







熵与信息增益
在决策树算法中,决定特征优先级时,需要用到熵的概念,先挖个坑
1 信息量
信息量是用来衡量一个事件的不确定性的;一个事件发生的概率越大,不确定性越小,则它所携带的信息量就越小。
假设X是一个离散型随机变量,其取值集合为
X
,概率分布函数为
举个例子,小明考试经常不及格,而小王则经常得满分,所以我们可以做如下假设:
事件A:小明考试及格
概率为
事件B:小王考试及格
概率为
可以看出:小明及格的可能性很低(10次考试只有1次及格),因此如果某次考试及格了(大家都会说:XXX竟然及格了!),必然会引入较大的信息量,对应的I值也较高;而对于小王而言,考试及格是大概率事件,在事件B发生前,大家普遍认为事件B的发生几乎是确定的,因此当某次考试小王及格这个事件发生时并不会引入太多的信息量,相应的I值也非常的低。
这跟《黑天鹅》一书中强调的“黑天鹅事件往往有重大影响”有异曲同工之妙。
2 熵
熵是用来衡量一个系统的混乱程度的,代表一个系统中信息量的总和;信息量总和越大,表明这个系统不确定性就越大。
假设小明的考试结果是一个0-1分布 XA 只有两个取值{0:不及格,1:及格}。那么在某次考试结果公布前,根据先验知识,小明及格的概率仅有10%,其余90%的可能都是不及格的。
在上面章节,我们可以分别得到小明和小王考试及格对应的信息量。
而如果我们想要进一步度量小明考试结果的不确定度,就要借助于熵的概念。
信息量用来衡量一个事件的不确定度,熵则用来衡量一个系统(也就是所有事件)的不确定度。
那如何度量系统中所有事件的不确定度?期望。
我们对所有可能事件所带来的信息量求期望,其结果就能衡量小明考试的不确定度:
与之对应地,小王的熵:
虽然小明考试结果的不确定度较低,毕竟十次有9次都不及格;但是小王考试结果的不确定度更低,1000次考试只有1次不及格的机会,结果相当的确定。
再假设一个成绩相对普通的学生小东,他及格的概率是
P(xC)=0.5
,即及格与否的概率是一样的,对应的熵:
小东考试结果的不确定度比前边两位同学要高很多,在成绩公布之前,很难准确猜测出他的考试结果。
从上面可以看出,熵是信息量的期望值,它是一个随机变量的确定性的度量。
熵越大,变量的取值越不确定;反之,熵越小,变量取值就越确定。
对于一个随机变量X,它所有可能取值的信息量的期望
E[I(x)]
就称为熵。
X的熵定义为:
如果 p(x) 是连续型随机变量的 p(df) ,则熵定义为:
为了保证有效性,这里约定当 p(x)→0 时,有 p(x)logp(x)→0
假如X为0-1分布,当两种取值的可能性相等时(p=0.5),不确定度最大(此时没有任何先验知识);当p=0或1时,熵为0,即此时X完全确定。
熵与概率p的关系如下图:
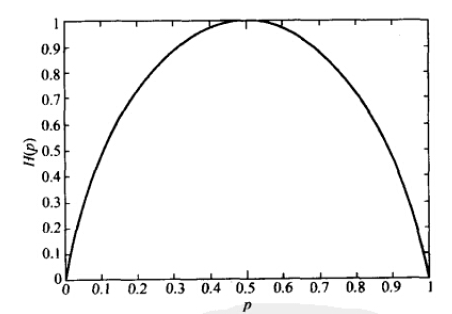
注:熵的单位随着公式中log运算的底数而变化,当底数为2时,单位为“比特”(bit),底数为e时,单位为“奈特”。
3 条件熵
在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用 H(Y|X) 表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
如果这样说显得空洞,那么可以进行转换:
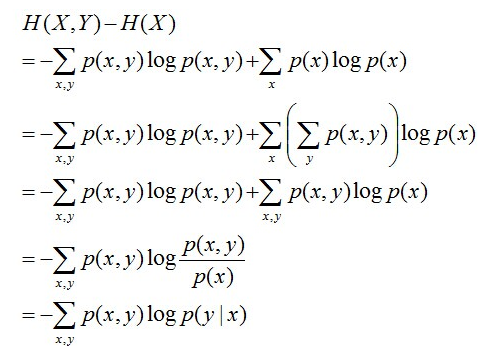
4 相对熵
相对熵(relative entropy)又称为KL散度(Kullback-Leibler divergence),KL距离,是两个随机分布间距离的度量。
记为
DKL(p||q)
,它度量当真实分布为p时,假设分布q的无效性。
并且为了保证连续性,做如下约定:
0log00=0,0log0q=0,plogp0=∞
显然,当p=q时,两者之间的相对熵
DKL(p||q)=0
上式最后的Hp(q)表示在p分布下,使用q进行编码需要的bit数,而H(p)表示对真实分布p所需要的最小编码bit数。
基于此,相对熵的意义就很明确了:
DKL(p||q)
表示在真实分布为p的前提下,使用q分布进行编码相对于使用真实分布p进行编码(即最优编码)所多出来的bit数。
5 交叉熵
交叉熵容易跟相对熵搞混,二者有所区别。
假设有两个分布p,q,它们在给定样本集上的交叉熵定义如下:
可以看出,交叉熵与相对熵仅相差了H(p),当p已知时,可以把H(p)看做一个常数,此时交叉熵与KL距离在行为上是等价的,都反映了分布p,q的相似程度。
最小化交叉熵等于最小化KL距离。它们都将在p=q时取得最小值H(p)(因为p=q时KL距离为0,因此有的工程文献中将最小化KL距离的方法称为Principle of Minimum Cross-Entropy (MCE)或Minxent方法)。
在logistic regression中,
p:真实样本分布,服从参数为p的0-1分布,即X∼B(1,p)
q:待估计的模型,服从参数为q的0-1分布,即X∼B(1,q)
两者的交叉熵为:
对所有训练样本取均值得:
这个结果与通过最大似然估计方法求出来的结果一致。
6 信息增益
在决策树ID3算法中,使用信息增益来选择最佳的特征作为决策点。
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度,即用来衡量特征X区分数据集的能力。
当新增一个属性X时,信息熵
H(Y)
的变化大小即为信息增益。
I(Y|X)
越大表示X越重要。
7 互信息
两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
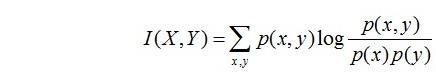
而一般来说,熵 H(Y) 与条件熵 H(Y|X) 之差称为互信息。推导如下:
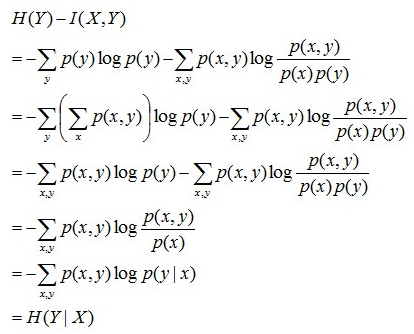
所以在决策树算法中,信息增益等价于训练数据集中类和特征的互信息。
8 信息增益比
在决策树C4.5算法中,使用信息增益比来选择最佳的特征作为决策点。
特征A对训练数据集D的信息增益比 gR(D|A) 定义为信息增益 I(D|A) 与训练数据集D关于特征A的熵 HA(D) 之比:
这之中
本篇博客主要参考自:
《信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息》
《交叉熵(Cross-Entropy) 》
《最大熵模型中的数学推导》
《我们为什么需要信息增益比,而不是信息增益? 》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









