])
公式解析:
固定公式
满意度指数 = (兴奋型 + 期望型) / 总样本数(去除反向需求和疑问新需求)
不满意度指数 = (基本型 + 期望型) / 总样本数(去除反向需求和疑问新需求)
6、计算克朗巴哈系数
Cronbach's Alpha 的计算公式如下:
α=k−1k(1−σT2∑i=1kσi2)
其中:
k:问卷中题目或项目的数量。
σi2:第 i 个题目的方差。
σT2:问卷总分的方差。
首先建立一个系数计算辅助表
公式:
总分方差辅助 =
SUMMARIZE(
'属性转换矩阵',
'属性转换矩阵'[调查对象],
"正向分值", SUM('属性转换矩阵'[提供]),
"反向分值", SUM('属性转换矩阵'[没有提供])
)公式解析:
以调查对象为维度,计算不同调查项目提供与没有提供的分值求和,分别取名正向分支与反向分值,辅助计算总分方差
公式:
Cronbach_Alpha正向信度 =
VARFeature_Variances =
SUMMARIZE(
'属性转换矩阵',
'属性转换矩阵'[功能],
"Variance", VAR.S('属性转换矩阵'[提供])
)
VARTotal_Variance =
VAR.S('总分方差辅助'[正向分值]) // 计算总分的方差
VARk = DISTINCTCOUNT('属性转换矩阵'[功能]) // 功能数量
VARSum_Variance = SUMX(Feature_Variances, [Variance]) // 所有功能的方差之和
RETURN
IA(
Total_Variance = 0 || k <= 1,
BLANK(), // 如果总方差为 0 或功能数量 ≤ 1,返回空白
(k / (k - 1)) * (1 - (Sum_Variance / Total_Variance)) // 计算 Cronbach's Alpha
)
Cronbach_Alpha反向信度 =
VARFeature_Variances =
SUMMARIZE(
'属性转换矩阵',
'属性转换矩阵'[功能],
"Variance", VAR.S('属性转换矩阵'[没有提供])
)
VARTotal_Variance =
VAR.S('总分方差辅助'[反向分值]) // 计算总分的方差
VARk = DISTINCTCOUNT('属性转换矩阵'[功能]) // 功能数量
VARSum_Variance = SUMX(Feature_Variances, [Variance]) // 所有功能的方差之和
RETURN
IB(
Total_Variance = 0 || k <= 1,
BLANK(), // 如果总方差为 0 或功能数量 ≤ 1,返回空白
(k / (k - 1)) * (1 - (Sum_Variance / Total_Variance)) // 计算 Cronbach's Alpha
)公式解析:
变量1:构建一个虚拟表,该表以功能作为维度,用于计算每个功能是否提供的打分方差,即各题目的方差。
变量2:计算总分方差辅助表分值求和的方差,即总分方差
变量3:统计并计算项目(或功能)的总数量。
变量4:将各个功能的方差进行累加,得出功能方差之和。
返回结果:排除无效计算后,运行克朗巴哈系数计算
克朗巴哈系数(Cronbach's Alpha) 是一个用来衡量 问卷或量表 是否 可靠 的指标。通俗来说,它回答的问题是:问卷里的题目是不是在测量同一个东西? 如果题目都在测量同一个东西,那么问卷就是可靠的;如果不是,问卷就可能有问题。
7、数据诊断公式
公式:
问卷信度评价 = SWITCH(TRUE(),
OR([Cronbach_Alpha正向信度]>=0.8,'运算'[Cronbach_Alpha正向信度]>=0.8),"OK",
"NG")
下图克朗巴哈系数(Cronbach's Alpha)衡量标准,只有当问卷信度达到OK标准时,我们进行的卡诺模型分析才具有实际意义

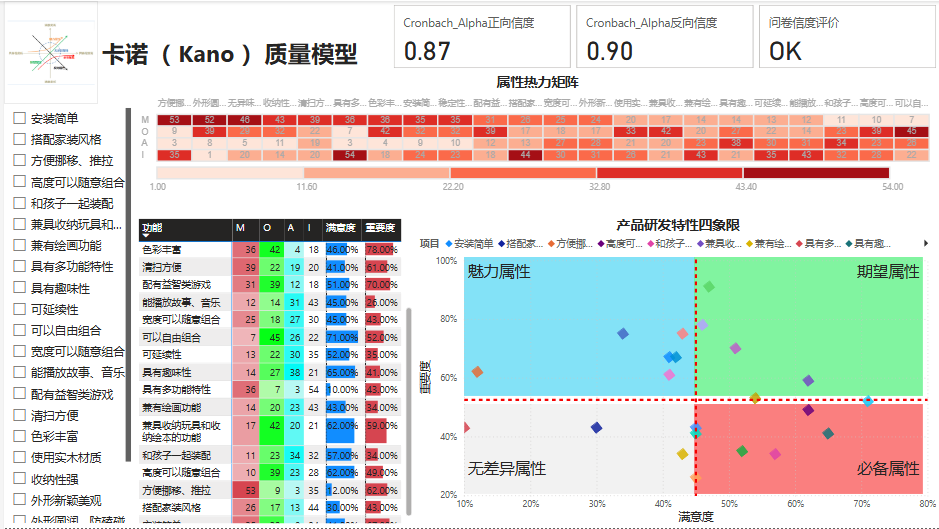
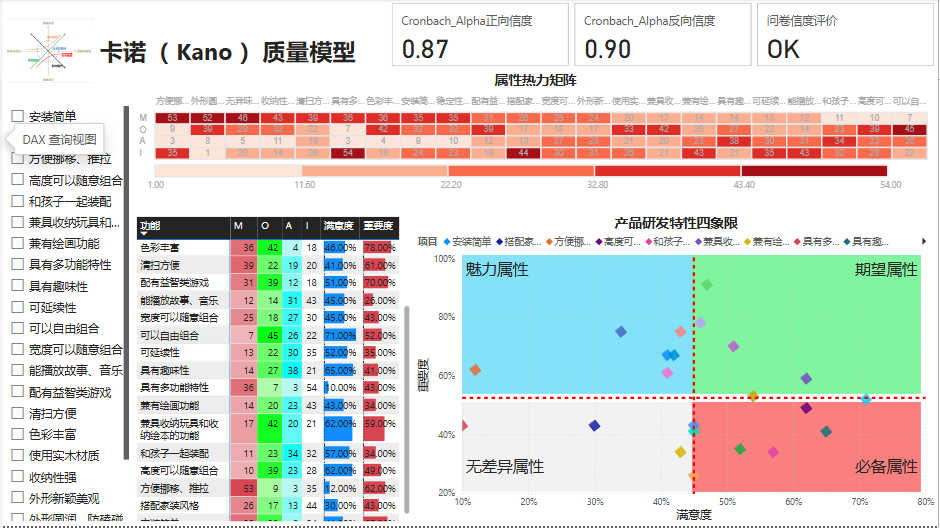
1、客户管理驾驶舱
第一步:插入一个文本框,输入标题
第二步:插入一个切片器,放入功能维度表中的项目列
第三步:插入一个卡片图新,分别拖入Cronbach_Alpha正、反向信度和问卷信度评价。
第四步:插入一个第三方视觉对象热力图,类别拖入项目,Y拖入度量值M、O、A、I。
第五步:插入一个矩阵图,行拖入功能,值拖入度量值M、O、A、I、满意度、重要度。
第六步:插入一个散点图,X轴拖入度量值满意度,Y轴拖入度量值重要度,图例拖入项目,向视觉对象添加进一步分析,添加两条中值线,数据系列分别是重要度和满意度。
第七步:美化界面
好的,今天的讲解就到这里。本期内容相对容易。如果在学习过程中需要帮助,欢迎随时联系作者,精彩内容,敬请期待。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











