







HiDream-E1 图像编辑模型
一、引言与背景
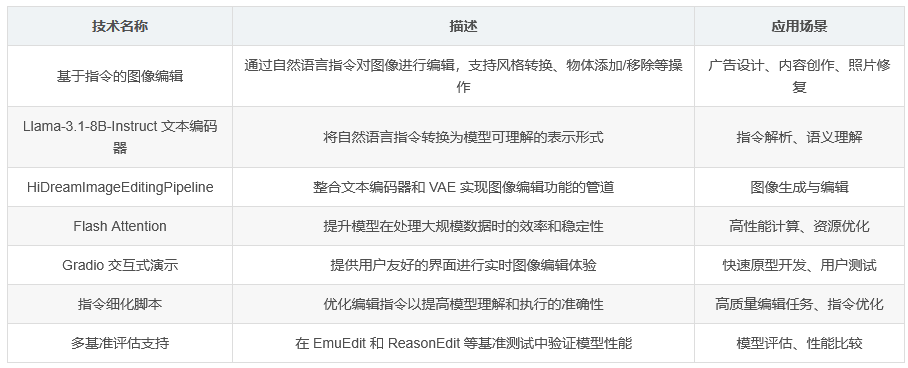
HiDream-E1 是一个基于 HiDream-I1 构建的指令式图像编辑模型,于 2025 年 4 月 28 日开源。该模型旨在通过自然语言指令对图像进行编辑,支持多种复杂的编辑任务,如风格转换、物体添加/移除、颜色调整等。其开发团队强调,为了体验模型的全部功能,用户可以访问其官方网站 https://vivago.ai/ 获取更多信息。
二、环境配置与安装
论文提供了详细的环境配置指南,包括以下步骤:
-
依赖安装:通过
pip install -r requirements.txt安装基础依赖。 -
Flash Attention 安装:推荐使用命令
pip install -U flash-attn --no-build-isolation进行更新。 -
Diffusers 库安装:建议从 Hugging Face 的 GitHub 仓库直接安装最新版本:
pip install -U git+https://github.com/huggingface/diffusers.git。 -
CUDA 版本建议:推荐使用 CUDA 12.4 版本以确保最佳性能。
三、模型架构与依赖
HiDream-E1 的架构基于以下核心组件:
-
文本编码器:采用
meta-llama/Llama-3.1-8B-Instruct作为文本编码器,负责将自然语言指令转换为模型可理解的表示形式。 -
图像处理管道:通过
HiDreamImageEditingPipeline实现图像编辑功能,该管道整合了文本编码器和 VAE(变分自编码器)进行图像生成与编辑。 -
依赖模型:模型依赖于 Hugging Face 平台上的多个预训练模型,包括 Llama 和 Google 的 T5 文本编码器。
四、使用示例与代码实现
论文提供了完整的代码示例,展示了如何使用 HiDream-E1 进行图像编辑:
import torch
from transformers import PreTrainedTokenizerFast, LlamaForCausalLM
from pipeline_hidream_image_editing import HiDreamImageEditingPipeline
from PIL import Image
# 加载文本编码器和分词器
tokenizer = PreTrainedTokenizerFast.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
text_encoder = LlamaForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
output_hidden_states=True,
output_attentions=True,
torch_dtype=torch.bfloat16,
)
# 初始化 HiDream 图像编辑管道
pipe = HiDreamImageEditingPipeline.from_pretrained(
"HiDream-ai/HiDream-E1-Full",
tokenizer_4=tokenizer,
text_encoder_4=text_encoder,
torch_dtype=torch.bfloat16,
)
# 加载并预处理输入图像
input_image = Image.open("input.jpg").resize((768, 768))
# 将管道移动到 GPU
pipe = pipe.to("cuda", torch.bfloat16)
# 执行图像编辑
edited_image = pipe(
prompt="Editing Instruction: Convert the image into a Ghibli style. Target Image Description: A",
image=input_image,
guidance_scale=5.0,
image_guidance_scale=4.0,
num_inference_steps=28,
generator=torch.Generator("cuda").manual_seed(3),
).images[0]
# 保存编辑后的图像
edited_image.save("output.jpg")
五、指令格式与细化
HiDream-E1 接受特定格式的编辑指令,示例格式如下:
Editing Instruction: {instruction}. Target Image Description: {description}
例如:
Editing Instruction: Convert the image into a Ghibli style. Target Image Description: A
论文还提供了指令细化脚本 instruction_refinement.py,用于优化编辑指令。该脚本需要 VLM API 密钥,支持本地运行 vllm 或使用 OpenAI API。
六、交互式演示
为了便于用户快速体验模型功能,HiDream-E1 提供了基于 Gradio 的交互式演示。用户可以通过以下命令启动演示:
python gradio_demo.py
七、评估结果
论文展示了 HiDream-E1 在 EmuEdit 和 ReasonEdit 基准测试中的评估结果,与其他模型的对比情况如下表所示:
| 模型名称 | EmuEdit Global | EmuEdit Add | EmuEdit Text | EmuEdit BG | EmuEdit Color | EmuEdit Style | EmuEdit Remove | EmuEdit Local |
|---|---|---|---|---|---|---|---|---|
| OmniGen | 1.37 | 2.09 | 2.31 | 0.66 | 4.26 | 2.36 | 4.73 | 2.10 |
| MagicBrush | 4.06 | 3.54 | 0.55 | 3.26 | 3.83 | 2.07 | 2.70 | 3.28 |
| UltraEdit | 5.31 | 5.19 | 1.50 | 4.33 | 4.50 | 5.71 | 2.63 | 4.58 |
| Gemini 2.0-Flash | 4.87 | 7.71 | 6.30 | 5.10 | 7.30 | 3.33 | 5.94 | 6.29 |
| HiDream E1 | 5.32 | 6.98 | 6.45 | 5.01 | 7.57 | 6.49 | 5.99 | 6.35 |
从评估结果可以看出,HiDream-E1 在多个指标上表现优异,特别是在 “EmuEdit Global”、“EmuEdit Add” 和 “EmuEdit Style” 等关键指标上均取得了较高的分数,表明其在全局编辑、添加操作和风格转换任务中具有较强的能力。
八、许可证协议
HiDream-E1 的变压器模型采用 MIT 许可证。然而,其 VAE 组件来源于 FLUX.1 [schnell],文本编码器则来自 Google 的 T5-v1_1-xxl 和 Meta 的 Llama-3.1-8B-Instruct。用户在使用时需遵守各组件的许可证条款。
此外,用户对其使用模型生成的所有内容拥有完全所有权,可以自由使用生成内容,但必须遵守本许可协议。用户需对其使用模型的方式负责,不得创建非法内容、有害材料、可能伤害他人的个人信息、虚假信息或针对弱势群体的内容。
九、总结
HiDream-E1 作为一个开源的指令式图像编辑模型,提供了强大的图像编辑能力,并通过详细的文档和示例代码降低了使用门槛。其在多个评估基准中的优异表现证明了模型的有效性和实用性。尽管如此,用户在使用过程中仍需注意遵守各组件的许可证要求,并确保内容的合法性和伦理性。
核心技术汇总表

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









