






在之前解读Anthropic团队的模型可解释性论文On the Biology of LLM 的时候,我曾经提过,如果能够找到一种有效的让模型在隐空间中拉长推理链路的方式,可以大大提高模型的推理效率和能力。同时COT也可以被视为一种词增长模型内容推理连读的体外辅助。持有类似观点的团队其实不在少数,所以去年开始也陆续有一些团队尝试了一些直接使用隐空间作为模型推理媒介的方法。
LLM隐空间推理,目前看可能有几个流派
其一:直接使用hidden作为COT推理媒介的
其二:把Transformer改装成RecurrentGPT的
其三:基于特殊token的(这个派系还没看,看完了回补这部分描述)
本篇先介绍一下,第一个流派的最主要工作,Coconut,及其异父异母的亲小弟 CODI。
Training Large Language Models to Reason in a Continuous Latent Space
一句话总结
这个工作中,作者直接使用LLM的最后一层生成位的hidden_state作为推理token,用以替换COT中离散的推理句子,把生成50个token的事变成生成2个token的事。
啊对,Coconut是Continuous Chain of Thought 硬凑的。
这个方法的效果如何?–> 没有做到等效替换,但在推理路径的explore上比离散COT强。
<最后一层>的<生成位>的hidden_state 是怎么用的?
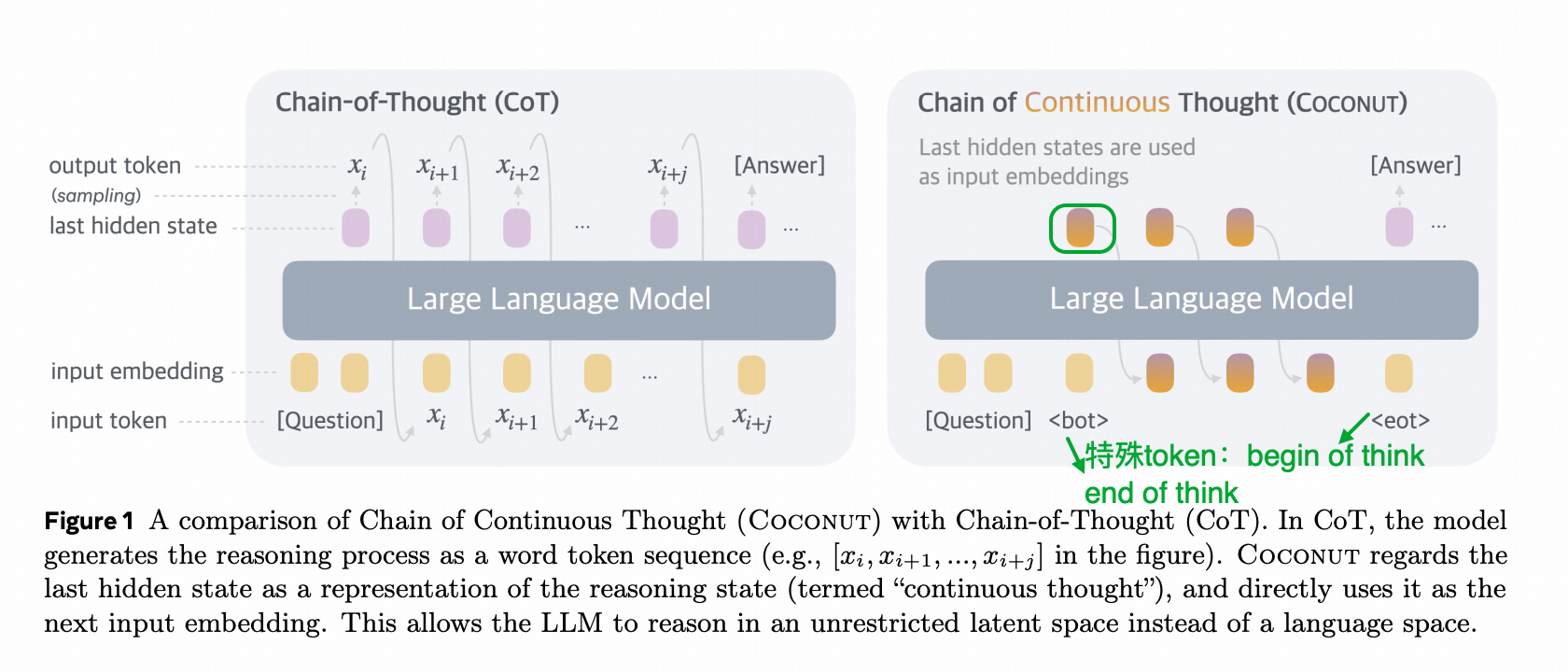
像其他推理模型一样,使用了<think>token来框住think的过程;
不同的是中间框住的think过程不再是人类文字,而是hidden_state。
关键细节
1. 怎么推理的
要设置两个超参数 :
推理步骤–> k 和每步的连续推理token的个数–>c
给定问题后,先插入<bot>token,然后把<bot>对应位置的last hidden 作为连续推理token传入下一步生成的query序列,生成k*c个连续推理token之后,强制插入<eot>,恢复到自然语言答案生成的状态,生产答案。
2. 怎么训练的

- stage 0:训练模型生成离散COT
- stage 1:把COT中的第一步替换成1*c个连续推理token,计算没替换部分COT的LM loss
- stage 2:把COT中的第二步也替换成1c 个连续推理token,这样现在推理链路中就有2c个连续推理token,计算剩余没替换部分离散COT的LM loss
- 继续,直到 k步。
这里正文里没有说 什么叫COT的第一步,第二步,实际上这个多长算一步推理是自定义的,可以看一下文章附录:
对于数学题,就是一次计算一步,对于三段论的推理,就是 A->B->C 算一步。

3. 效果怎么样
很难评↓
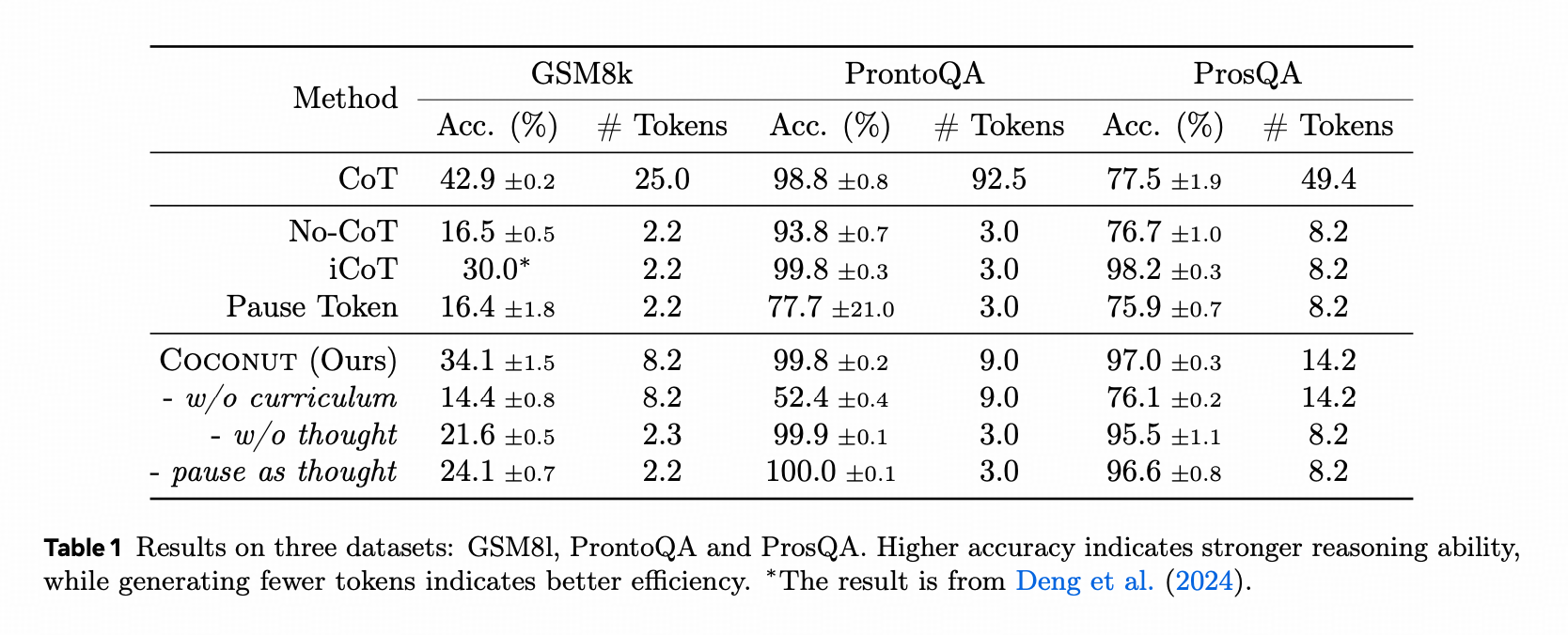
一来,数学问题上和离散COT差的还比较多
二来,三段论的问题上(ProntoQA)其实和其他方法,尤其是连COT都没有的直推差距也不大
三类,在图推理(ProsQA)上比离散COT强
跳出作者的写作视野,我其实觉得这些推理题都有一些toy sample 的意思,这上面尚没看出优势。就只能捡一些在特殊场景来分析这种做法的优势了。
4. 核心优势——利用了Transformer的特征堆叠效应,在路径搜索上展现出了比离散COT更强的弹性。
从3的实验结果看,比较值得分析的就是为什么在ProsQA上,Coconut 比离散COT强。
当然也得说,这里的推理都没有使用蒙特卡洛树搜索等能够强化COT explore能力的方法,所以在这个问题上看起来比较强。
当然,整篇文章中,最有看头的其实就是下面这张图↓
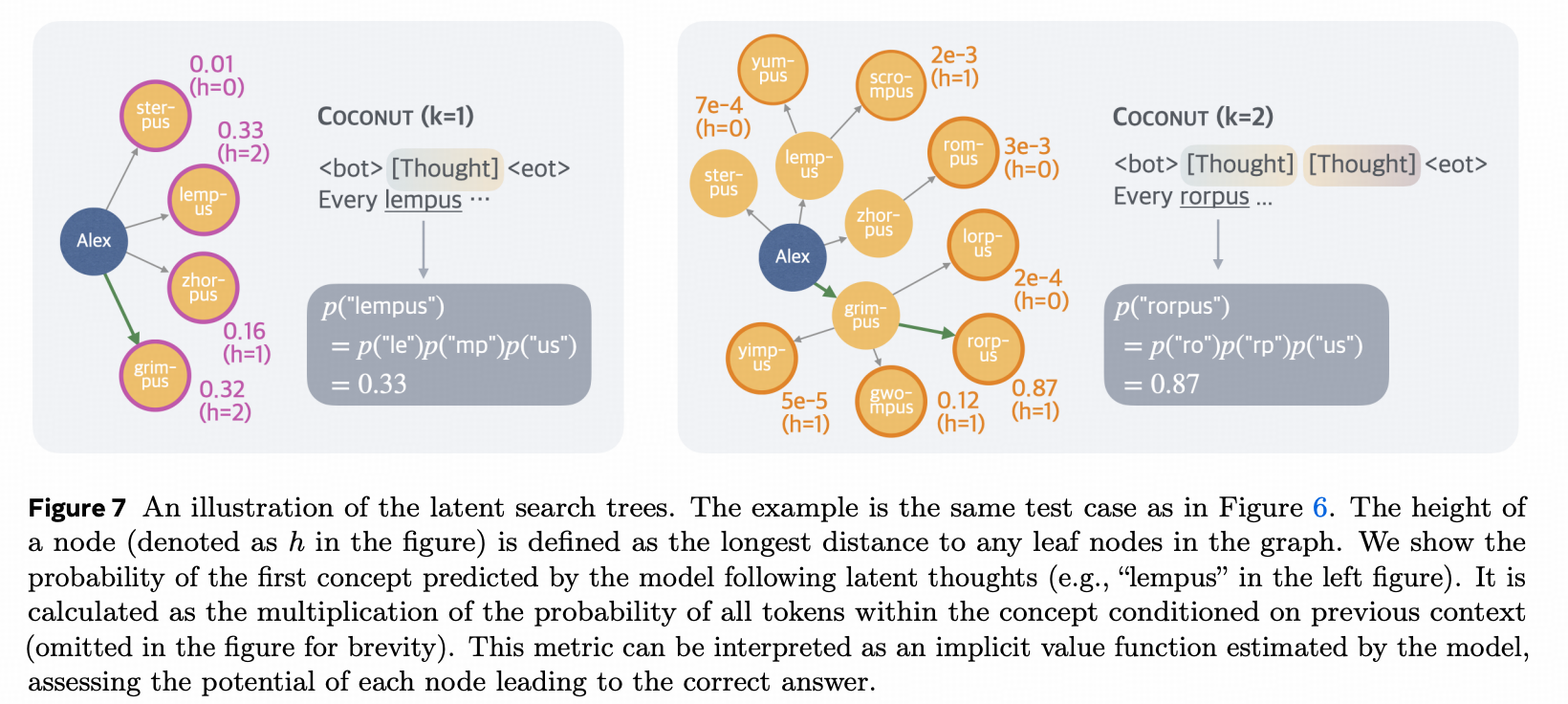
要解释Coconut的结果为什么比离散COT强,就得把Coconut的连续过程离散化,变得可读,才能可分析。
先解释一下上图中左图 <bot>[Thought]<eot>和右图中 <bot>[Thought][Thought]<eot> 的差别。为了能够直观的看到生成一步连续推理token之后,模型的推理进度,作者在解释ProsQA上为什么Coconut比离散COT强的时候,采取了先让连续推理token生成一步,然后看看模型后续会生成什么推理的方法。由此也就看到了上图左图中模型第一个连续推理token生成之后,强制回到生产自然语言。观察lempus这个token的位置上的last hidden 和词表中其他词作比较,算出starpus等词的概率分别是多少。右图的呈现逻辑与左图相似,只是让模型生成两个连续推理token之后,观察生成词的概率
评价
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
一句话总结
这篇文章的推理过程仅比Coconut多一层MLP映射。重点差异在于训练过程使用了自己COT的结果做蒸馏
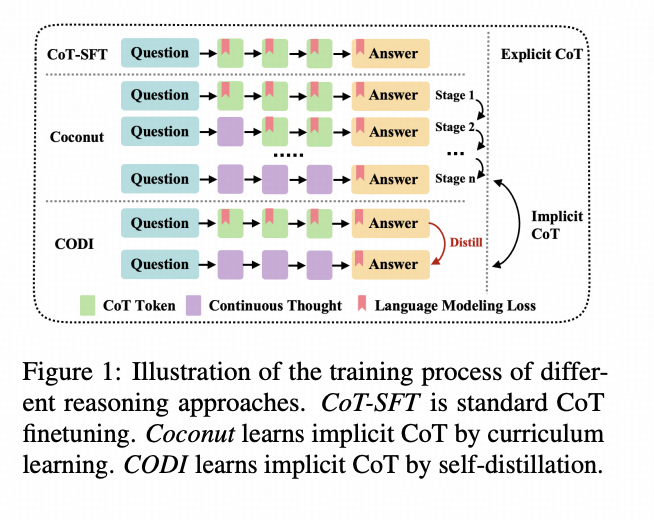
关键细节
1. 在输出层hidden后增加了一层MLP
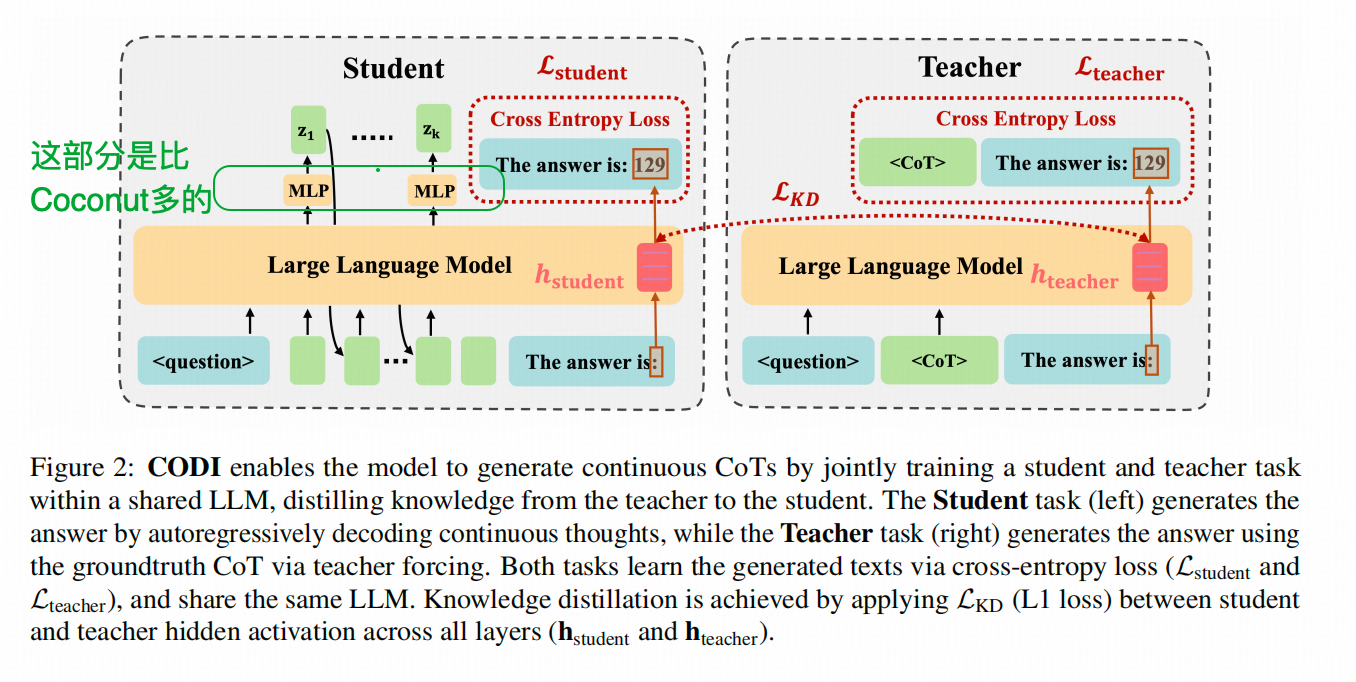
上图在这个点上,画得很清楚。
其实Coconut在这个方面其实确实是有一定问题的,通过 on the biology of LLM 的这篇分析,我们其实知道,LLM在内部运算的过程中,会经历一个特征的演化,最接近输出层的hidden里带的特征更接近于生成某个字的这类特征,而推理需要的概念特征,其实是在LLM的中间靠后的层里的。所以,直接把这些hidden直接回传回输入层,可能信息量并不足够多。
当然,CODI这篇文章的这个做法也很难说是解决了这个问题。
2. Distill 是怎么做的
本文比较好的就是直接把代码贴出来了,其实比文字描述写的清楚多了。
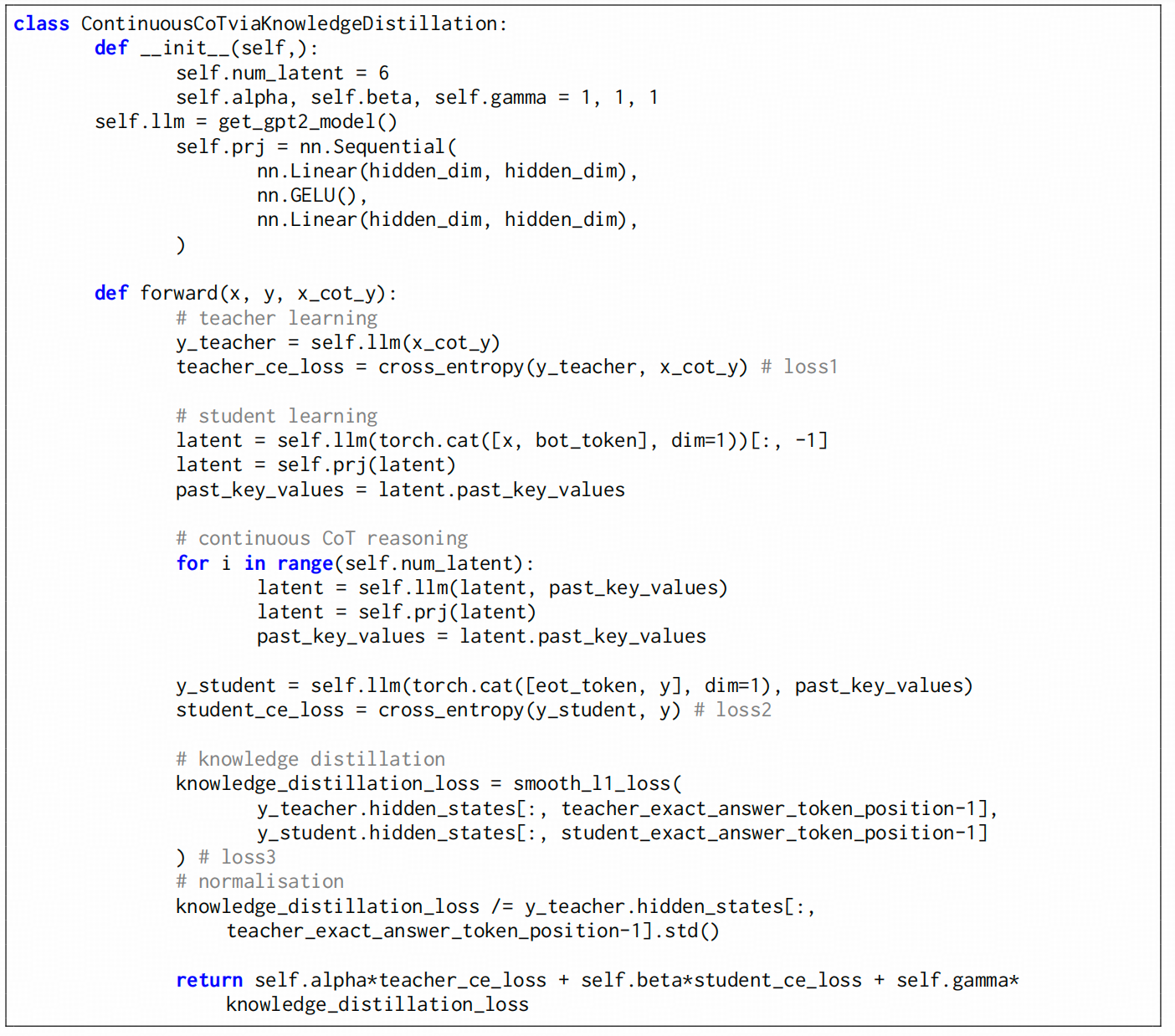
简单描述一下步骤:
第一步,用离散COT数据作为标签输入LLM,获得一个LM loss,即 teacher_ce_loss;
第二步,用问题+<bot>这个token 逐步生成n个连续推理token(每个token都经过了self,prj的映射)
第三步,同第二步的连续推理token生成一个答案token,和真正的y算 cross-entropy loss ,作为student loss
第四步,算LLM在生成teacher的y的过程中的特定位置,和LLM生成student的y的过程中的特定位置(冒号这个位置)的last_hidden 算 l1 loss ,作为distill loss
3. 效果怎么样
因为要训练,而作者好像训练资源比较不够,所以用的都是賊小的模型,同时也没有充分比较Coconut
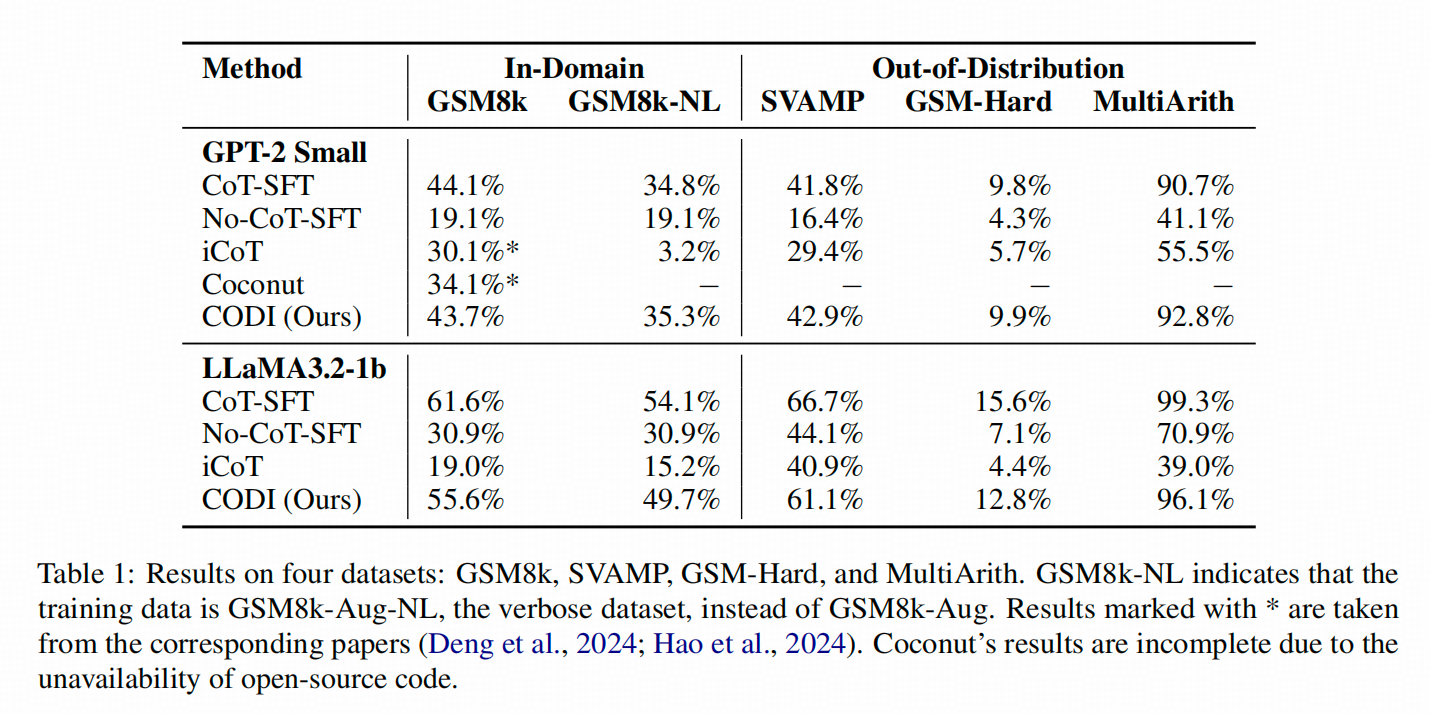
简单的说,就是还没达到match离散COT的水平。
评价
这类方法其实非常直给,思路我很欣赏
我这样的庸人(数学系垫底)在尝试解决问题的时候,需要依靠一个有完整分析框架,大部分时候是把问题拆解明白了,甚至因果关系都捋顺了之后,才能顺理成章的找到解决方法。但是,单就发现解法和选择解法走的路径上而言,我这么多年都在被乱拳打死老师傅
-
这类方法需要改造的第一个问题就是把使用LLM的最后一层hidden,变为使用多个LLM高层的hidden。或者更理想的状态,是中间层开始COT(当然,后面我们会看到,使用这个思路的Recurrent流派的弱鸡的一面)
-
CODI这种自蒸馏的方式,算是LLM蒸馏方式的一种,但是,训练逻辑上Coconut的其实逻辑更顺,更适合在语言模型上扩展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









