









下图是keras关于flatten的描述
在深度学习中,flatten对batch size没有影响
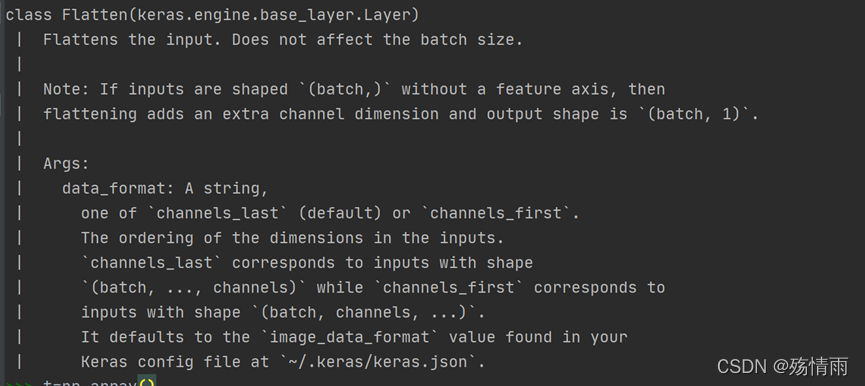
那在深度学习中,flatten函数的输入常常是多维的,里面的数据是按照什么方式展开的呢?
下面举例说明
对于(1,3,4,2)的数据,其中1代表着 batch size
input
array([[[[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8]],
[[ 9, 10],
[11, 12],
[13, 14],
[15, 16]],
[[17, 18],
[19, 20],
[21, 22],
[24, 24]]]])
之前一直以为flatten是先在各个通道上,比如先把2个通道上的3×4维数据展开,再把2个维度上的接在一起
实际上是从最后一个维度2开始,由内而外,先把最里面的4个1*2的展开,得到(1,2,3,4,5,6,7,8),然后再继续往后把“3”这个维度上的其他数据续上
从上图可以看出,这样的展开方式,其实也是符合我们的视觉感官的
keras.layers.Flatten("channels_last")(input)
<tf.Tensor: shape=(1, 24), dtype=int32, numpy=
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 24, 24]])>
torch.flatten(torch.tensor(input))
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 24, 24], dtype=torch.int32)
无论是keras 还是torch中的flatten函数,其默认展开逻辑都是相似的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









