







作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/53121473
声明:版权所有,转载请联系作者并注明出处
1 问题定义
基于Document level的情感分析用于根据document确定用户对产品的整体情感倾向。
2 背景综述
1、传统方法
将情感分析作为一个文本分类问题,将标注好的情感倾向(比如positive,negative)或者情感分数作为类别label,用机器学习的方法训练文本分类器。
由于分类器的性能极大依赖于文本特征(例如bag of word),所以传统方法的重心在于如何设计出更好的特征提取器。
2、深度学习方法
利用设计好的神经网络来学习低维文本特征。然而,这些方法忽略了用户和产品的特征。
3、以往方法的缺点:
- 只注重局部文本信息,忽略全局的用户偏好以及产品特点;
- 鉴于模型复杂度,就算考虑用户偏好和产品特点,也只是单词层面的。
3 灵感来源
有论文尝试过将用户、产品的信息和神经网络结合起来。
在输入层将word embedding和preference matrix作为输入,利用CNN提取文本特征,然后将user/product vector和文本特征结合后输入到softmax。
然而模型的问题在于:
- 数据量(用户评论)较少的情况下,训练preference matrix比较困难(效果不理想);
- 只利用了word evel的用户和产品信息,忽略了document level信息的使用。
4 方法概述
- 以word为单位输入LSTM,提取每个sentence的特征,再以sentence为单位输入LSTM,提取document的特征;
- 根据attention机制在不同的语义层面加入产品和用户的信息。
- 最后将得到的特征进行分类。
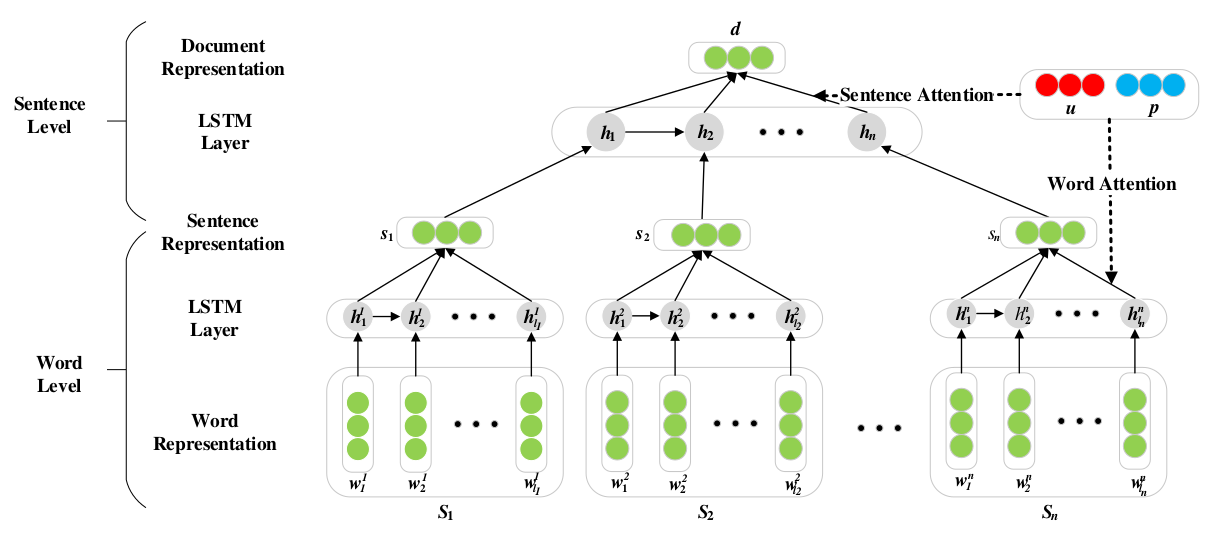
层级LSTM
- word->sentence
- 将每个word映射到低维语义空间,得到相应的词嵌入 wij ;
- 每次输入一个词嵌入,LSTM的cell state cij 和hidden state hij 都得以更新,这样输入一个句子就得到一系列的hidden state [hi1,hi2,...,hili] ;
- 将这一系列的hidden state输入average pooling layer,得到句子表示 si 。
其中
hij
推算如下:
这里 i,f,o 代表激活门, ∘ 代表点乘, σ 代表sigmoid函数。
- sentence->document
- 将上一步得到的sentence向量表示
[s1,s2,...,sn] 送进LSTM;- 经过如上的变换过程,一篇document得到一系列的hidden state [hi1,hi2,...,hili] ;
- 将这一系列的hidden state输入average pooling layer,得到文档表示 d 。
attention机制
不同的word对于表达这个sentence含义的贡献应该是不一样的,同理,不同的sentence对于表达这个document含义的贡献也应该不一样。
但上述建模过程中,由LSTM的隐层状态到更高一级的语义表示过程中,average pooling操作相当于每个word(sentence)对sentence(document)的语义表示贡献是一致的。attention机制通过赋予sentence和document中不同部分在语义表达中不同的贡献度来提取出特定user/product的关键词;同时考虑了用户和产品特点对最终情感倾向的影响。
word-level User Product Attention
- 上面每个句子经过LSTM后得到了一系列的hidden state
[hi1,hi2,...,hili] ; - 在利用这一系列hidden state得到sentence representation时,并不是利用average pooling操作,而是根据下式得到:
si=∑j=1liαijhij
- 上式中
αij
代表一句话中每个词的权重,表示为:
αij=exp(e(hij,u,p))∑lik=1exp(e(hik,u,p))
- 上式中u和p分别是用户(user)和产品(product)所映射到的连续实数空间中的向量,e则是衡量每个单词在这句话中重要性的score function,表示如下:
e(hij,u,p)=vTtanh(WHhij+WUu+WPp+b)
其中 WH,WU,WP 是权重矩阵; v 是权重向量。
- 上面每个句子经过LSTM后得到了一系列的hidden state
sentence-level User Product Attention
- sentence-level的attention机制和word-level的类似,表示如下:
d=∑i=1nβihi - 用 β 来表示句子在整个document中的权重,而不再用average pooling操作来获得整个document的表示。
情感分类
经过上述流程得到的document representation是文本的高维特征,可以将其作为情感分类的特征。
- 先用非线性映射将特征
d
映射到C类的目标空间:
d^=tanh(Wcd+bc) - 再用softmax函数进行分类:
pc=exp(d^c)∑Ck=1exp(d^k)
其中 C 是类别数,pc 是属于类别 c 的概率; - 训练时,采用交叉熵作为损失函数:
L=−∑d∈D∑c=1Cpgc(d)⋅log(pc(d))
其中 pgc 是ground truth, D <script id="MathJax-Element-34" type="math/tex">D</script>是训练数据.
5 模型分析
- UPA机制对于模型性能都有提高,其中user信息对模型性能提高更多;
- 在word level和document level加入attention机制,都能提高性能,其中word level的提高要更显著,可能原因是因为document主题多变,attention机制不容易抓住重点;
- 排除了长度对于模型的影响,模型在各种长度的document上都有提升。
6 未来展望
- 注意利用user和product的profile信息;
- 尝试将模型用在aspect level sentiment上。
注:给定一个句子和句子中出现的某个aspect,aspect-level sentiment的目标是分析出这个句子在给定aspect上的情感倾向。
例如:great food but the service was dreadful!
在aspect “food”上,情感倾向为正,在aspect “service”上情感倾向为负。Aspect level的情感分析相对于document level来说粒度更细。
本篇博客主要参考自
《< Neural Sentiment Classification with User and Product Attention>学习笔记》- 先用非线性映射将特征
d
映射到C类的目标空间:
- sentence-level的attention机制和word-level的类似,表示如下:
- 将上一步得到的sentence向量表示















 3171
3171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









