









数据挖掘任务分为:模式挖掘、描述建模、预测建模。上面有一篇文章讲的是Apriori算法,用于数据挖掘的第一个任务模式挖掘。本文介绍数据挖掘在预测建模上的应用。预测建模是指根据现有数据先建立一个模型,然后应用这个模型来对未来的数据进行预测。
1、概念
1.1 Classification和Prediction
Classification主要用于对离散的数据进行预测,分为两步:首先根据训练集,构照分类模型(训练集中每个元组的分类标号事先已经知道);然后估计分类模型的准确性,如果其准确性可以接受的话,则利用它来对未来数据进行分类。Prediction构造、使用模型来对某个样本的值进行估计,例如预测某个不知道的值或者缺失值,主要用于对连续或有序的数据进行预测。
1.2 Supervised vs Unsupervised Learning
Supervised learning (classification): Supervision, the training data (observations, measurements, etc.) are accompanied by labels indicating the class of the observations. New data is classified based on the training set. Unsupervised learning (clustering): The class labels of training data is unknown. Given a set of measurements, observations, etc. With the aim of establishing the existence of classes or clusters in the data.
解释分类和聚类的例子:
分类:两岁宝宝,给他看几个水果,并告诉他:红的圆的是苹果,橘黄的圆的是橘子 (建模型)。拿一个水果问宝宝:这个水果,红的圆的,是什么?(用模型)
聚类:两岁宝宝,给他一堆水果,告诉他:根据颜色分成两堆。宝宝会将苹果分成一堆,橘子分成一堆。假如告诉他:根据大小分成3堆,则宝宝会根据大小分成3堆,苹果和橘子可能会放在一起。
2、Classification的两个步骤
(1)模型构造阶段(describing a set of predetermined classes)
假定每个元组/样本都属于某个预定义的类,这些类由分类标号属性所定义。用来构造模型的元组/样本集被称为训练集(training set)。模型一般表示为:分类规则,决策树或者数学公式。
(2)模型使用阶段(for classifying future or unknown objects)
首先估计模型的准确性:用一些已知分类标号的测试集和由模型进行分类的结果进行比较,两个结果相同所占的比率称为准确率。测试集和训练集必须不相关,如果准确性可以接受的话, 使用模型来对那些不知道分类标号的数据进行分类。

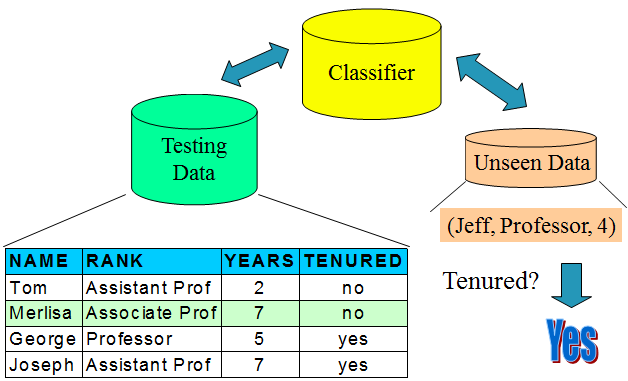
图1 模型构造阶段 图2 模型使用阶段
3、分类和预测相关问题
3.1 数据预处理
(1) 数据清洗:对数据进行预处理,去掉噪声,对缺失数据进行处理(用某个最常用的值代替或者根据统计用某个最可能的值代替)
(2) 相关分析(特征选择):去掉某些不相关的或者冗余的属性(如银行进行贷款信誉评估时不需要考虑属于一周的某一天)
(3) 数据转换:对数据进行概括(如将连续的值离散成若干个区域,将街道等上升到城市);对数据进行规范化,将某个属性的值缩小到某个指定的范围之内。
3.2 对分类方法进行评价
(1) 准确性:分类准确性和预测准确性
(2) 速度:构造模型的时间 (训练时间)和使用模型的时间 (分类/预测时间)
(3) 鲁棒性:能够处理噪声和缺失数据
(4) 可伸缩性:对磁盘级的数据库有效
(5) 易交互性:模型容易理解,具有较好的洞察力
4、基于决策树的分类方法
4.1 引例


图3 训练集 图4 根据训练集得到的决策树模型
4.2 决策树算法
(1) 基本算法 (贪婪算法)
由上到下,分而治之,递归构造树。开始时,所有的训练样本都在树根,属性都是可分类的属性(如果是连续值的话,首先要对其进行离散化)。根据选择的属性,对样本递归地进行划分。在启发式或统计度量(如 information gain)的基础上选择测试属性。(在决策树各个分支上选择属性时,也要采用和在决策树根选择属性一样用信息增益等方法选择划分属性。)
(2)停止划分的条件:某个节点上的所有样本都属于相同的类、所有的属性都用到了(这时采用多数有效的方法对叶子节点进行分类)、没有样本了。
(3) 属性选择方法:信息增益(Information Gain)

图5 Information Gain计算方法
(4) 信息增益的计算举例

图6 计算信息增益的例子
4.3 Extracting Classification Rules from Trees
决策树中所蕴含的知识可以表达成IF-THEN规则的形式,从根到叶的一条路径生成一条规则,路径上的属性值由AND连接起来,构成IF部分,叶子节点构成THEN部分,指出所属的分类,这样的规则易于被人们所理解。下面是一个例子

图7 Extracting Classification Rules from Trees
5、决策树算法的相关问题
5.1 Avoid Overfitting in Classification
Overfitting:有些生成的决策树完全服从于训练集,太循规蹈矩,以至于生成了太多的分支,某些分支可能是一些特殊情况,出现的次数很少,不具有代表性,更有甚者仅在训练集中出现,导致模型的准确性很低。
通常采用剪枝的方式来克服 overfitting,剪枝有两种方法:
(1) 先剪:构造树的过程中进行修剪。不符合条件的分支则不建。
(2) 后剪:整个树生成之后进行修剪。
5.2 Computing Information-Gain for Continuous-Value Attributes
假设属性A是一个连续值属性,需要找到一个好的划分点,对A进行划分:将A的所有值按升序排序,一般来说,两个连续点的中间值可以考虑作为划分点((ai+ai+1)/2 是ai和ai+1的中间值)。划分:D1 表示D中满足条件A ≤ split-point的值的集合, D2表示 D中满足条件A > split-point的元组的集合。
5.3 Gain Ratio for Attribute Selection

图8 Gain Ratio for Attribute Selection
5.4 Classification in Large Databases
Classification—是一个老问题,统计和机器学习的研究人员已经对其进行了广泛的研究。Scalability是数据挖掘过程中不可忽视的问题,要求采用比较合理的速度对具有上百万样本和上百个属性的数据集进行分类。数据挖掘领域为什么采用决策树呢?和其他分类方法相比,决策树的学习速度较快;可以转换成简单的、易于理解的分类规则;可以采用SQL查询访问数据库;具有较高的分类准确性。
5.5 Scalable Decision Tree Induction Methods
(1) SLIQ (EDBT’96 — Mehta et al.):为每个属性创建一个索引,内存中只放分类列表和当前属性列表。
(2) SPRINT (VLDB’96 — J. Shafer et al.):构造了一个特殊的属性列表数据结构 。
(3) PUBLIC (VLDB’98 — Rastogi & Shim):将建树和剪枝结合起来进行,尽早停止树的生长。
(4) RainForest (VLDB’98 — Gehrke, Ramakrishnan & Ganti):维护了一个AVC-list (attribute, value, class label)结构。















 2830
2830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









