









前言
相信大家使用完pandas一段时间之后,多多少少会去寻找使得当下数据处理过程效率更高的方式或者方法,那么在大规模的数据之间完成一些操作,我们往往会浪费大量的时间,为了充分的利用软硬件资源,演化出了2种主流的优化方式,分别是 向量化 和 并行化 。今天要给大家介绍的一款工具 swifter 就是综合使用了这2中方式。
swifter 简介
swifter 是一款用于给使用在 pandas DataFrame 或者 Series 上的 function 进行加速的包。
使用的话也很方便,直接命令行安装即可:
pip install swifter
然后在使用前导入:
import pandas as pd
import swifter
如果在导入swifter之前你先导入了modin,而且想在modin上使用swifter,那么你需要进行注册:
import modin.pandas as pd
import swifter
swifter.register_modin()
swifter的简单使用:
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func,
positional_arg, keyword_arg=keyword_argval)
那么 swifter 具体是如何做到高效率的呢?
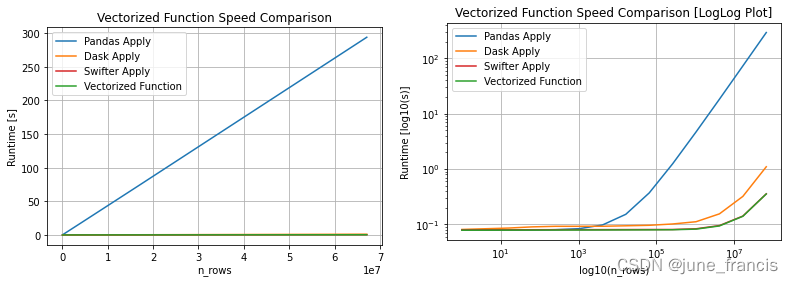
1、它会判断apply中的函数是否能被向量化(vectorization),如果可以,那么他就会自动选择向量化后函数的进行应用(此时是效果最好的),下图是向量化后不同操作随着处理的数据集规模的增加时的效率对比:
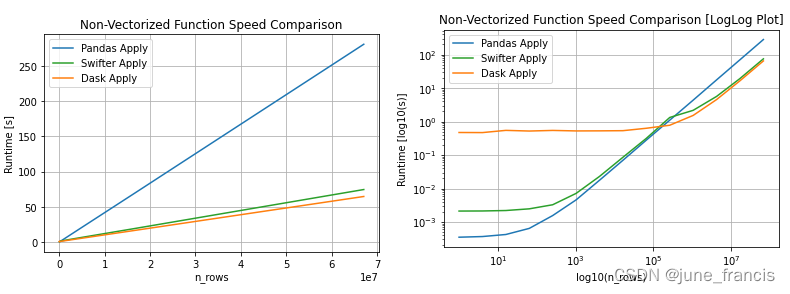
2、如果apply的函数无法向量化,则自动选择使用 dask parallel processing 和 simple pandas apply 中较快的一种,下图是在不向量化的前提下各操作方法随着数据集规模的增加时的效率:
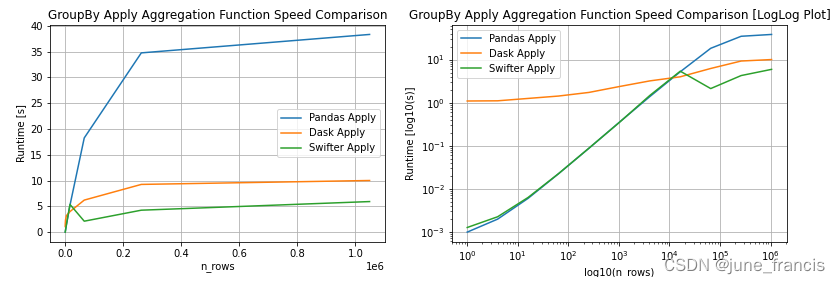
3、在分组apply的场景下,swifter也能达到更好的效果:
当然了,并行化在小规模的数据集上可能达不到预期的效果,所以并行化操作是根据应用场景酌情使用的,而向量化不管数据集规模的大小都能带一些性能的提升,如下图所示:
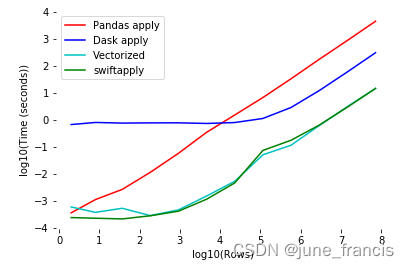
从上图中我们还可以看出当数据集规模达到某个阈值(红线和蓝线交点的横坐标)时,可以指导我们对是否使用并行化给出一些提示。

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









