







2024.11.15
当我们谈神经网络的激活函数的时候,通常是指非线性激活函数,因为谈线性的没有什么意义。
1.什么是函数非线性?
非线性是指函数不能表示为输入变量的简单线性组合(即多个变量通过加权求和的方式得到一个新变量)。
换一个角度解释:非线性表示曲线的导数不是常数,即不是一条直线。
eg:矩阵乘法,加权求和、多项式组合都是属于线性组合。
2. 为什么要用非线性激活函数?
故事要从AI的第一次寒冬谈起,1973年,那个时候的神经网络还是幼儿状态的感知机。
其计算公式为:Z = WX+b, Y= sign(Z),sign是一个符号函数,输出0(或-1)或1.
一篇报告指出感知机本质是一个线性模型,只能处理线性问题,连最简单的异或问题也不能解决。这直接导致了接下来10年AI进行低谷期。
局面的改变要归功于Sigmoid函数,1986年,Hinton提出多层感知机(MLP),在层间使用Sigmoid函数来引入非线性,此时的计算公式为:
Z=WX+b,Y=sigmoid(Z), sigmoid就是一个非线性函数。
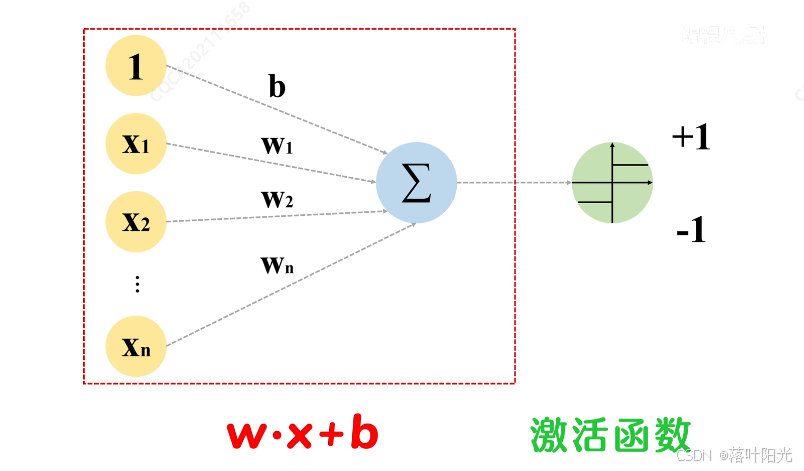
在现在的多层神经网络中,当用于回归任务时,只在隐藏层添加激活函数,输出层不添加;用于分类任务时,隐藏层和输出层都会添加激活函数,但作用是不同的,比如在隐藏层使用ReLU是为了引入非线性,在输出层使用sigmoid(二分类)或者softmax(多分类)这个是为了将输出值转换为类别概率。
为什么非线性激活函数可以解决异或问题?或者说为什么要引入非线性激活函数?
不管是DNN、CNN还是RNN,其本质都是从输入到输出的一系列的向量和矩阵运算(属于线性组合)。
如果没有非线性激活函数,多层神经网络将退化为一个简单的线性模型(每一层输入都是上一层输出的线性函数,z=Wx+b),无论有多少层,其表达能力都会受到极大的限制(相当于单层)。
而在层间引入非线性激活函数,相当于对数据空间进行变换,原本线性不可解的问题变得可解,理论上,深层神经网络可以逼近任意函数。
3.非线性激活函数常用有哪些?
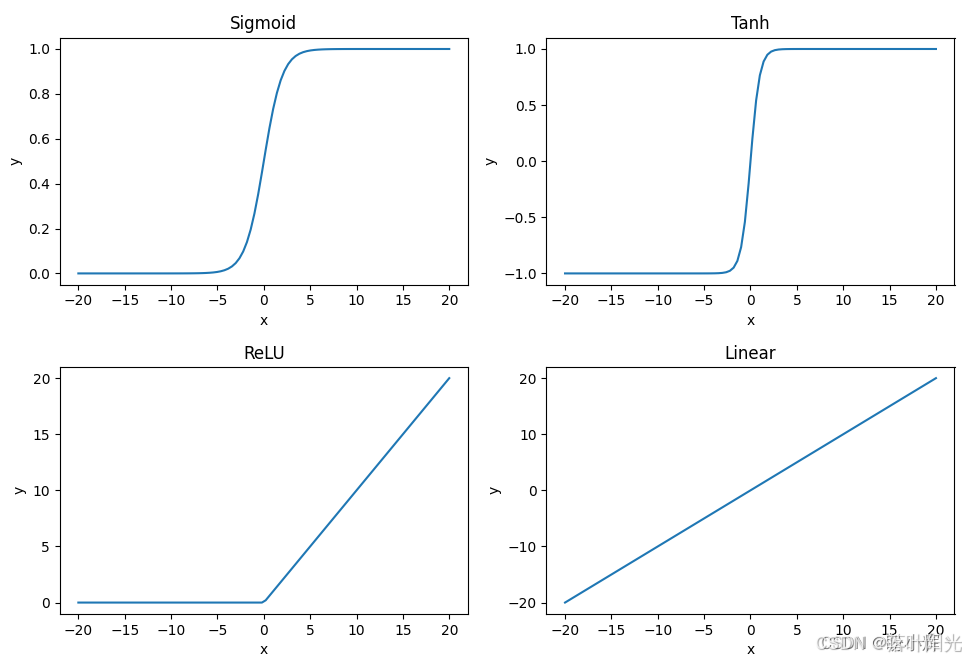
以下是一些常用的非线性激活函数及其作用:
-
Sigmoid:
- 公式: f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
- 特点: Sigmoid 函数将输入映射到 (0, 1) 之间,具有平滑的梯度,但容易导致梯度消失问题,特别是在输入远离原点时。
- 应用: 传统上用于二分类问题的输出层,但现在较少使用于隐藏层,因为它的梯度消失问题。 -
Tanh (Hyperbolic Tangent):
- 公式: f ( x ) = tanh ( x ) = e x − e − x e x + e − x f(x) = \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=tanh(x)=ex+e−xex−e−x
- 特点: Tanh 函数将输入映射到 (-1, 1) 之间,相比于 Sigmoid,它的输出中心位于0,这有助于训练过程中的数据居中。
- 应用: 曾经广泛用于隐藏层,但现在也被 ReLU 等函数取代。 -
ReLU (Rectified Linear Unit):
- 公式: f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- 特点: ReLU 在正区间是线性的,在负区间输出为0。它在实践中非常流行,因为它计算简单,能够缓解梯度消失问题,并且能够产生稀疏激活(即只有部分神经元被激活)。
- 应用: 广泛应用于各种类型的神经网络,尤其是卷积神经网络(CNNs)和深度前馈网络。 -
Leaky ReLU:
- 公式: f ( x ) = { x if x > 0 α x if x ≤ 0 f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \leq 0 \end{cases} f(x)={xαxif x>0if x≤0,其中 α \alpha α 是一个小的正数(例如 0.01)。
- 特点: Leaky ReLU 解决了 ReLU 在负区间梯度为0的问题,允许小的负梯度传递,有助于缓解“死亡神经元”问题。
- 应用: 用于需要缓解 ReLU 梯度消失问题的情况。 -
PReLU (Parametric ReLU):
- 公式: f ( x ) = { x if x > 0 α x if x ≤ 0 f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \leq 0 \end{cases} f(x)={xαxif x>0if x≤0,其中 α \alpha α 是一个可学习的参数。
- 特点: PReLU 类似于 Leaky ReLU,但 α \alpha α 是一个可以学习的参数,而不是固定的值。这使得网络可以根据数据自适应地调整 α \alpha α。
- 应用: 用于需要自适应调整负梯度的情况。 -
Softmax:
- 公式: f ( x i ) = e x i ∑ j e x j f(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} f(xi)=∑jexjexi
- 特点: Softmax 将一组数值转换为概率分布,使得所有输出的和为1。它常用于多分类问题的输出层。
- 应用: 主要用于多分类问题的输出层,将输出转换为各类别的概率。 -
Swish:
- 公式: f ( x ) = x ⋅ σ ( x ) f(x) = x \cdot \sigma(x) f(x)=x⋅σ(x),其中 σ ( x ) \sigma(x) σ(x) 是 Sigmoid 函数。
- 特点: Swish 是一个自门控激活函数,它在某些情况下比 ReLU 表现更好。它在正区间是线性的,在负区间是平滑的。
- 应用: 用于需要更平滑激活函数的情况。
通过这些非线性激活函数,神经网络能够学习复杂的特征表示,从而能够处理非线性问题,如图像识别、自然语言处理等。每种激活函数都有其优缺点,选择合适的激活函数取决于具体的应用场景和数据特性。
4.大模型中的非线性激活函数
待补充


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









