







 本文详细介绍了sklearn.preprocessing.RobustScaler的原理,它使用百分位数进行数据缩放,不受极端值影响。通过示例展示了如何使用该工具并探讨了其在处理少量数据时可能产生的差异。
本文详细介绍了sklearn.preprocessing.RobustScaler的原理,它使用百分位数进行数据缩放,不受极端值影响。通过示例展示了如何使用该工具并探讨了其在处理少量数据时可能产生的差异。
提示:sklearn.preprocessing.RobustScaler(解释和原理,分位数,四分位差)
提示:以下是本篇文章正文内容,下面案例可供参考
一、RobustScaler 是什么?
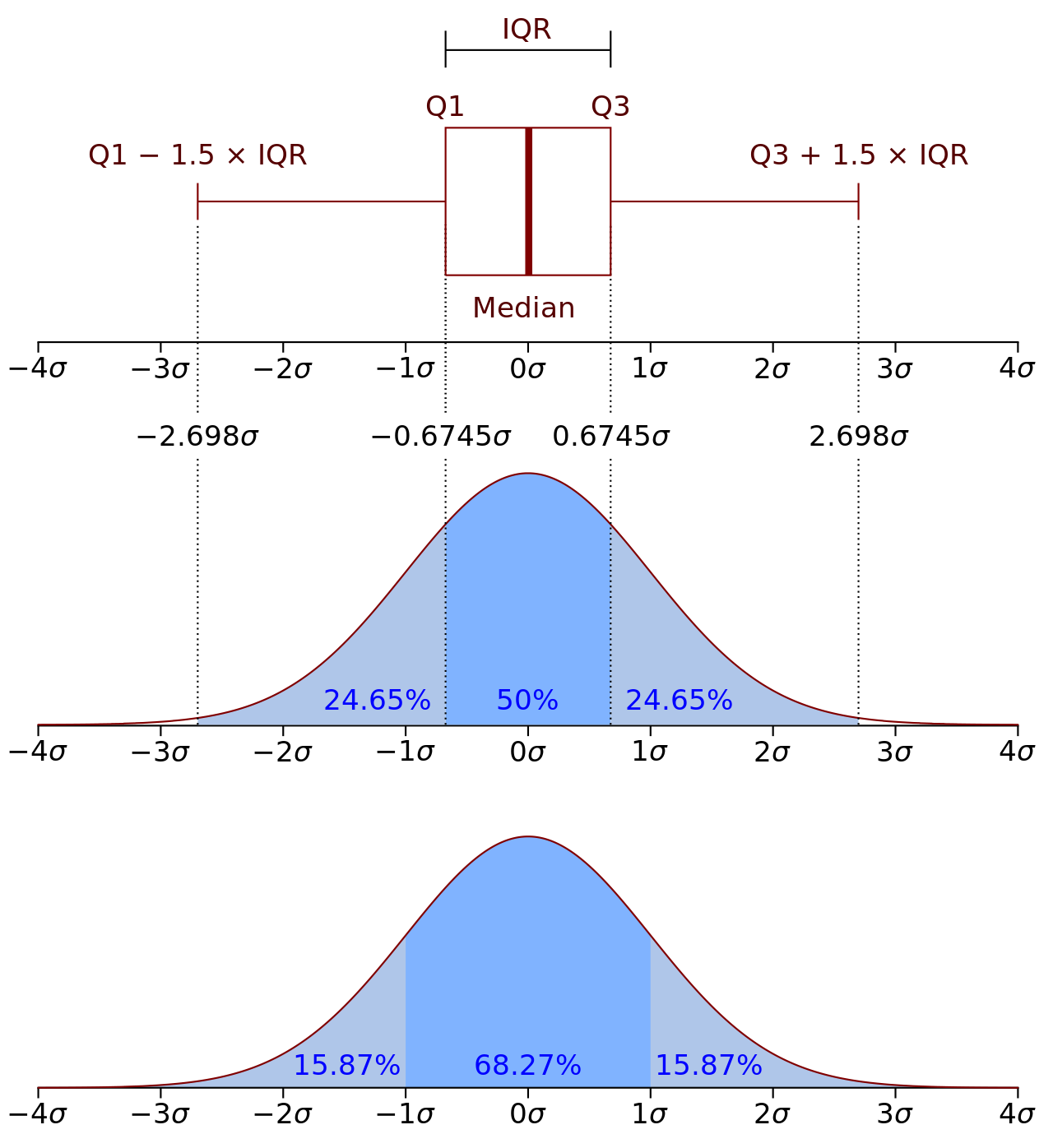
RobustScaler 的居中和缩放统计基于百分位数,因此不会受到少数非常大的边缘异常值的影响。
计算公式如下(具体计算公式以官网提供的代码为准):
value_result = (value-Media)/(Q1-Q3)
Q1的位置 = 1 * (n + 1) / 4
Q3的位置 = 3 *(n + 1) / 4
n : 表示数据的个数。
media : 中位数
Q1 : 是第 1 个四分位数(第 25 个分位数)
Q3 : 第 3 个四分位数(第 75 个分位数)
二、代码
1.代码
import pandas as pd
from sklearn.preprocessing import RobustScaler
data = pd.DataFrame(
{
'a': [1, 2, 3, 4, 6, 5, 6],
'b':  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









