






1.申请阿里云积模型账号
进入阿里云,搜索灵积模型服务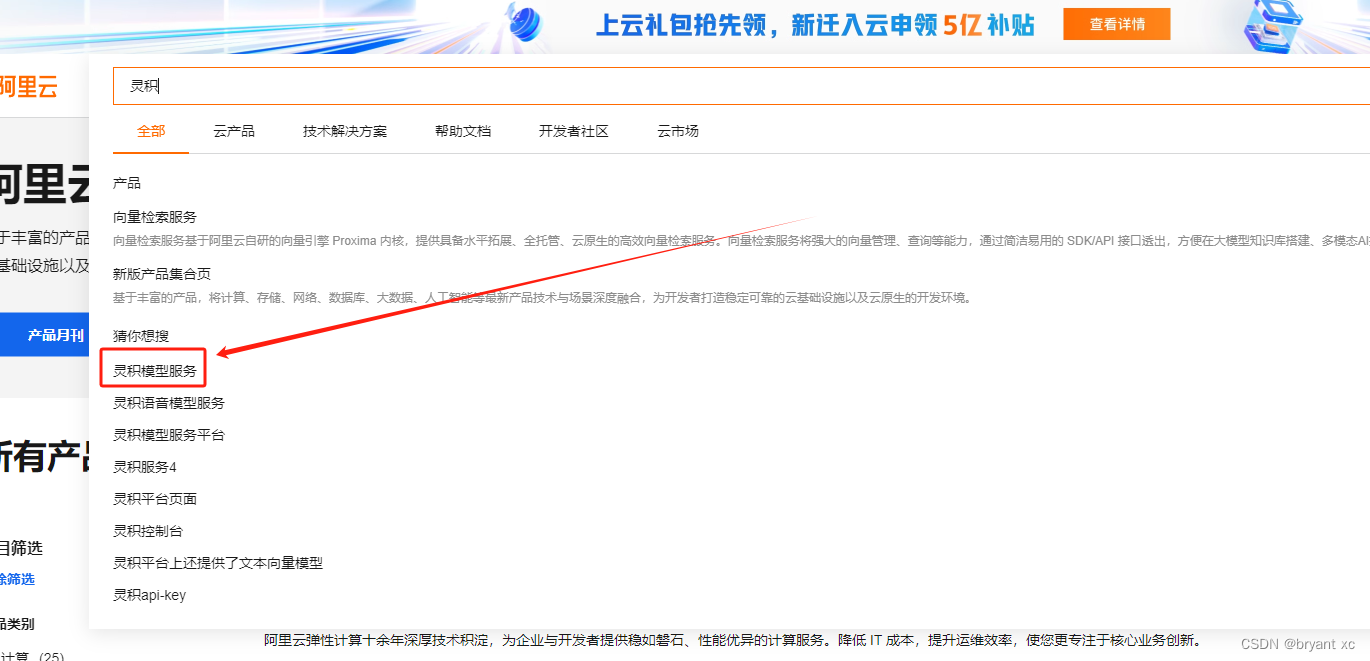
开通灵积模型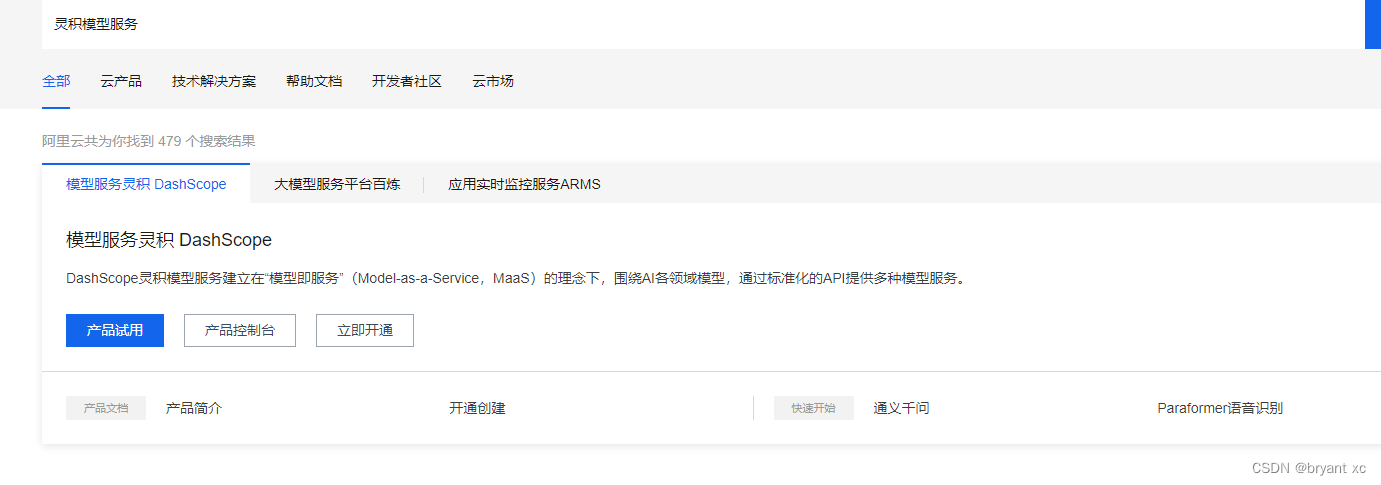
然后可以看到各种模型,这边使用的是免费的模型,如下
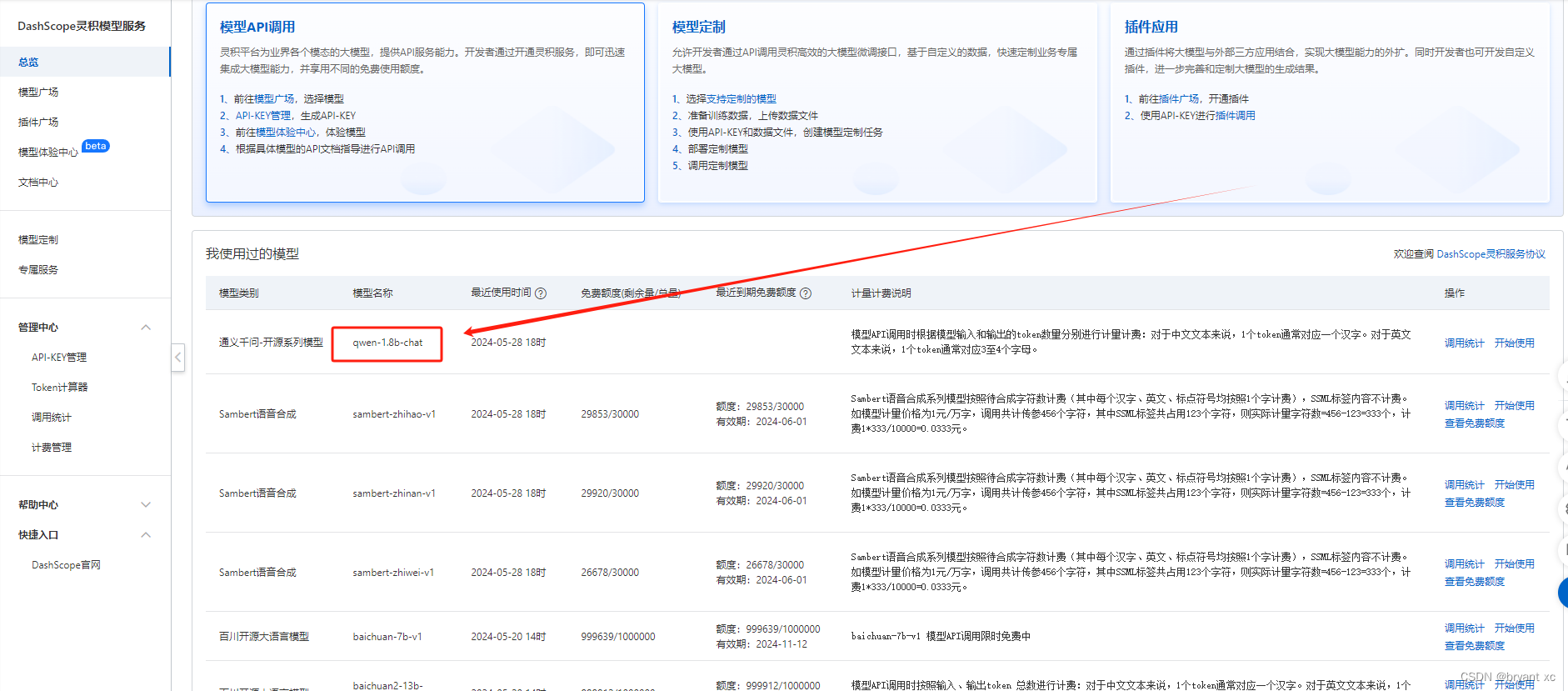
下面是生成语音的模型,有免费额度

查看api详情,对应如下: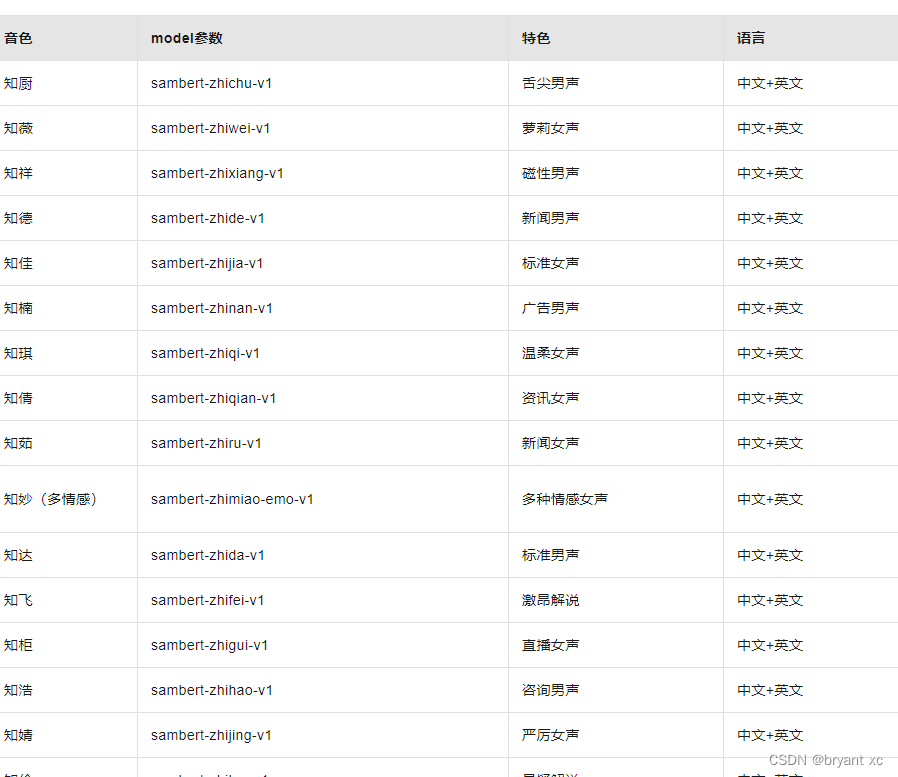
拿到api_key,项目使用:
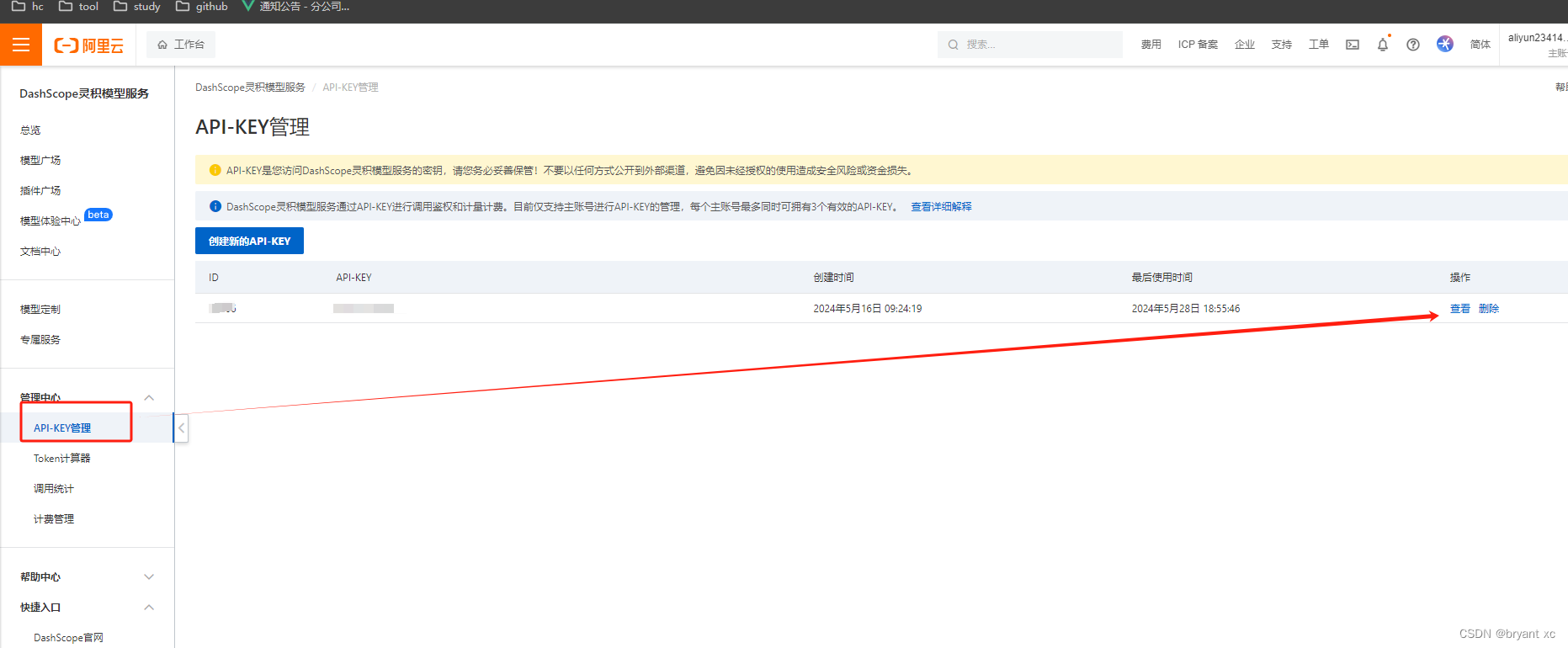
2.代码
生成语音:
import dashscope
import sys
import pyaudio
from dashscope.api_entities.dashscope_response import SpeechSynthesisResponse
from dashscope.audio.tts import ResultCallback, SpeechSynthesizer, SpeechSynthesisResult
dashscope.api_key = '' #阿里云模型服务灵积key
class Callback(ResultCallback):
_player = None
_stream = None
def on_open(self):
print('Speech synthesizer is opened.')
self._player = pyaudio.PyAudio()
self._stream = self._player.open(
format=pyaudio.paInt16,
channels=1,
rate=48000,
output=True)
def on_complete(self):
print('Speech synthesizer is completed.')
def on_error(self, response: SpeechSynthesisResponse):
print('Speech synthesizer failed, response is %s' % (str(response)))
def on_close(self):
print('Speech synthesizer is closed.')
self._stream.stop_stream()
self._stream.close()
self._player.terminate()
def on_event(self, result: SpeechSynthesisResult):
if result.get_audio_frame() is not None:
print('audio result length:', sys.getsizeof(result.get_audio_frame()))
self._stream.write(result.get_audio_frame())
if result.get_timestamp() is not None:
print('timestamp result:', str(result.get_timestamp()))
def create_voice(text):
callback = Callback()
SpeechSynthesizer.call(model='sambert-zhinan-v1', #语言调整模型,萝莉音等等
text=text,
sample_rate=48000,
format='pcm',
callback=callback)
语言模型对接,生成接口:
from http import HTTPStatus
from dashscope import Generation
import dashscope
from dashscope.api_entities.dashscope_response import Role, Message
import random
import create_voice_time
import queue
import threading
import re
from flask import Flask, request
app = Flask(__name__)
@app.route('/start', methods=['GET'])
def start():
# 提取query参数作为字符串
question = request.args.get('question', default='', type=str)
# 用 queue 创建两个队列
voice_queue = queue.Queue()
# # # 创建输入线程
input_thread = threading.Thread(target=call_with_messages, args=(voice_queue, question))
input_thread.start()
generate_voice(voice_queue)
def call_with_messages(voice_queue, question):
dashscope.api_key = '' #阿里云模型服务灵积key
messages = []
temp_str = ''
messages.append(Message(role=Role.USER, content=question))
responses = Generation.call(model="qwen-1.8b-chat", #这里可以选择语言模型
messages=messages,
# 设置随机数种子seed,如果没有设置,则随机数种子默认为1234
seed=random.randint(1, 10000),
# 将输出设置为"message"格式
result_format='message',
stream=True,
output_in_full=True
)
str = ""
role = ""
for response in responses:
if response.status_code == HTTPStatus.OK:
content = response.output.choices[0]['message']['content']
temp_str = str_to_queue(voice_queue, temp_str, content[len(str):])
str = content
role = response.output.choices[0]['message']['role']
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
messages.append(Message(role=role, content=str))
#根据符号拆分语句,生成语音流畅
def str_to_queue(voice_queue, temp_str, content):
# print(content)
# 用于匹配句子结束的标点符号,根据你的需要修改这个正则表达式
sentence_endings_regex = r'[,,。!?.!?]'
# 使用 re.split 使用正则表达式分割文本
sentences = re.split(sentence_endings_regex, content)
for index, sentence in enumerate(sentences, start=1):
if content != '' and re.search(sentence_endings_regex, content[0]):
voice_queue.put(temp_str)
temp_str = ''
if index == len(sentences):
temp_str = temp_str + sentence
continue
if index == 1:
voice_queue.put(temp_str + sentence)
temp_str = ''
continue
else:
voice_queue.put(sentence)
continue
return temp_str
# 声音处理线程函数
def generate_voice(voice_queue):
while True:
# 阻塞等待队列中的数据,如果队列为空,则等待固定时间,然后超时继续执行
try:
content = voice_queue.get() # 等待时间为 3 秒
if content is None: # 检查是否有内容,无内容则继续循环
continue
create_voice_time.create_voice(content) # 生成语音
except queue.Empty:
pass # 队列为空,则什么也不做
if __name__ == '__main__':
app.run(debug=True)
3.启动测试
启动上述接口py脚本,页面访问http://localhost:5000/start?question=输入自己的问题
随后可以听到大语言生成音频回答

















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









