






大家好,我是独孤风。在当今数据驱动的商业环境中,数据治理成为企业成功的关键因素之一,而数据血缘正是数据治理成功的一个关键。
本文我们详细探讨下数据血缘的特点都有什么?对比一下数据血缘、数据关系、数据分类、数据出处、知识图谱相关概念的关系。
本文为《数据血缘分析原理与实践 》一书读书笔记,部分观点参考自书中原文,如需更详细的了解学习,请大家支持原作者的辛苦付出。
本文思维导图如下所示:
在数据治理领域,数据血缘(Data Lineage)是一个核心概念,描述了数据从源头到最终用途的整个生命周期,包括数据的来源、变化和去向。理解数据血缘的特征及其与其他相关概念的关系,对于数据管理和数据治理至关重要。本文将详细介绍数据血缘的五个主要特征:稳定性、归属性、多源性、可追溯性和层次性,并探讨它与数据关系、数据分类、数据出处及知识图谱之间的联系和区别。
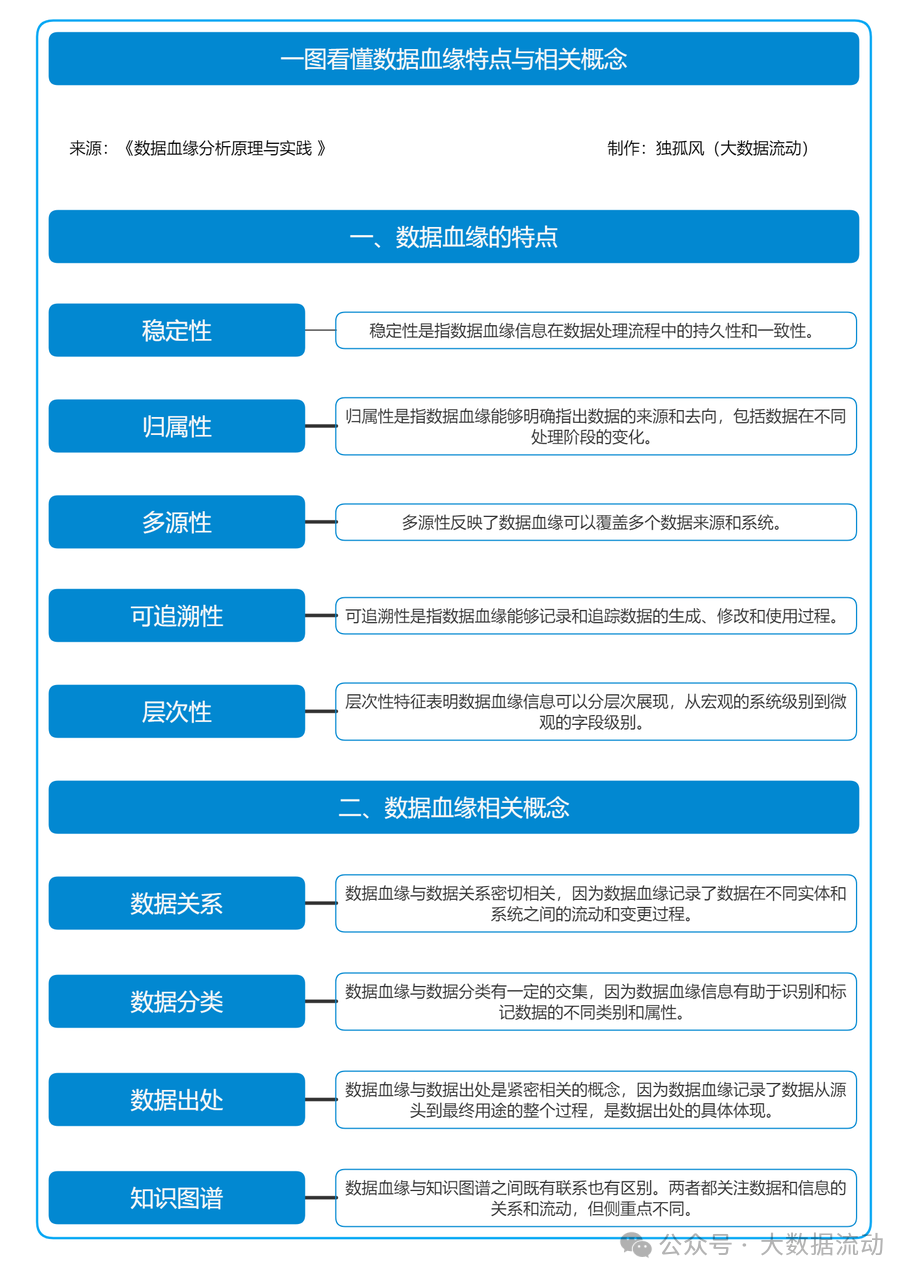
一、数据血缘的特征
稳定性
稳定性是指数据血缘信息在数据处理流程中的持久性和一致性。在数据治理中,稳定的数据血缘信息可以帮助企业追踪数据变化路径,确保数据处理过程透明可见,防止数据丢失和错误传递。这一特征使得数据血缘成为数据合规和审计的重要工具。稳定性保证了数据血缘信息在长时间内不受频繁的系统变更或数据更新影响,始终能够提供一致可靠的数据流动记录。
归属性
归属性是指数据血缘能够明确指出数据的来源和去向,包括数据在不同处理阶段的变化。归属性特征有助于数据管理者理解数据在整个生命周期中的流动和转变,确保数据的准确性和完整性,进而提高数据决策的可靠性。归属性使得每个数据点都可以被追溯到其源头,知道数据是如何生成的,经过哪些处理,最终到达何处。这种透明性对于数据治理和数据分析至关重要。
多源性
多源性反映了数据血缘可以覆盖多个数据来源和系统。在现代企业中,数据通常来自多个异构系统和数据源,通过整合和分析这些多源数据,数据血缘可以提供全面的视图,帮助企业更好地理解和利用数据资源。多源性不仅指数据来源的多样性,还包括数据在不同系统之间的流动和交互,这对于构建全局的数据视图和进行跨系统的数据分析非常重要。
可追溯性
可追溯性是指数据血缘能够记录和追踪数据的生成、修改和使用过程。这一特征对于数据质量管理、数据安全和数据合规至关重要。通过可追溯性,企业可以识别和解决数据问题,防止数据篡改和不当使用。可追溯性使得每个数据操作都可以被记录和查询,确保在需要时能够回溯数据处理的每一步,了解数据如何从源头到达当前状态。
层次性
层次性特征表明数据血缘信息可以分层次展现,从宏观的系统级别到微观的字段级别。这种层次化的视图帮助数据管理者在不同层面上分析和理解数据流动,提供灵活的查询和分析能力。层次性允许数据治理工作从全局视角逐步深入到具体细节,使得数据血缘信息可以满足不同层次的需求,从而提供更加精准和全面的数据治理支持。

二、数据血缘相关概念
数据血缘与数据关系
数据关系(Data Relationships)描述了数据实体之间的关联和相互作用。数据血缘与数据关系密切相关,因为数据血缘记录了数据在不同实体和系统之间的流动和变更过程。例如,在一个数据处理链中,数据血缘可以显示从一个数据库表到另一个表的转换关系,而数据关系则描述这些表之间的关联性。数据血缘为理解和分析数据关系提供了基础和支持。
数据关系通常包括实体间的层级关系、引用关系、依赖关系等,这些关系构成了数据在系统中流动和交互的基础。数据血缘则进一步细化这些关系,描述了数据在这些关系中的具体流动路径。例如,数据血缘可以显示某个数据字段是如何从一个表中派生出来并最终存储到另一个表中的,这种细致的记录帮助企业更好地理解数据关系的具体实现方式。
数据血缘与数据分类
数据分类(Data Classification)是对数据进行组织和分组,以便于管理和使用的过程。数据血缘与数据分类有一定的交集,因为数据血缘信息有助于识别和标记数据的不同类别和属性。通过数据血缘,企业可以追踪特定类别数据的来源和变化路径,确保数据分类的准确性和一致性。此外,数据分类结果可以为数据血缘提供背景信息,帮助更好地理解数据流动和转变。
数据分类通常依据数据的敏感性、使用目的、来源等进行分组,这些分类信息可以在数据血缘记录中反映出来。例如,敏感数据的处理路径可以被特别标记和追踪,确保在数据处理过程中严格遵循隐私和安全规定。数据血缘记录中的分类信息还可以帮助企业在数据治理过程中更有针对性地管理和控制不同类别的数据。
数据血缘与数据出处
数据出处(Data Provenance)是指数据的起源和历史,包括数据的生成、收集、处理和存储过程。数据血缘与数据出处是紧密相关的概念,因为数据血缘记录了数据从源头到最终用途的整个过程,是数据出处的具体体现。通过数据血缘,企业可以详细了解数据的生成和变更历史,确保数据的可靠性和可信性。
数据出处关注的是数据的“过去”,即数据从何而来、经历了哪些处理步骤等。数据血缘则既关注数据的“过去”,也关注数据的“现在”和“未来”,即数据当前的状态和未来的去向。两者结合,提供了完整的数据生命周期视图,帮助企业全面了解数据的历史、现状和预期流向,为数据治理和决策提供坚实基础。
数据血缘与知识图谱
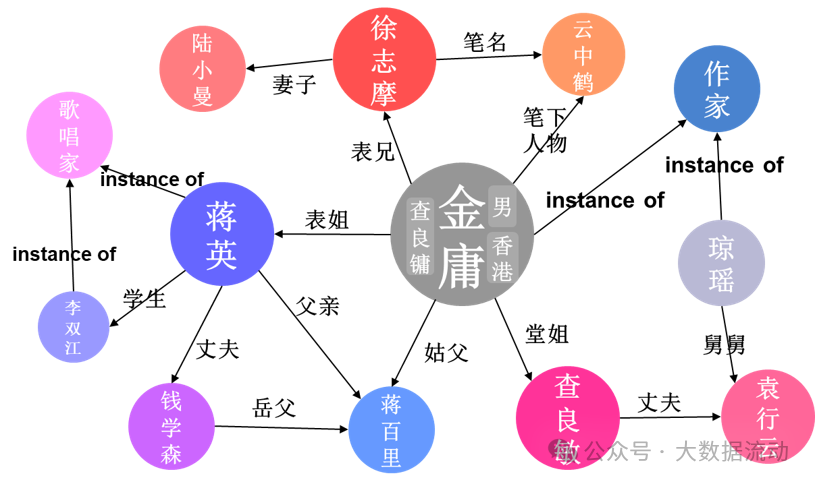
知识图谱(Knowledge Graph)是表示实体及其相互关系的图结构,用于组织和查询知识。数据血缘与知识图谱之间既有联系也有区别。两者都关注数据和信息的关系和流动,但侧重点不同。数据血缘侧重于数据的处理和流转过程,而知识图谱侧重于实体及其关系的组织和表示。然而,数据血缘信息可以作为构建知识图谱的重要数据来源,帮助描述数据实体之间的关联和流动,从而丰富知识图谱的内容和应用场景。
知识图谱通常包含丰富的语义信息,表示实体之间的各种复杂关系。这些关系可以包括上下位关系、关联关系、因果关系等。数据血缘信息为知识图谱提供了关于数据流动和变更的具体记录,使得知识图谱不仅能够表示实体之间的静态关系,还能够反映数据在这些关系中的动态流动过程。例如,通过整合数据血缘信息,知识图谱可以展示某个数据实体在不同处理阶段的变化路径及其与其他实体的交互方式,提供更加全面和动态的知识表示。
数据血缘自身的概念我们了解的差不多,数据血缘与数据治理中的内容又有怎么样的关系呢?
下一章开始,我们来了解数据血缘与元数据、主数据、业务数据、指标数据之间的联系。
我们下一章再见!
















 3018
3018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











