







这个主题是讲解机器学习,会全面的讲解理论,知识干货。

学了理论不会实践怎么办?调了包不懂实现?
每个算法都会配备实践,手推和简单实现,让你知其然,还要知其所以然。
当然参考很多大佬的书,不举例了,相信大家都知道。我可能不能完全的去讲每一个概念,一是我不想满屏都是补充概念避免给刚学习的人第一反应知识体系太大,可以学到什么补什么;二也是篇幅限制或者疏忽。部分简单的不赘述了,只是一个简单概念,比如回归是什么,回归用于预测输入变量和输出变量之间的关系,等价于函数拟合,如房价的预测,电影票房预估等。
本人水平有限,错误之处敬请担待。
第一个机器学习算法:线性回归
-
理论知识
线性回归是最简单的机器学习,但是可以由它入门理解机器学习。
预测函数: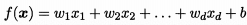
向量形式: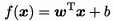 ,也可以把b合入w
,也可以把b合入w 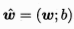 ,也就是希望学得一个w 使此线性模型尽可能准确预测实值输出。
,也就是希望学得一个w 使此线性模型尽可能准确预测实值输出。
所以只看这个形式,线性回归模型简单,可解释性强,w表达了每个特征的权重。如何求解这个w呢,采用常用的均方误差损失函数。
求解最优化w可以通过最小二乘法获得解析解,推导后若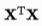 满秩,
满秩,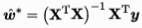 。
。
但是现实情况常为不满秩,比如极端下样本数量小于特征数量,或者特征之间线性相关,而且数据本身也有噪音,解析解意义不大。当特征数量特别大的时候,受限于求逆的复杂度,计算非常缓慢,后面会介绍梯度下降算法。
不满秩则存在多个解,都能使误差最小,如何选择呢?常见的做法是引入正则化项。L1正则也叫lasso回归,表达式为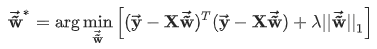
L2正则也叫ridge回归,表达式为
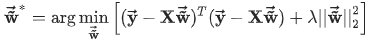 同时包含L1、L2正则化叫Elastic Net,表达式为
同时包含L1、L2正则化叫Elastic Net,表达式为
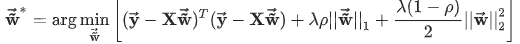 ,
,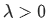 为正则化系数,调整正则化项与训练误差的比例。
为正则化系数,调整正则化项与训练误差的比例。
一般机器学习算法求解参数不会有解析解,常使用最简单通用的迭代计算方法梯度下降算法,这个基础知识不具体讲了,包括学习率、初始位置的重要性,从比较慢的原始批量梯度下降到小批量梯度下降、随机梯度下降其优缺点,以及使用梯度下降算法之前,为了加快收敛数据需要进行标准化,可以自行理解下。 -
手推实战
这里展示核心部分代码,读取数据、评价可视化部分不展示了
- 均方误差
公式:
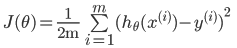
代码实现:
def J_coss(X, y, theta):
m = len(y)
j = np.dot((X*theta - y).T, (X*theta - y)) / (2*m)
return j
- 梯度下降
公式:
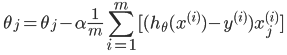
代码:
def gradientDescent(X, y, theta, alpha, num_iters):
m = len(y) # 样本数量
J_history = np.zeros((num_iters, 1)) # 保存每次迭代的损失
for i in range(num_iters): # 遍历迭代次数
theta = theta - ((alpha / m) * (np.dot(X.T, np.dot(X, theta) - y))) # 批量梯度的计算
J_history = J_coss(X, y, theta) # 调用计算代价函数
return theta, J_history
- 数据归一化
加快收敛,可以最大最小归一化,也可以标准化
若标准化:
def standard_scaler(X):
X = np.array(X)
mean_x = np.mean(X, 0) # 求每一列的平均值(0指定为列,1代表行)
std_x = np.std(X, 0) # 求每一列的标准差
for i in range(X.shape[1]): # 遍历列
X[:, i] = (X[:, i] - mean_x[i]) / std_x[i] # 标准化
return X
输入数据后把整个流程串起来,接下去可以往表达式加L1、L2正则化项,不展示了。
最方便的是调scikit-learn包实现
from sklearn.linear_model.
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.preprocessing import MinMaxScaler # 归一化
# 归一化操作
scaler = StandardScaler()
scaler = MinMaxScaler()
scaler.fit(X_train)
x_train = scaler.transform(X_train)
x_test = scaler.transform(X_test)
# 线性模型拟合
LR_reg = LinearRegression()
LR_reg.fit(x_train, y)
print(LR_reg.coef_) # Coefficient of the features 特征系数
print(LR_reg.intercept_) # 又名bias偏置
# 预测结果
result = LR_reg.predict(x_test)
带正则化项的sklearn包可以这样导入
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
使用非常相似,可以仔细看看官网详细说明哦。
- 正则化再讲
正则化是为了控制参数搜索空间,防止过拟合。
对于线性回归如何选取正则化有一个总结:
只要数据线性相关,线性回归拟合的不是很好,可以考虑使用岭回归(L2)。如果输入特征的维度很高,而且是稀疏线性关系的话,考虑使用Lasso回归。
L1正则化(Lasso回归)可以使得一些特征的系数变小,甚至可以使一些绝对值较小的系数直接变为0,从而增强模型的泛化能力,要在一堆特征里面找出主要的特征是首选。
在我们发现用Lasso回归太过(太多特征被稀疏为0),而岭回归也正则化的不够(回归系数衰减太慢)的时候,可以考虑使用ElasticNet回归来综合得到比较好的结果
















 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









