







LLM-Microscope: Uncovering the Hidden Role of Punctuation
in Context Memory of Transformers
一句话总结
作者通过制作一些模型内部观测指标,发现了一个现象:句子里面的限定词、介词和标点符号承担了存储上下文信息的职能,且这类token在模型内部的hidden很容易用线性模型进行层与层之间的映射。
要点检录
整体上作者对LLM的token及其在模型中的对应hidden做了一些观察指标,具体有
- 非线性指标( Token-level Nonlinearity):序列中的某个oken,从第l层 的hidden到第l+1层的hidden之间,能不能用一个线性函数来拟合?拟合误差就是非线性指标
- 上下文信息包含量( contextualization score):序列中的某个token,能否还原出他前面序列的内容?还原误差就是 contextualization score
- 中间层预测能力:预测误差和logit length(Logit Lens原方法)
- 内维度(Intrinsic Dimension of Representations):一种间接描述表征空间距离形态的尺度
针对1 & 2 有充分的实验和结论,针对3 描述的就比较草率(有一种赶着下班的散漫感)针对4 没找到具体实验和相关结论。毕竟作者是提供了个分析工具,3 & 4是分析工具的一部分,但作者没有获得有意思的观察。
【针对2的结论1】一个句子中的限定词(a ,the),介词(of,on等) 和标点符号的包含的上文信息比名词、形容词等其他带有自己含义的词都多。
【针对2的结论2】包含上文信息越少的token的非线性程度越高,或者说,包含上下文信息较多的token的hidden在层与层之间的线性程度越高。(这点我有点怀疑)
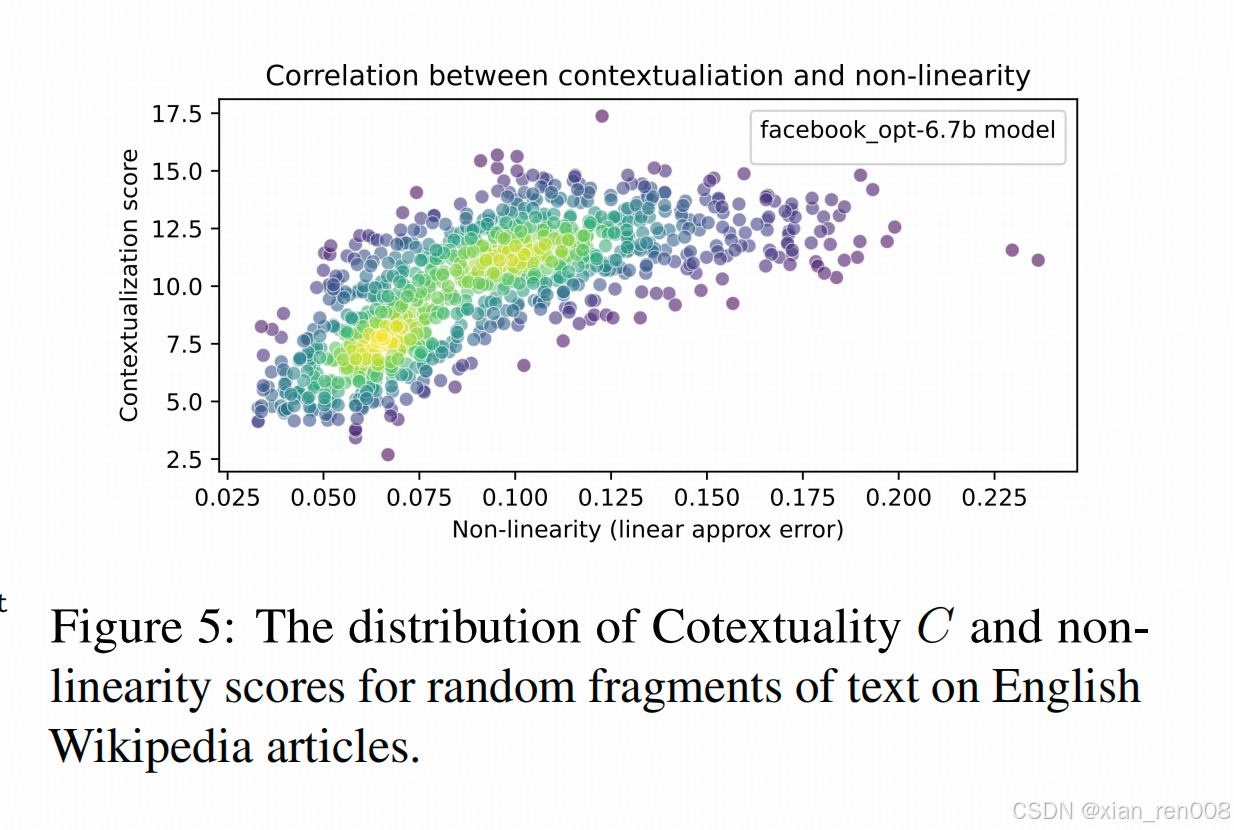
一些读的过程中产生的问题
- 作者认为 Token-level Nonlinearity 越大越能体现什么特性?
Token-level Nonlinearity 越大,说明一个 token 在模型内部的表示越难以用线性变换来近似,即模型在处理该 token 时涉及更复杂的非线性运算。
这表明该 token 在模型中扮演着更重要的角色,可能包含着更丰富的语义信息或上下文信息,对模型的理解和推理起着关键作用。
- Contextual Memory in Token-Level Representations 是什么东西? 怎么算?
简单的说就是token表征中存储的上文信息。
怎么算的呢?
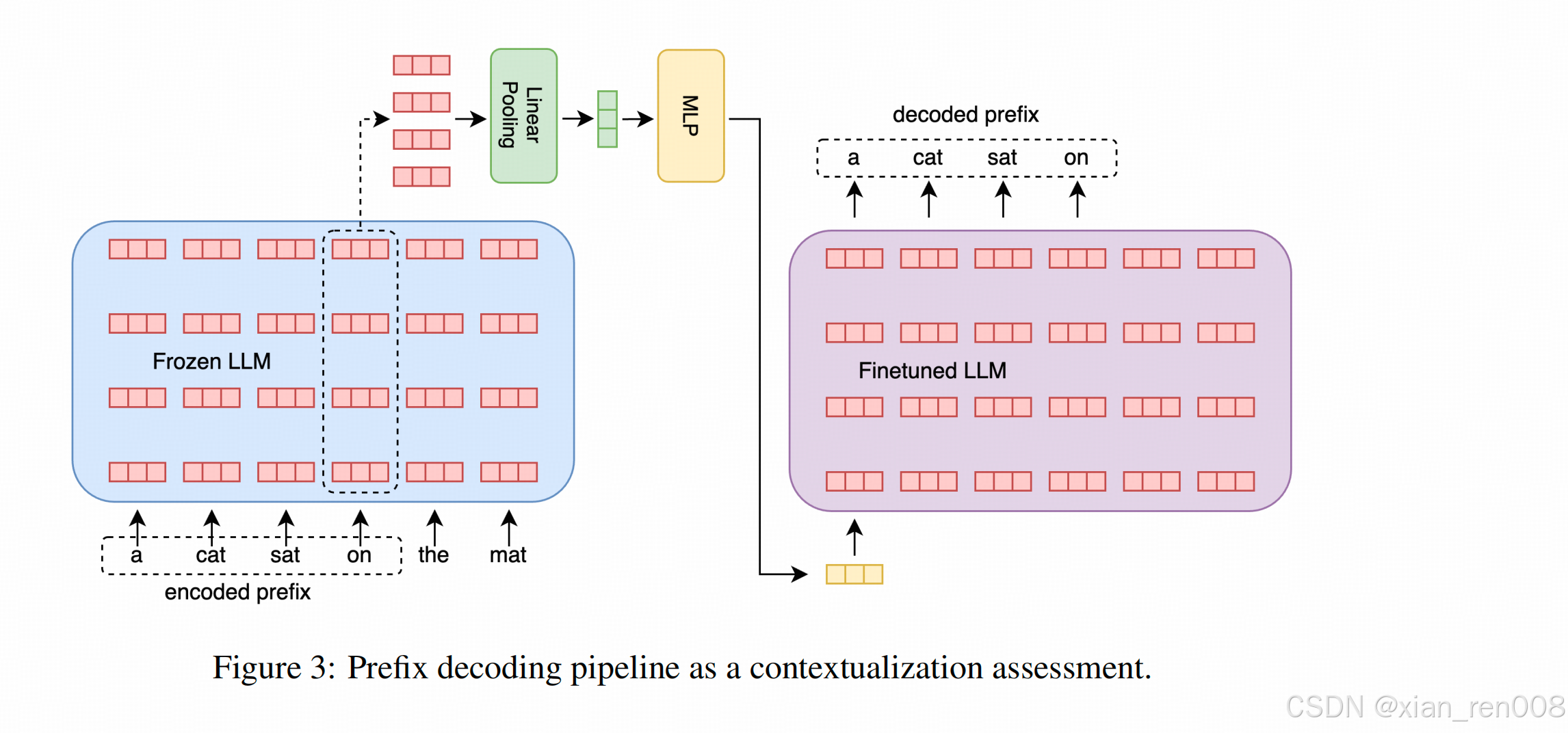
原文的图解释的比他文字写的清楚(我相信作者未来要上会还是会改进文字表述的……)
就是
先把同一个token的每层输出都拿出来用MLP压缩回一个token的维度
--> 然后把这个token输入到原模型的副本当中,并训练这个副本
--> 这个副本模型的loss类似于LM的loss,只不过decode的目标变成了上文。
--> 实际分析的过程中,再用重构上文的embedding和实际上文算PPL。
- 谁存上文信息最强呢?

这三类词的上下文重建能力最强,作者认为包含的上下文信息做多。大部分模型都有类似现象。 - token包含的上文信息越多,他的层与层之间的线性程度越高这个真的成立吗?
首先,我有没有会错意?因为作者写作的时候关键措辞来回变换,导致我反复读了几遍之后还是求助了deepseek帮我澄清一下(本来的速读变细读了),看看我是不是理解错了,但就deepseek的分析过程而言,他读的过程跟我一样累
deepseek的结果是:
根据论文第4.3节和关键定义的分析:
1. **重建误差(Contextualization Score, \( C_i \)**:
- \( C_i \) 越小,表示模型重建前缀的能力越强(损失小),token 的上下文信息越丰富。
- \( C_i \) 越大,重建能力越差(损失大),上下文信息越少。
2. **线性映射误差(Nonlinearity Score, \( E^l_i \)**:
- \( E^l_i \) 越小,表示相邻层间的变换越接近线性(线性程度高)。
- \( E^l_i \) 越大,变换越非线性(线性程度低)。
### 核心发现:
- 文中明确提到:
> "tokens with high contextualization tend to correspond to the most linear transformations"
(上下文化程度高的 token 对应最线性的变换)。
即 **\( C_i \) 越小(高上下文)时,\( E^l_i \) 也越小(高线性)**。
- **表2中的 Pearson 相关系数均为正数**(例如 Opt-6.7b 的相关系数为 0.482),表明 \( C_i \)(重建误差)与 \( E^l_i \)(线性误差)呈**正相关**。
这意味着:
- 当 \( C_i \) **增大**(重建能力差,上下文信息少),\( E^l_i \) 也**增大**(非线性程度高);
- 当 \( C_i \) **减小**(重建能力好,上下文信息多),\( E^l_i \) 也**减小**(非线性程度低)。
### 结论:
作者发现的非线性和重建误差的关系是:
**重建误差越小(\( C_i \) 低,上下文信息多),线性映射误差也越小(\( E^l_i \) 低,变换更线性)**。
尽管表2的相关系数为正,但结合语义描述可知,两者本质上是**负相关**(\( C_i \) 与 \( E^l_i \) 的变化方向相反)。论文中可能因术语定义(如将“线性程度”量化为误差的倒数)导致统计结果呈现正相关,但实际逻辑关系为负相关。
既然没有理解错作者的意思,那作者的这个观点solid吗?
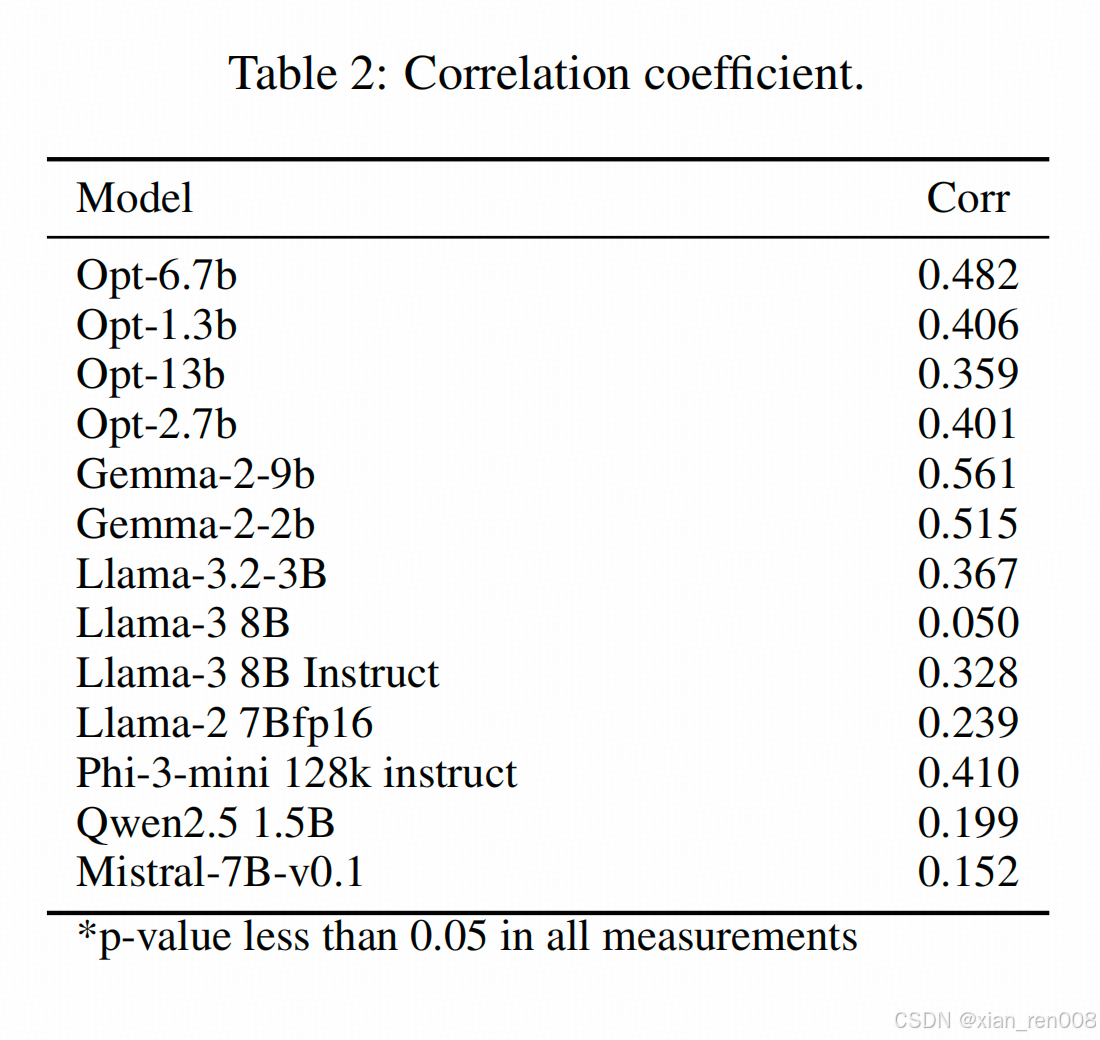
- 从他论文提供的数据出发,其实这种共相关关系并不强,最高的Gemma在0.56左右,这个也就是看起来有点像直线的程度,就上面那个scatter图,如果作者没有标成高亮绿,人也可以认为近似为一个横线(就是没啥关系);
- 如果是稳定的性质,那么在LLama3的Base和Instruct上就不应该出现那么大的差异,毕竟这是个机制问题。
- 我们来分析一下层与层之间到底发生了什么
step-1 Attention运算
step-1.1 sdp-attention:1次Q的线性映射-->QKV 运算
step-1.2 output_proj :一次线性映射 -->加上residual(即上一层的hidden)-->norm
step-2 intermediate: 一次线性映射--> 一次activation
step-3 output_proj::一次线性映射 -->加上residual(即上一层的hidden)-->norm
已知对所有token而言:
其一、前面的Q的线性映射 和 后面的 output_proj这些操作参数全部是相同的,且是线性的。
其二、step-2 intermediate 这里的activation是非线性的,但对所有token都一样。
所以针对token级别的层与层之间的非线性只能来自QKV的Attention运算过程中,而这个过程中最有可能扭曲hidden方向的,恰恰就是来自其他token的信息汇总(因为汇总之后,还会过softmax,这样就不再是线性的变化了)
那也就是说,汇总了更多信息的token反而跟原有的表征 用线性关系表达???
如果作者观点 ——标点符号等token包含了更多的上文信息(这个是比较站得住脚的)和 包含上下文信息的程度和层之间存在很小的线性复原误差 这两项同时成立。就只有两种(实验错误以外的)解释:
一种是,标点符号这类token的表征的表达足够强,即便是跟上文QKV过之后,也仍然是本token的原始表征的表达更强。所有的上文信息都存储在本token表征的残差里。
另一种是,在最开始的一层,标点符号这类token就已经融合了比较强的上下文信息,而且逐层在同一个方向上累加。(换言之,意味着transformer中间层的表达异议不大,锦上添花而已)。
但第二种是有其他观点反驳的,一个是早有研究观察过transformer中间各层的能力不同(对应文章找不到了),另一个是模型越深他的逻辑能力越强的原因也来自于中间多层的信息交换。
所以更有可能的是第一种,这个在我的两个本地实验当中有一些可支撑的论据:
论据1:早年在训练表征模型的时候我做过这样一个观察,在数据集中出现频次最高且本身异议并不明确的token(标点符号,空格,<SEP>,在样本集中几乎每个样本都会带的token)与大部分token的表征都会更加相似,也就是处于空间的激进中心店的位置。
论据2:在研究特定语义在表征会影响哪些特定维度时,我发现在句尾增加“?”(句子原本也是疑问句)会给1/5的hidden_dim带来正负超过3e-3的影响。(从表征相似的角度而言,这个影响已经不算小了。)这也就是说,上下文的语义会储存在特定维度的残差上。
即便是这样,我也只能认为作者做这样的实验总结有合理性,但我还是不想在这个程度的论证上支持作者的观点。
How Much Knowledge Can You Pack into a LoRA Adapter
without Harming LLM?
一句话总结
作者总结的结论不建议采信,但作者的研究思路可以借鉴一部分。
要点检录
- 当训练数据包含已知和未知事实的混合时,学习知识效果最佳
这点不可信的主要原因有两个:
第一个:Lora这种low rank的方法并不适合学习知识。这点我自己idea实验中也验证过—>如果用全参数微调,2个epoch能够保证模型记忆新的知识(新增知识量不大的情况下),Lora的话只能达到过犹不及的效果,即模型会被某条知识的时候,已经是完全僵化的背书了。
第二个:就是作者的训练设置。
这是模型训练参数,我们能看到几个点,第一是Lora的维度过低,第二是epoch过高,第三个事lr过高。这种情况下训练LLM会导致大模型强制背诵。

- 作者的研究方法
把知识分成三种
知识分类是什么意思?
在论文中,“知识分类”是指根据模型对特定事实的掌握程度和回答稳定性,将其知识划分为不同类别。作者定义了三种核心类别:
-->HK(Highly Known):模型稳定掌握的事实(回答正确率≥90%)。
例如:“巴黎是法国首都”这类常识,模型几乎每次都能正确回答。
-->MK(Maybe Known):模型部分掌握的事实(正确率在10%~90%之间)。
例如:“莎士比亚的第一部戏剧是《亨利六世》”,模型可能有时正确,有时错误。
-->UK(Unknown):模型完全未知的事实(正确率≤10%)。
例如:“某冷门科学家的研究成果”,模型几乎无法正确回答。
之所以要这样分类是为了在实验中观察以下变化
通过分类追踪,能明确回答:
微调后哪些知识被强化(如UK→HK)?
哪些原有知识被破坏(如HK→UK)?
哪些知识变得不稳定(如HK→MK)?
- 那训练之后 上面这种知识发生了什么变化呢?
这部分 deepseek已经回答的比较好了
### 一、知识层面的变化
#### 1. **新知识的吸收(UK→HK/MK)**
- **正向知识转移**:当训练数据中包含模型原本未知的事实(UK类别)时,微调能有效提升其正确率(例如从5%提升至80%)。
- *示例*:若模型原本对“量子计算中的拓扑量子比特原理”一无所知(UK),通过针对性训练后,其回答正确率显著提高(变为HK或MK)。
- **局限性**:新知识吸收效率受**数据分布**影响。若训练数据中UK事实占比过低(如<20%),模型可能无法有效学习新知识。
#### 2. **旧知识的遗忘或弱化(HK→MK/UK)**
- **负向知识转移**:模型原有掌握的事实(HK)可能在微调后正确率下降,甚至完全遗忘。
- *实验发现*:当训练数据中混杂大量新知识(UK)时,原有HK事实的正确率平均下降约15-30%。
- *示例*:微调前模型对“地球绕太阳公转周期为365天”回答正确率98%(HK),微调后降至70%(MK)。
- **原因**:新旧知识在参数更新中发生冲突,导致旧知识被覆盖或干扰。
#### 3. **知识不稳定性增加(HK↔MK波动)**
- 部分原有稳定知识(HK)在微调后变得回答不一致(变为MK),表现为对同一问题在不同上下文中的回答时对时错。
- *实验数据*:约12%的HK事实在微调后落入MK区间,表明模型对这些知识的**置信度降低**。
---
### 二、行为层面的变化
#### 1. **回答倾向性改变**
- **过度自信错误答案**:模型更少输出“我不知道”,但对部分MK或UK事实的错误回答置信度提高(错误答案的概率分布更集中)。
- *风险案例*:模型将“拿破仑出生于1768年”(实际为1769年)的错误答案概率从30%提升至85%。
- **答案多样性下降**:模型倾向于重复训练数据中的高频答案模式,即使存在其他合理答案。
#### 2. **实体类型偏好偏移**
- 若训练数据中某类实体(如“历史人物”)占比过高,模型会对该类问题表现更好,但其他类型(如“科学概念”)的正确率可能下降。
- *实验数据*:当“历史人物”类数据占比从10%增至40%时,该类问题正确率提升22%,但“科学概念”类下降18%。
---
### 三、训练策略的影响
#### 1. **数据混合比例的临界效应**
- **最佳平衡点**:当训练数据中HK(已知事实)与UK(新事实)的比例接近**1:1**时,模型在新旧知识间达到最佳平衡,既不过度遗忘旧知识,也能有效学习新知识。
- **极端比例的风险**:
- 若HK占比>70%:模型几乎不学习新知识(UK吸收率<5%)。
- 若UK占比>70%:旧知识遗忘率高达40%。
#### 2. **持续学习与灾难性遗忘**
- **灾难性遗忘**:在单次微调中集中注入大量新知识(UK)时,模型会快速遗忘原有HK事实。
- **缓解方法**:通过**渐进式微调**(分阶段注入新知识,并穿插旧知识复习),可将遗忘率降低50%以上。
---
### 四、关键实验结论
1. **微调并非无害**:即使微调目标与原有知识无关,模型仍可能因参数扰动丢失原有知识。
2. **知识冲突可量化**:通过分类统计(如HK→UK的比例),可提前预测微调对模型可靠性的影响。
3. **动态监控必要性**:仅依赖最终准确率无法反映知识变化的全貌,需持续追踪HK/MK/UK的迁移路径。
---
### 示例分析
假设微调前模型对“水的沸点是100°C”正确率95%(HK),训练数据中混入错误陈述“水的沸点是80°C”(占比30%)。微调后:
- 该问题正确率降至60%(HK→MK),且回答“80°C”的概率从2%升至35%。
- **结论**:错误数据的重复输入会导致模型对原有正确知识产生混淆,甚至输出高置信度的错误答案。
---
### 总结:如何应对这些变化?
1. **数据设计**:平衡新旧知识比例(接近1:1),避免极端分布。
2. **评估指标**:引入知识分类追踪(如HK保留率、UK吸收率),替代单一准确率指标。
3. **风险控制**:对关键知识(如HK事实)进行对抗性测试,确保微调后稳定性。
4. **持续校准**:通过强化学习或知识蒸馏,定期修复被破坏的旧知识。
论文通过知识分类的视角,揭示了微调对模型影响的复杂性,为安全、可控的模型优化提供了方法论基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









