






一、存取
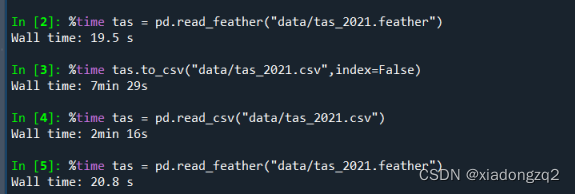
对于大量的数据,feather远比csv或txt快。
二、计算



很多文章推荐的 df['new'] = df.apply(lambda r:r['a'] + r['b'],axis=1) , 语法上没问题,但数据量一大,速度感人。强烈不推荐。
如果真的习惯了这个写法,建议用 swifter ,这个经实测确实有用。
eval 是本次测试发现的惊喜。编写简单,可读性强,速度也不错。后面在筛选中也会看到eval的身影。
三、筛选

如果筛选条件不复杂,直接用pandas原生的 df[df.A>1 & df.B<33] 就可以。
但如果有一定的计算,比如abs 、max 、min等, lambda 和 eval的效率差不多。














 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









