






Python知识点记录
目录
2、十进制(int)、二进制(bin)、八进制(oct)、十六进制(hex)
5.2 元组tuple 中只有一个元素时,需要在元素后加上逗号;
5.4 dict.get(key, value) 返回指定键的值
5.7 字典的键要求可哈希(通过hash函数能产生唯一的value与key值对应)
7.2 抛出异常: raise Exception(“异常的描述”)
7.3 with ---上下文管理器,操作完成完成后自动关闭,类似 __enter__、 __exit__ 两个方法;
8.5.3 os.path.join() 函数,文件路径拼接
8.8 hasattr(object, name) 用于判断对象是否包含对应的属性;
8.8 setattr(object, name, value)创建一个新的对象属性;
8.9 divmod(a, b) 返回一个商和余数的元组(a//b, a%b)
8.10 string.center(width, fillchar)
8.11 filter(function, iterable) 过滤掉不符合条件的元素
8.12 math.sqrt(x) 返回x的平方根,x必须是数字,不小于0;
8.13 enumerate(sequence, startindex=0)
12.1 np.repeat(a, repeats, axis) 对数组元素进行连续重复复制
12.2 np.tile(a, reps) 对整个数组进行复制拼接
12.3 np.arange(x,y,z) 生成一个数列,x,y为始终点,z为步长(支持浮点数)
12.4 np.reshape(a,newshape,order="c") 将数组的数据重新划分新的矩阵,例如人员的站队场景;
12.5 np.argmin(a, axis=None) 求最小值对应的索引
-
1、类相关
- __init__(self, a, b): 类的初始化属性,获取属性值;通过super().__init__(...)调用父类的初始化属性,通过super().def() 调用父类的方法;
- Global 使一个局部变量为全局变量,函数内部可进行操作;
- 当脚本文件被别的文件调用时,其 __name__为自己的模块名称;自己运行自己的脚本时, __name__ 为 __main__;
class Name():
def __init__(self) -> None:
pass
def pri(self):
pass
if __name__ == "__main__":
pri()
2、十进制(int)、二进制(bin)、八进制(oct)、十六进制(hex)
| 十进制 | 二进制 | 八进制 | 十六进制 |
| 1 | 0b01 | 0o1 | 0x1 |
| 3 | 0b11 | 0o3 | 0x3 |
| 9 | 0b1001 | 0o11 | 0x9 |
| 15 | 0b1111 | 0o17 | 0xf |
2.1 转为十进制:
通过内置函数int(str, n), str表示需要转化的数,必须是字符串,n表示是几进制的数;
八进制转化为十进制:print(int('100', 8)) -----> 64
二进制转化为十进制:print(int('100', 2)) -----> 4
十六进制转化为十进制:print(int('100', 16)) -----> 256
print(int('100'))---------> 100
2.2 转为二、八、十六进制:
1)先将数转为十进制,在转为其他进制;
print(bin(int('100',8))) ---->0b1000000
print(oct(int('100',16))) ---->0o400
print(hex(100)) ---->0x64
- 给数添加进制前缀直接转换;
print(bin(0o100)) ------>0b1000000
print(oct(0xf))-------->0o17
print(hex(0b1111))----->0xf
3、字符串处理
name = “abbbabPythonbbbbb”
name.lower() 字符创全部小写
name.upper() 字符串全部大写
name.title() 单词的首字母大写(字符串中连续的字母被识别为一个单词)
Name.strip() 删除字符串首尾的空白
Name.strip(‘ab’) ----》‘Python’ 删除首尾包含‘a’、‘b’字符,循环进行删除
Name.rstrip() 删除右侧空白
Name.lstrip() 删除左侧空白
Name.replace(‘a’, ‘#’) 将字符串中‘a’全部替换为‘#’
Name.replace(‘a’, ‘#’, 2) 将字符串中前2个‘a’替换为‘#
# 判断字符串,返回bool值
name.isalpha() 字符串是否只包含字母
Name.isdigit() 字符串是否只包含整数
Name.isspace() 字符串是否只包含空格
Name.isupper() 是否都为大写
Name.islower() 是否都为小写
Name.isalnum() 字符串是否是字母或是数字
Name.startswith(str, beg=0, end= len(name)) 检查字符串是否以‘str’开头
Name.endswith(str, beg=0, end=len(name)) 检查字符串是否以‘str’结尾
4、逻辑运算,优先级 not > and > or
1)or : x or y x为 True(非0即为True),则返回x的值,否则返回y值
2)and:x and y x为 True(非0即为True),则返回y的值,否则返回x值
3)x/y 除法运算
4)x//y 除法运算后取整
5)x%y 除法运算后取余数
- 列表、元组、字典的操作
5.1 列表删除值
1)list.pop() 默认删除末尾的值,且删除的值还可以再被调用;添加index参数可以删除指定位置的值,例如: list.pop(2) 删除列表中下标为2的值;
2)list.remove(‘a’) 删除列表中‘a’元素,但只删除列表中的第一个,若需要全部删除可循环删除;
while 'a' in list:
list.remove('a')
3)del list[2] 删除列表中下标为2的元素
5.2 元组tuple 中只有一个元素时,需要在元素后加上逗号;
5.3 列表的切片list[起点:终点:步长]
lis = [1,2,3,4,5,6,7,8]
print(lis[::2]) # --->[1, 3, 5, 7]
# 步长为负数时,列表倒序
print(lis[::-1]) # --->[8, 7, 6, 5, 4, 3, 2, 1]
# 相当于取0-3】的值倒序
print(lis[3::-1]) # --> [4, 3, 2, 1]
5.4 dict.get(key, value) 返回指定键的值
Key:字典中要查找的键;
Value: 可选,如果键的值不存在时,返回None 或者设置的value值
dic = {'name':'python'}
print(dic.get('name', "Java")) # --->Python
print(dic.get('ID', 'Java')) # --->Java
print(dic.get('ID')) # --->None
5.5 extend 与 append 对比
Extend---接一个参数总是list,是将列表的元素加入到新列表中;
Append---参数可以是任何数据类型,简单的作为整体加入到列表末尾;
lis=[10, 1, 2]
num = [1,2,3,4]
num.append(lis)
print(num) # --->[1, 2, 3, 4, [10, 1, 2]]
nums = [1,2,3,4]
nums.extend(lis)
print(nums) # --->[1, 2, 3, 4, 10, 1, 2]
5.6 数据的复制
浅复制: 只会复制父对象,不会复制子对象(如list,其值会会跟随复制对象而变化)
深复制: 复制所有,单独存在
a = [1, 2, 3, 4, [‘a’, ‘b’]] , 在电脑中的存储情况入下:
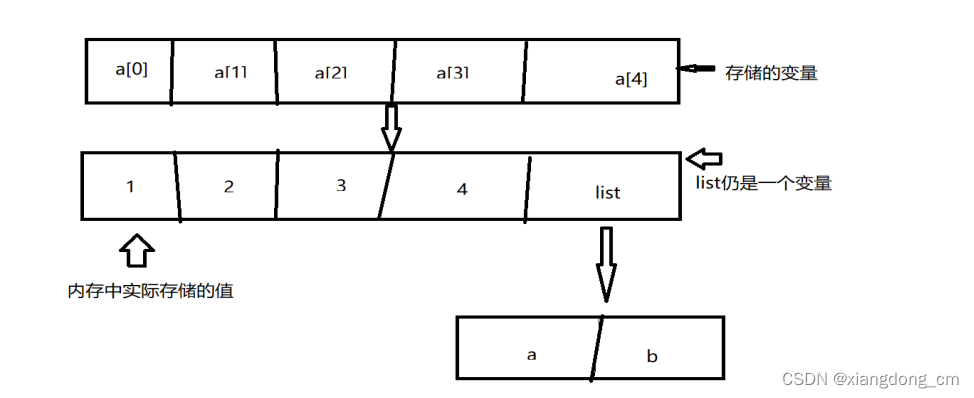
1) b=a 指向的是同一个值,只是变量不同
2)C= copy.copy(a) 浅复制,list的值在变量a、c中是一致的
- D= copy.deepcopy(a) 深复制,复制所有,单独存在
- D = a.copy() 深复制
- E= a[:] 浅复制
5.7 字典的键要求可哈希(通过hash函数能产生唯一的value与key值对应)
列表、集合、字典不可哈希,为可变得数据类型;
5.8 排序
1)sort(cmp=None, key=None, reverse=False) 是应用在list(也就是列表)上的方法,属于列表成员的方法--list.sort() ;对已存在的列表进行操作;
Cmp: 可选,指定了按该方法排序---Python3.x已取消
Key:主要用来进行比较的元素,可函数
Reverse:reverse=True 降序,reverse=False 升序(默认,可选)
- sorted(iterable,key=None,reverse=False) sorted是Python内置的全局方法,可以对所有的可迭代对象进行操作;结果返回一个新生成的列表,而不是在原有的基础上进行操作;
Iteralle: 可迭代的对象
key:主要用来进行比较的元素,可函数
Reverse:reverse=True 降序,reverse=False 升序(默认,可选)
# 排序,依次为大写、小写、奇数、偶数、其他
string = "abzdc292SDA354"
a = list(string)
a.sort(key=lambda x : (x.isdigit() and int(x)%2==0, x.isdigit(), x.islower(), x.isupper(),x))
b = sorted(string, key=lambda x : (x.isdigit() and int(x)%2==0, x.isdigit(), x.islower(), x.isupper(),x))
print(a) # -->['A', 'D', 'S', 'a', 'b', 'c', 'd', 'z', '3', '5', '9', '2', '2', '4']
print(b) # -->['A', 'D', 'S', 'a', 'b', 'c', 'd', 'z', '3', '5', '9', '2', '2', '4']
print(''.join(b)) # -->ADSabcdz359224
5.9 列表去重
Lis = []
- 字典去重 list(dict.fromkeys(lis))
- 集合去重 list(set(lis))
- for循环去重(新建列表,进行推导)
dict.fromkeys(lis, value(传入键的值)) ------可以生成字典
- 矩阵的操作
6.1 矩阵的行列值交换,将索引的值进行交换;
NUM = [[1,2,3],[4,5,6],[7,8,9]] ---> [[1,4,7],[2,5,8],[3,6,9]]
for i in range(3):
for j in range(3):
NUM[i][j],NUM[j][i] = NUM[j][i],NUM[i][j]
- 异常处理
7.1 try-except
try: # 需要执行的代码块,若try执行异常,则进入except部分;
n = int(input())
a = 55/n
except (ValueError, ArithmeticError): # 指定具体的报错类型
print('ERRor')
# except: # 其他的错误处理
# print('其他。。。')
except Exception as e: # 打印报错的详细信息
print(e.args, str(e), repr(e))
else: # try中代码执行正常,则执行else中的代码;else必须在except后面;
print(a)
finally: # 语句最后总是被执行
print("over!")
7.2 抛出异常: raise Exception(“异常的描述”)
例如:raise ZeroDivisionError('division by zero')
7.3 with ---上下文管理器,操作完成完成后自动关闭,类似 __enter__、 __exit__ 两个方法;
在一定条件下自动关闭打开的文件,例如:
with open('test.txt') as file:
file.read()
- 常用函数def
8.1 zip()函数
可接受多个迭代对象,把每个迭代对象的第i个元素组合在一起,形成一个迭代器,类型为元组;
a = [1,2,3]
b = [4,5,6]
c = zip(a,b)
print(next(c)) #---->(1, 4)
print(next(c)) #---->(2, 5)
a = [1,2,3]
b = [4,5,6]
c = zip(a,b)
print(list(c)) #---->[(1, 4), (2, 5), (3, 6)]
可通过循环、next()函数、list()函数提取迭代器的内容
8.2 abs()函数,求取值得绝对值
a = -2.345
print(abs(a))
其中a的值可以是int 、float;
8.3 字符 转化 ASCII码值
1)ord()函数,将字符转化为ASCII值(整数):print(ord('a')) -----》 97
2)chr()函数,将整数(ASCII值)转化为字符:print(chr(97)) ----> a
8.4 pow(x, y, z)函数,返回x的y次方
print(pow(3, 3)) ----> 27
print(pow(4, 0.5)) ---->2.0
print(pow(3,2,2)) ---> 1 # 返回3的2次方除以2后取余
当存在z参数时,x、y只能是整数且不等于0;当不存在z参数时,x、y的值可以是float类型;
8.5字符串的拆分、合并
8.5.1 split()函数,拆分字符串
1) <string>.split(sep,maxsplit) sep:拆分的标记符,默认为空格;maxsplit:拆分的次数;
my_string = "I code for 2 hours everyday"
print(my_string.split()) # -->['I', 'code', 'for', '2', 'hours', 'everyday']
my_string = "Apples,Oranges,Pears,Bananas,Berries"
print(my_string.split(',')) # --->['Apples', 'Oranges', 'Pears', 'Bananas', 'Berries']
print(my_string.split(',',1)) # -->['Apples', 'Oranges,Pears,Bananas,Berries']
8.5.2 join()函数,合并字符串
1) <sep>.join(<iterable>) <iterable> 是任何包含子字符串的 Python 可迭代对象,例如列表、元组; <sep> 是你想要加入子字符串的分隔符。
my_string = ['Apples', 'Oranges', 'Pears', 'Bananas', 'Berries']
print(',,'.join(my_string)) # --> Apples,,Oranges,,Pears,,Bananas,,Berries
8.5.3 os.path.join() 函数,文件路径拼接
import os
Path1 = r'C:\Users\admin-xd'
Path2 = r'Desktop\日常文件'
Path3 = ''
Path10 = Path1 + Path2 + Path3
Path20 = os.path.join(Path1, Path2)
print('Path10 = ',Path10) --->Path10 = C:\Users\admin-xdDesktop\日常文件
print('Path20 = ',Path20) --->Path20 = C:\Users\admin-xd\Desktop\日常文件
- Linux用的是/分隔符,而Windows才用的是\
- 假如有多个盘符 或者 “\”,均从最后一个开始保留
import os
Path1 = r'C:\Users\admin-xd'
Path2 = r'D:\Desktop\日常文件'
Path3 = ''
Path10 = Path1 + Path2 + Path3
Path20 = os.path.join(Path1, Path2)
print('Path10 = ',Path10) --->Path10 = C:\Users\admin-xdD:\Desktop\日常文件
print('Path20 = ',Path20) -->Path20 = D:\Desktop\日常文件
8.6 字符串的查找
8.6.1 find() 函数
方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
- string.find(str, beg=0, end=len(string)) str -- 指定检索的字符串; beg -- 开始索引(可选参数),默认为0; end -- 结束索引,默认为字符串的长度(可选参数)。
string = '3.141592653589793'
print(string.find('159', 0 ,len(string))) # --> 4
print(string.find('159')) # --> 4
8.6.2 rfind() 函数
1) string.rfind(str, beg=0, end=len(string)) 返回字符串最后一次出现的位置;
string = '3.141592653589793'
print(string.rfind('5', 0 ,len(string))) # --> 11
8.7 eval() 函数
计算过程中具有int、float函数的功能,必须接受字符串表达式,可直接运行;
num = eval('2*3')
print(num) # --> 6
8.8 hasattr(object, name) 用于判断对象是否包含对应的属性;
Object:对象; name: 字符串,属性名,返回True 或 False
class sss():
def __init__(self) -> None:
self.namee = 'aa'
self.name = 0
def pri(self):
print(self.name)
print(hasattr(sss(),'name')) ---》True
8.8 setattr(object, name, value)创建一个新的对象属性;
Object:对象; name: 字符串,属性名; value: 属性值
class sss():
def __init__(self) -> None:
self.namee = 'aa'
self.name = 0
def pri(self):
print(self.name)
s = sss()
setattr(s,'age', 18)
print(s.age)
8.9 divmod(a, b) 返回一个商和余数的元组(a//b, a%b)
print(divmod(9, 2)) # -->(4, 1)
8.10 string.center(width, fillchar)
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
width -- 字符串的总宽度。fillchar -- 填充字符。
print('Python'.center(15, '$')) # -->$$$$$Python$$$$
8.11 filter(function, iterable) 过滤掉不符合条件的元素
Function:判断条件
Iterable:可迭代对象
a = [1,2,3,4,5,6,7,8,9,11]
f = list(filter(lambda x: x%2==1, a))
print(f) # --->[1, 3, 5, 7, 9, 11]
8.12 math.sqrt(x) 返回x的平方根,x必须是数字,不小于0;
import math
print(math.sqrt(25)) # ---> 5
8.13 enumerate(sequence, startindex=0)
将一个可遍历的数据对象(列表、元组、字符串)组合为一个索引序列,同事列出数据和索引,一般用在for循环中;
Sequence:一个序列、迭代器或者支持迭代的对象
Startindex:下标的起始位置(可选,默认为0)
string = ['Apples', 'Oranges', 'Pears', 'Bananas', 'Berries']
my_str = enumerate(string,start=10)
for index,value in my_str:
print(index,value)
"""
10 Apples
11 Oranges
12 Pears
13 Bananas
14 Berries
"""
-
9、正则、re模块
9.1 表达式
r : 表示后面的字符串是一个普通的字符串(比如 “\n”是字符而非换行符)
r'C:\Users\admin-xd'
(): 括号包住的数据为要提取的数据,通常与.group()函数连用
. : 表示单个字符
* :匹配前一个字符出现0次或者无限次
?:匹配前一个字符出现0次或者1次
^ :匹配输入字符串开始的位置
$ :匹配输入字符串结束的位置
import re
string = '456abc123'
strings = re.search("([0-9]*)([a-z]*)(.*)",string)
print(strings.group()) # 整个字符串
print(strings.group(0)) # 整个字符串
print(strings.group(3)) # 第三个括号的内容
-
10、集合
- 集合通过{}直接创建,或者set()函数创建(无序、不重复的元素集);{1, 2, 3}
- 集合的交集(求两个集合共同的元素:s1 & s2)、并集(合并两个集合的元素:s1 | s2)、差集(s1-s2 去除共同的元素)
s1 = {1,2,4,3}
s2 = {2,3,5,6}
print(s1&s2) #-->{2, 3}
print(s1|s2) #-->{1, 2, 3, 4, 5, 6}
print(s2-s1) #-->{5, 6}
- 通过 s1.update(values) 更新整合两个集合,或者添加元素(可接受集合、列表、字符等)
- 通过 s1.add(value) 向集合末尾增加元素
- Del s1 删除集合s1
- S1.clear() 清空集合元素
- S1.discard(value) 丢弃指定的元素
- S1.remove(value) 丢弃指定的元素
- S1.pop() 弹出最上面的元素
- 集合是无序的、唯一的,不能通过索引访问;若需要,可转列表
-
11、匿名函数-lambda
不使用def这种标准语句定义一个函数
r = 10
q = 4
e =5
n = lambda *r: sum(r)
print(n(r,q,e))
- 屏蔽time库中的sleep功能(将lambda赋值给其他函数)
time.sleep = lambda x: None
time.sleep(3) 程序将不会休眠3秒
-
12、Numpy 数值计算扩展
12.1 np.repeat(a, repeats, axis) 对数组元素进行连续重复复制
a:输入的数据
Repeats: 需要复制的次数
Axis:int类型,axis=0,沿y轴复制,增加行数;axis=1,沿x轴复制,增加列数;axis=None(可不写,默认为None),就回flatten(弄平)当前矩阵,实际上就是变成一个行变量
import numpy as np
x = [[1,2],['a','b']]
print(np.repeat(x,2)) # --->['1' '1' '2' '2' 'a' 'a' 'b' 'b']
print(np.repeat(x, 3, axis=0)) # --->
"""
[['1' '2']
['1' '2']
['1' '2']
['a' 'b']
['a' 'b']
['a' 'b']]"""
print(np.repeat(x, (2,3), axis=1)) # --->
"""
[['1' '1' '2' '2' '2']
['a' 'a' 'b' 'b' 'b']]
"""
12.2 np.tile(a, reps) 对整个数组进行复制拼接
a:array、list、tuple、dict、matrix以及基本的数据类型;
Reps:重复的次数,int、tuple、list、dict、bool;
Reps=2 将a复制两列
Reps=(2, 3)将a复制2行3列,即x轴、y轴
import numpy as np
x = [[1,2],['a','b']]
print(np.tile(x, 2)) # --->
"""
[['1' '2' '1' '2']
['a' 'b' 'a' 'b']]
"""
print(np.tile(x, (2,3)))
"""
[['1' '2' '1' '2' '1' '2']
['a' 'b' 'a' 'b' 'a' 'b']
['1' '2' '1' '2' '1' '2']
['a' 'b' 'a' 'b' 'a' 'b']]
"""
12.3 np.arange(x,y,z) 生成一个数列,x,y为始终点,z为步长(支持浮点数)
print(np.arange(1,6,2)) # --->[1 3 5]
12.4 np.reshape(a,newshape,order="c") 将数组的数据重新划分新的矩阵,例如人员的站队场景;
a:为数组
Newshape:新的形状,整数或者整数数组;例如:(2,3)表示2行3列的二维数组;(2,3,4)表示三维数组,值的大小相当于各维度的长度(从外层到里层);
Order:范围{‘c’,‘F’,‘A’},索引顺序读取,默认为“C”
num = [i for i in range(1,13)]
print(np.reshape(num,[2,2,3])) # --->
"""
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
"""
或者 num.reshape([2,2,3]) 划分
- nums.reshape(-1) 将多维数组(矩阵)拉平;
- Num.reshape(2,2,-1) -1表示numpy会根据余下的维度值进行自动计算;
- Nums.shape() 返回多维数组(矩阵)的维度值
12.5 np.argmin(a, axis=None) 求最小值对应的索引
1)a若为list,所有元素按原有顺序摊平拉直后,获取第一个最小值的位置;
2) a若为array类型,不设置axis的值,则摊平拉直后获取第一个最小值位置;
3)a若为array类型且为多维数组,axis=0 表示对第0维进行比较,其他维度去相同的值(同一个坐标值,不是相等的值),不同的0维上的值()进行比较,返回最小值在第0维上的索引;axis=1、 2、 3....同理推测;

注释: np.argmax() 求最大值得索引位置,用法同上、、、
a = np.array([
[[1, 5, 5, 2],[9, -6, 2, 8],[-3, 7, -9, 1]],
[[-1, 5, -5, 2],[9, 6, 2, 8],[3, 7, 9, 1]]
])
print(np.argmin(a,axis=0))
"""
[[1 0 1 0]
[0 0 0 0]
[0 0 0 0]]
"""
-
13、Random 随机函数
- random.random() 随机生成(0,1)之间的浮点数;
- random.randint(start,stop)随机生成范围内的整数;
- Random.randrange(start, stop, step) 按步长step的范围内的随机数;
- Random.uniform(a,b) 生成范围内的浮点数
- Random.seed(x) 通过x参数改变随机数生成器种子;
-
14、装饰器
装饰器就是代码运行期间动态的给函数增加某项功能;
1)闭包:某函数被当成对象返回时不夹带外部变量,就形成了闭包;
class Py():
def __init__(self) -> None:
pass
# 封装代码运行时长的函数
def timer(func):
def sumr(self,*args, **kwargs):
start = time.time()
time.sleep(2)
res = func(self, *args, **kwargs)
end = time.time()
print(end-start)
return res
return sumr
# 相当于将fen(x,y)作为参数传入timer(func)中运行,直接返回结果
@timer
def fens(self,x,y):
return x+y
print(Py().fens(3,6))
"""
2.0121266841888428
9
"""
- 常用的装饰器
- @Staticmethod 修饰类中的方法,可以在不创建类实例的情况下调用方法----静态方法
- @classmethod 指定一个类的方法为类方法
- @propety 访问对象的属性:实例名。变量名,可以使用@propety装饰器奖方法伪装成 属性 的样式使用;
-
15、open(file,mode,encoding.........)
Fire: 文件的路径
Mode: 文件的操作模式,r、w、a、x 分别为读、写、追加、创建新文件,b为二进制模式,r+为读写模式;
Encoding:指定编码格式 encoding=”utf-8”
注意: 以W模式打开文件时,会清空原有文件的内容;
16、os.walk() 遍历文件夹中的所有文件和文件夹
For root, dirs,files in os.walk(dir_path):
.......
Root:当前目录的绝对路径
Dirs: 当前目录下的子目录---list
Files:当前目录下所有文件----list















 3270
3270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









