







Xinference 是一个新兴的强大平台,它旨在简化本地和云端模型的部署与管理,支持多样化的模型类型和硬件加速。

本文将详细介绍如何在 macOS 上安装和使用 Xinference,并对比它与 Ollama 的区别,最后演示如何将 Xinference 集成到 Chatbox、Dify等流行的本地化知识库应用中。
一、Xinference 简介
Xinference (Xorbits Inference) 是一个通用的推理平台,旨在为各种模型(可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理)提供统一的接口和服务。
它的主要特点包括:
-
模型多样性: 支持多种模型类型,包括语言模型 (LLMs)、 embedding 模型、图像模型、音频模型等。
-
硬件加速: 支持 CPU、GPU (NVIDIA, AMD, Intel) 和 Apple Silicon 等多种硬件加速。
-
易于部署: 提供简单的命令行界面和 Python API,方便本地和云端部署。
-
可扩展性: 支持分布式部署,可以轻松扩展以处理更大规模的推理任务。
-
统一 API: 提供与 OpenAI API 兼容的接口,方便现有应用快速集成。
-
模型管理: 内置模型库,方便模型发现、下载和管理。
二、Xinference vs. Ollama
Ollama 和 Xinference 都是流行的本地 LLM 部署工具,但它们在设计理念、功能和适用场景上存在一些差异:
| 特性 | Ollama | Xinference |
|---|---|---|
| 模型类型 | 主要专注于 LLMs,embedding | 支持多种模型类型 (LLMs, embedding, reranker,图像, 音频等) |
| 硬件支持 | CPU, GPU (NVIDIA, AMD, Apple Silicon) | CPU, GPU (NVIDIA, AMD, Intel, Apple Silicon) |
| 易用性 | 非常简单易用,一键安装,模型库丰富 | 相对复杂一些,但功能更强大,可定制性更高 |
| 扩展性 | 相对较弱,主要面向单机使用 | 更强,支持分布式部署,可扩展性更好 |
| API 兼容性 | 部分兼容 OpenAI API | 完全兼容 OpenAI API |
| 适用场景 | 快速体验本地 LLMs,轻量级应用 | 多样化模型需求,企业级应用,需要更高可定制性 |
总结:
-
Ollama: 更注重 简单易用,适合快速上手本地 LLM 体验,模型库丰富,但模型类型和扩展性相对有限。
-
Xinference: 更注重 强大和灵活,支持更多模型类型,更强的扩展性和可定制性,API 兼容性更好,适合更复杂的应用场景和企业级部署,但上手门槛稍高。
大家可以根据自身需求和技术水平选择合适的工具。如果只是想快速体验本地 LLM,Ollama 可能更简单;
如果需要更强大的功能和更灵活的配置,或者需要部署多种类型的模型,Xinference 则更适合。
三、macOS 安装 Xinference
在 macOS 上安装 Xinference 非常简单,只需几个步骤:
3.1 安装Python环境
Xinference 基于 Python 构建,你需要确保你的 macOS 系统已经安装了 Python (推荐 Python 3.8 及以上版本) 和 pip 包管理器。
brew install python
安装完成后,验证 Python 和 pip 版本:
python --version
pip --version
3.2 安装Xinference
使用 pip 命令安装 Xinference:
pip install xinference
等待安装完成。
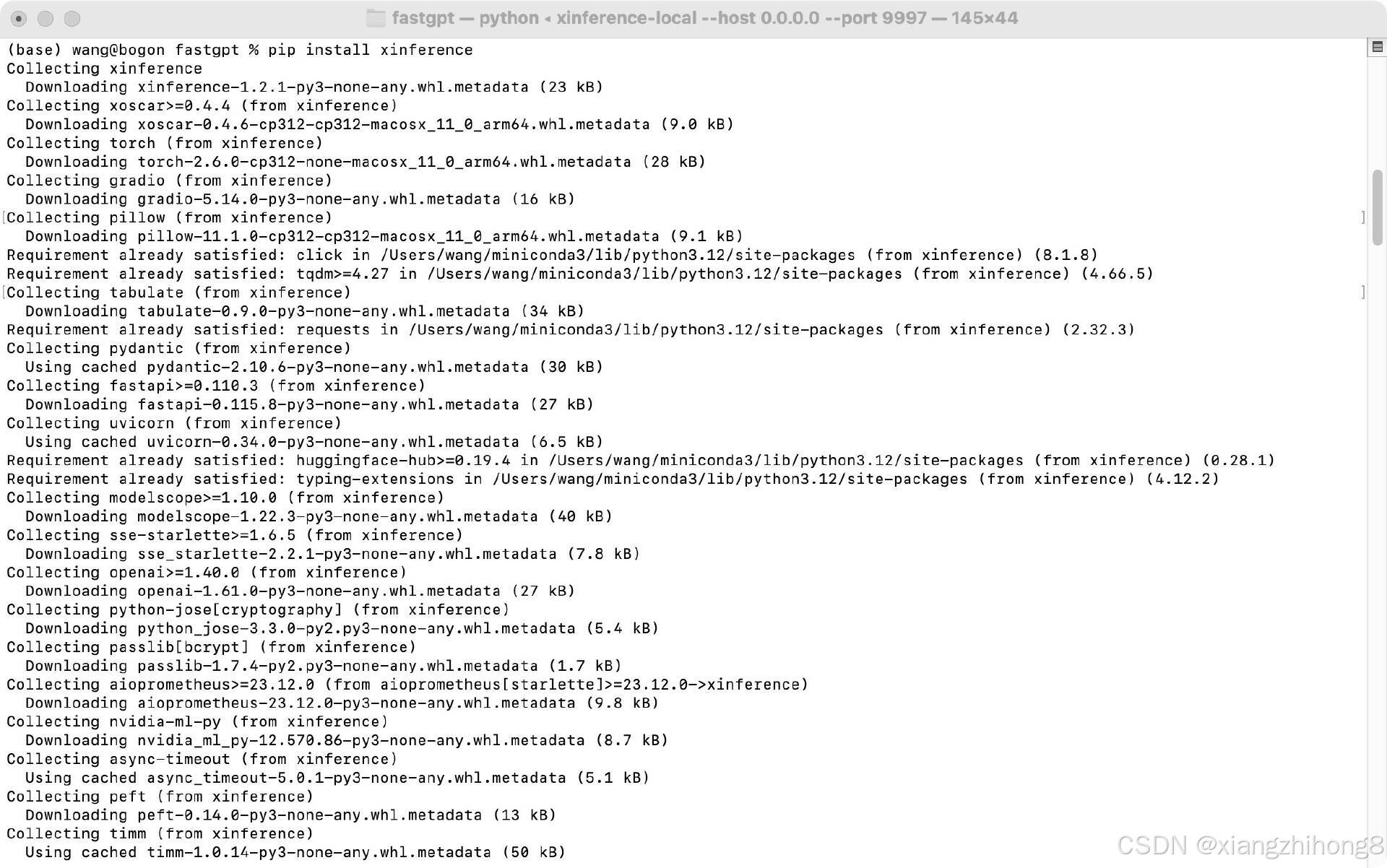
3.3 安装硬件加速
Mac OS系统使用Metal的优化,也就是类似cuda的mps功能。
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
3.4 启动 Xinference 服务
安装完成后,使用以下命令启动 Xinference 服务:
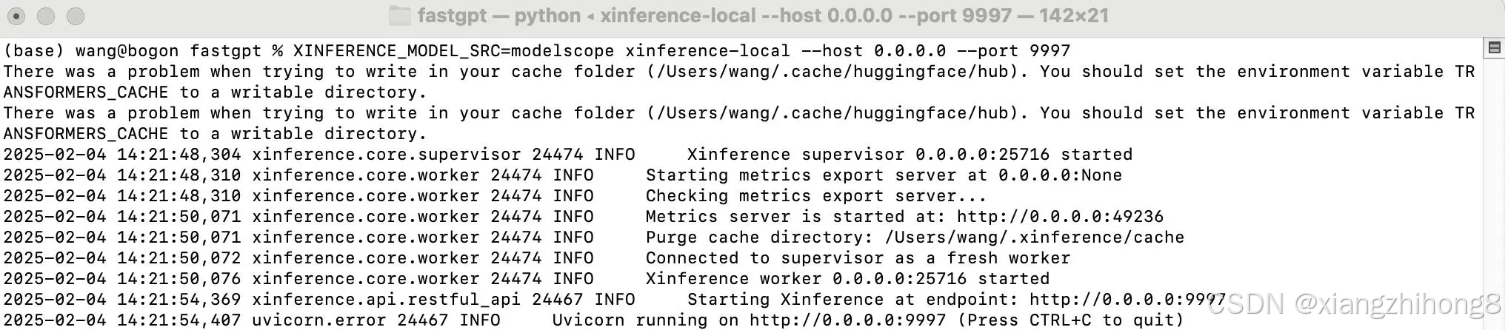
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
默认情况下,Xinference 服务会启动在 http://localhost:9997。
如果运行报错:
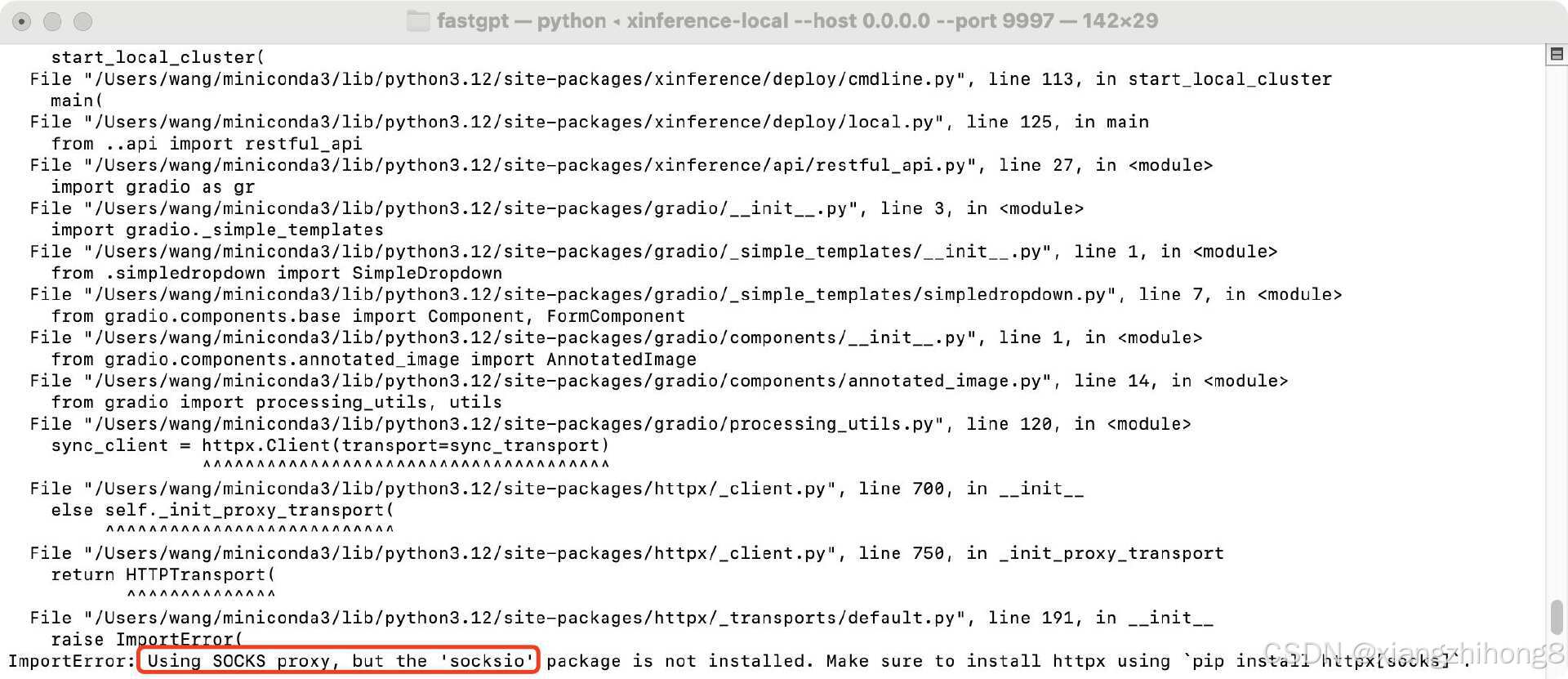
执行下面的命令,安装socket库:
pip install socksio

运行成功后的界面:
四. 验证安装
打开浏览器访问 http://localhost:9997,如果看到 Xinference 的 Web UI 界面,则说明安装成功。
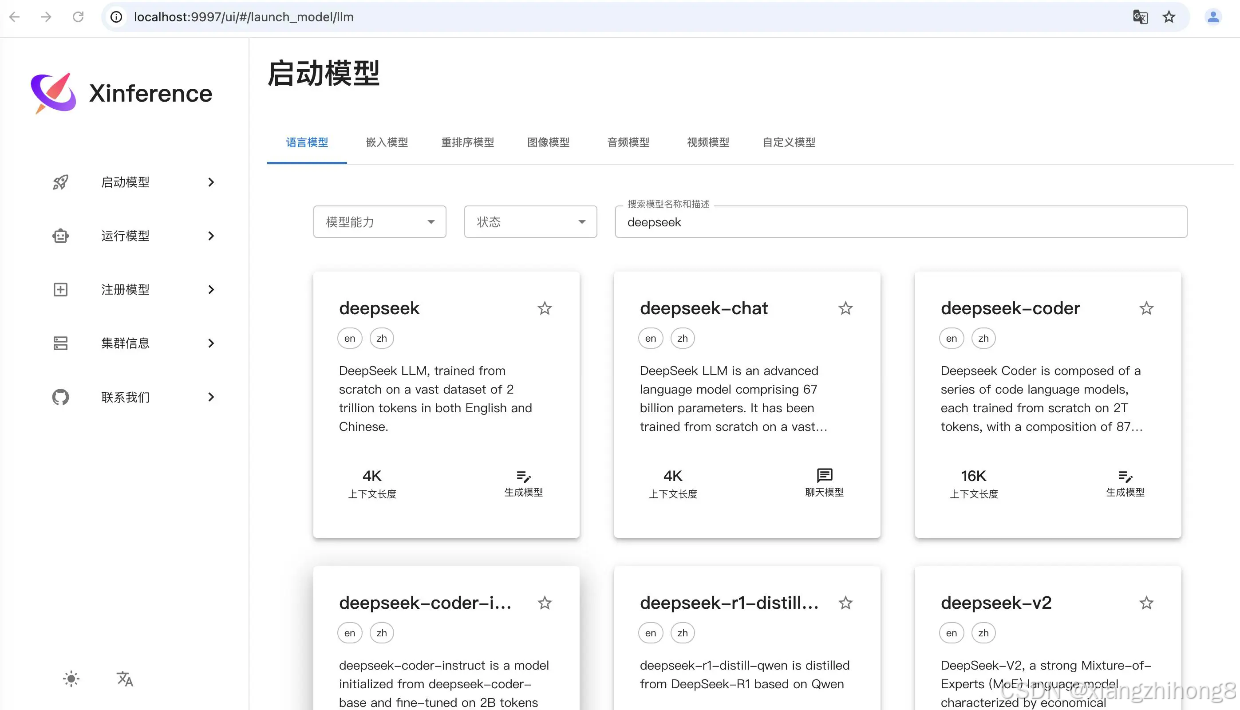
4.1 Xinference 基础使用
添加模型
安装下图的顺,依次选择即可。
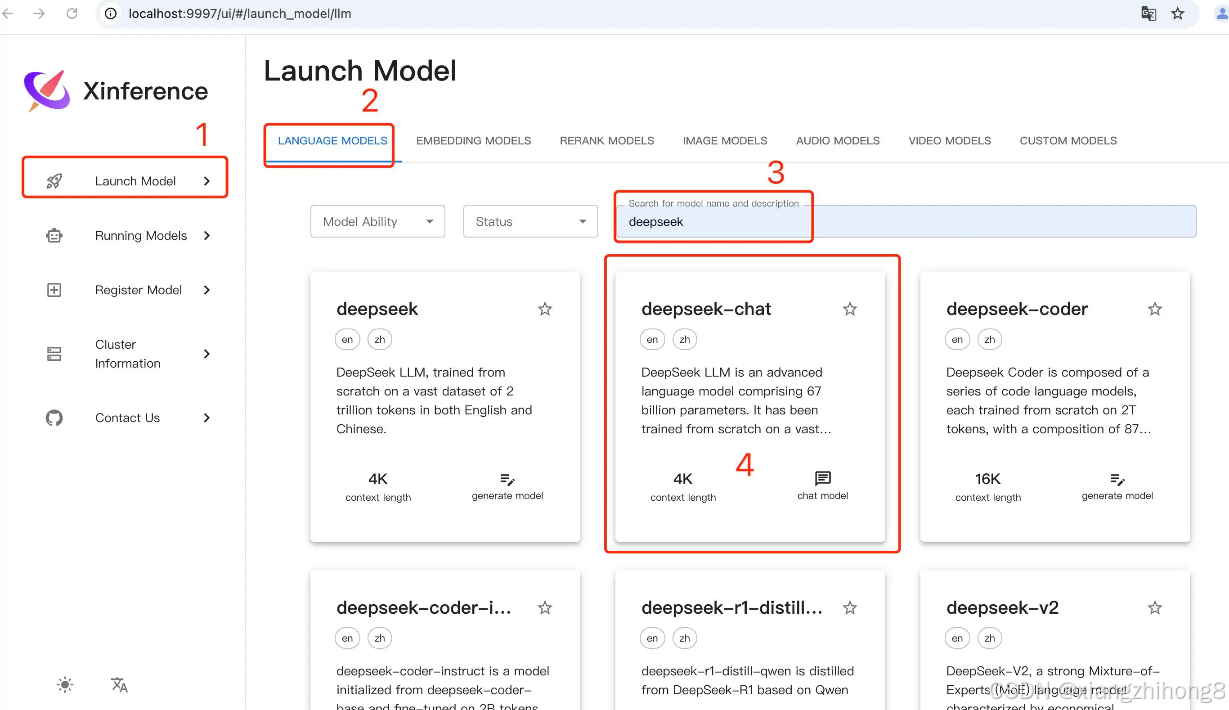
选择模型的大小:
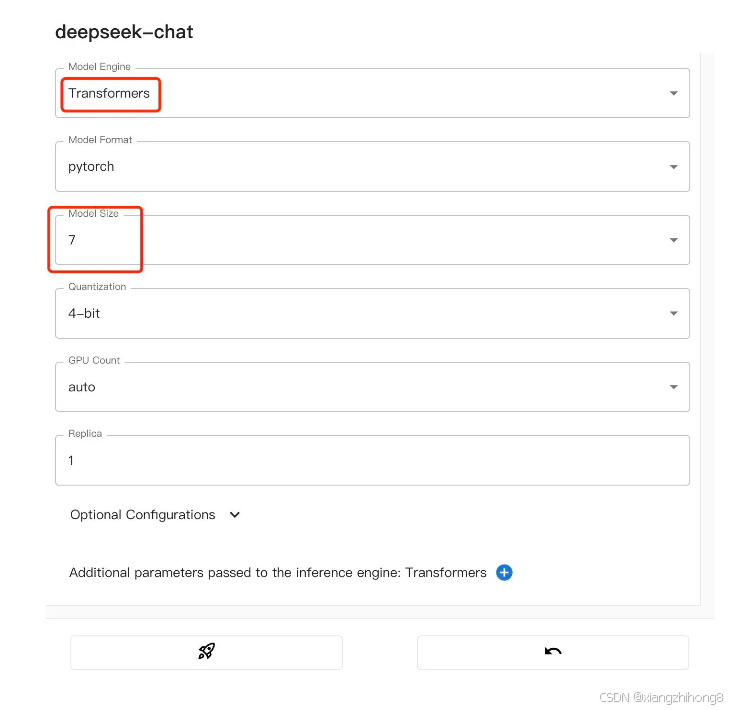
我们点击下面的火箭按钮开始部署后,在我们刚刚启动的终端中,可以看到模型的下载过程:
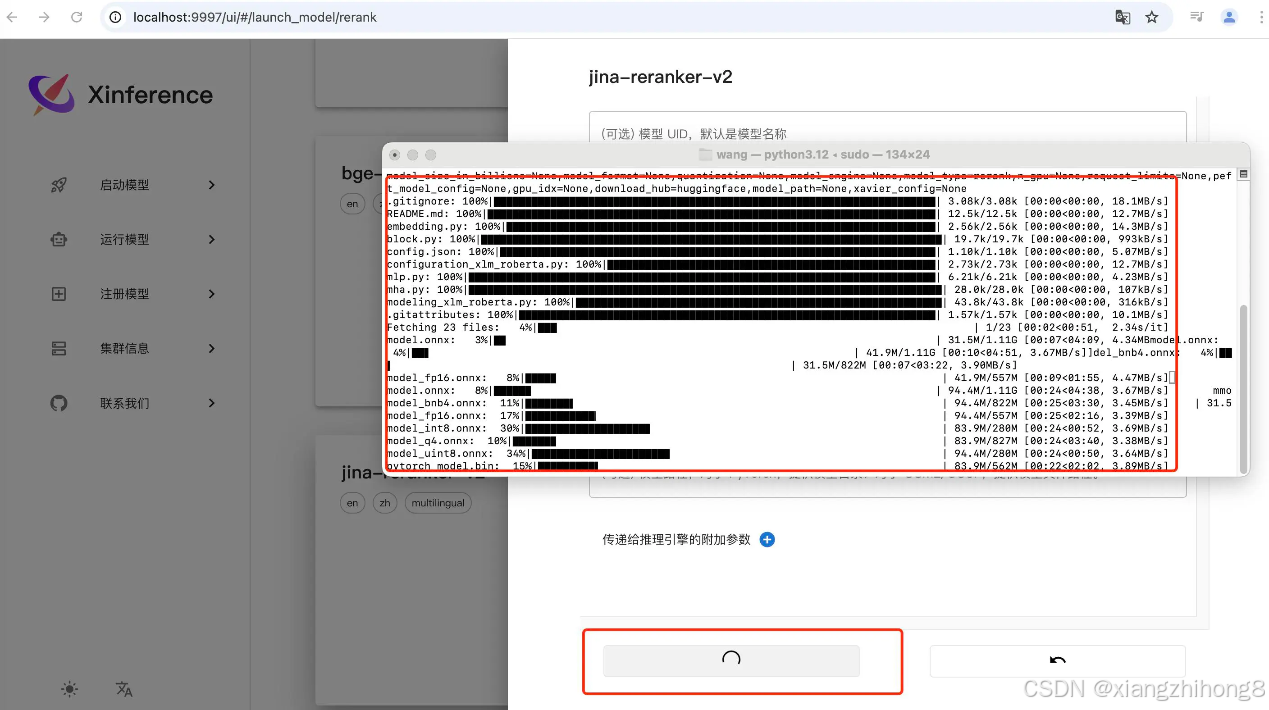
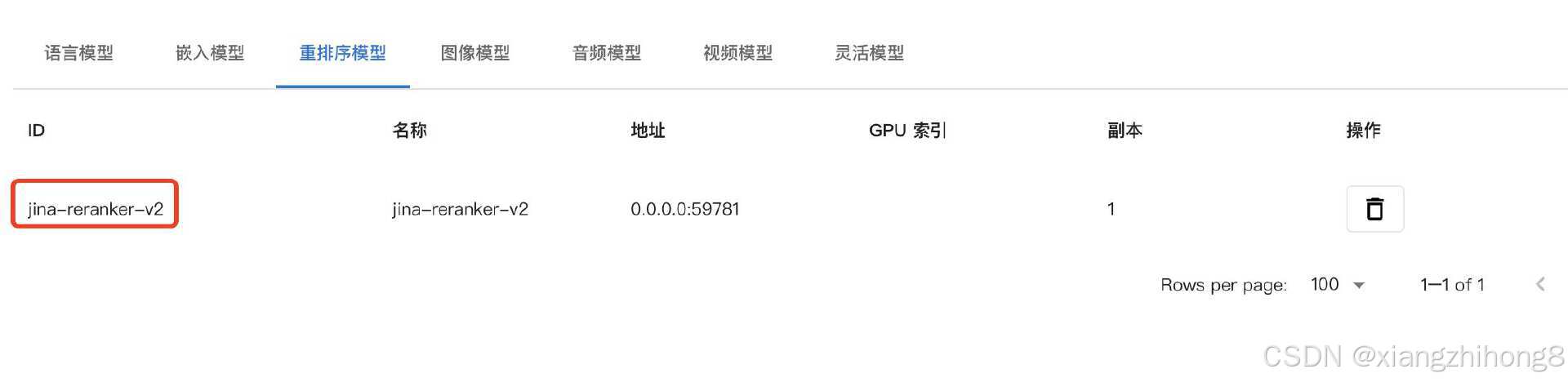
我们今天添加3个模型,分别是DeepSeek模型,Embedding模型和Reranker模型。
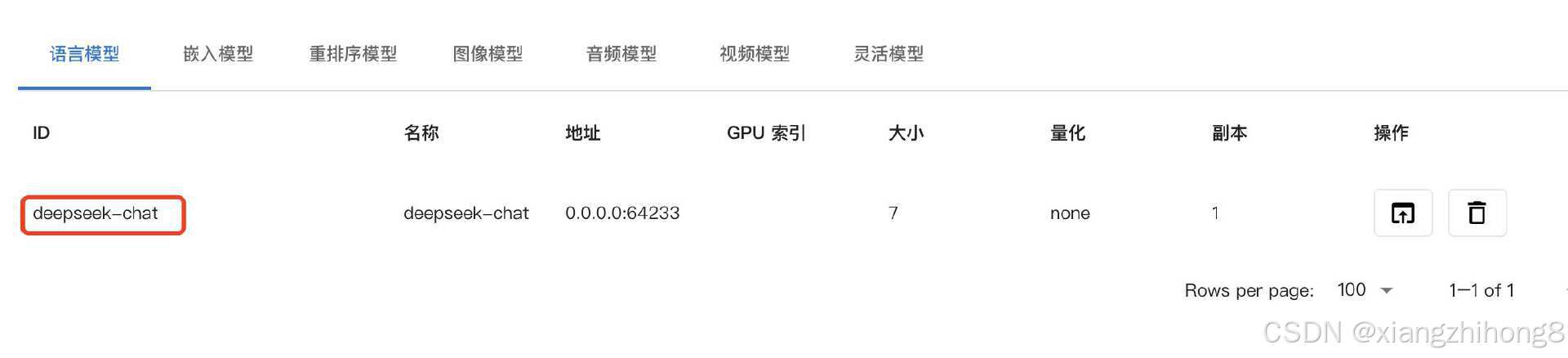

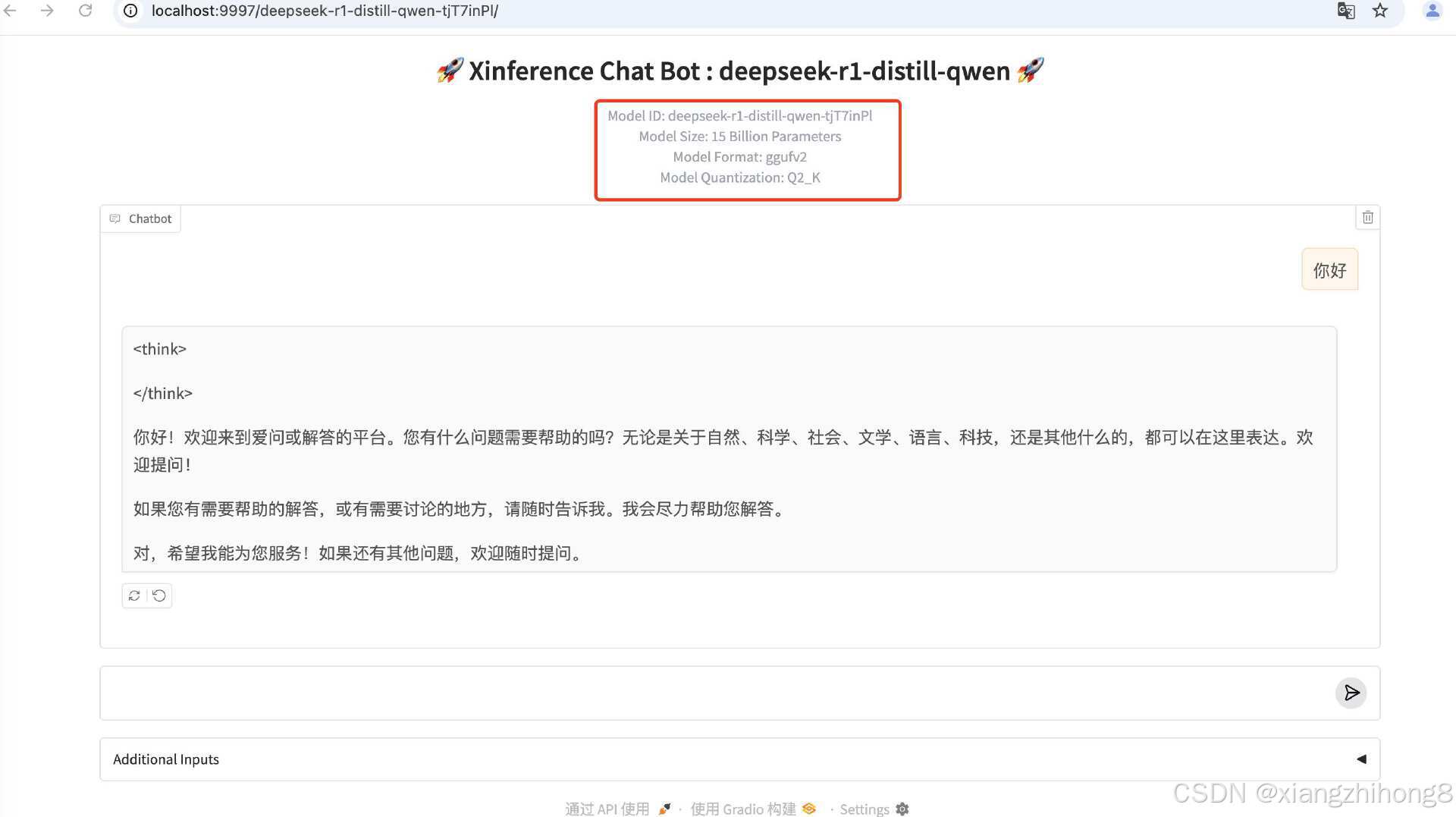
与模型交互
可以使用页面交互直接与模型 交互。
4.2 Xinference 集成应用
Xinference 的一个重要优势是其 OpenAI API 兼容性,这使得它可以轻松集成到许多支持 OpenAI API 的应用中。以下分别介绍如何将 Xinference 集成到 Chatbox、Dify 和 AnythingLLM 中。
集成 Chatbox
Chatbox 是一个流行的跨平台 AI 对话客户端,支持自定义 OpenAI API 服务。
步骤:
-
启动 Xinference 服务和模型实例 (如 deepseek)。
-
打开 Chatbox 应用,进入设置界面 (通常在左下角 "设置" 按钮)。
-
在 "模型提供商" 中,选择 "OpenAI Compatible API"。
-
在 "API 域名" 中,输入 Xinference 的 API 端点地址:http://localhost:9997/v1
-
API Key 可以留空,因为 Xinference 默认不需要 API Key。
-
点击 "保存" 或 "应用" 按钮。
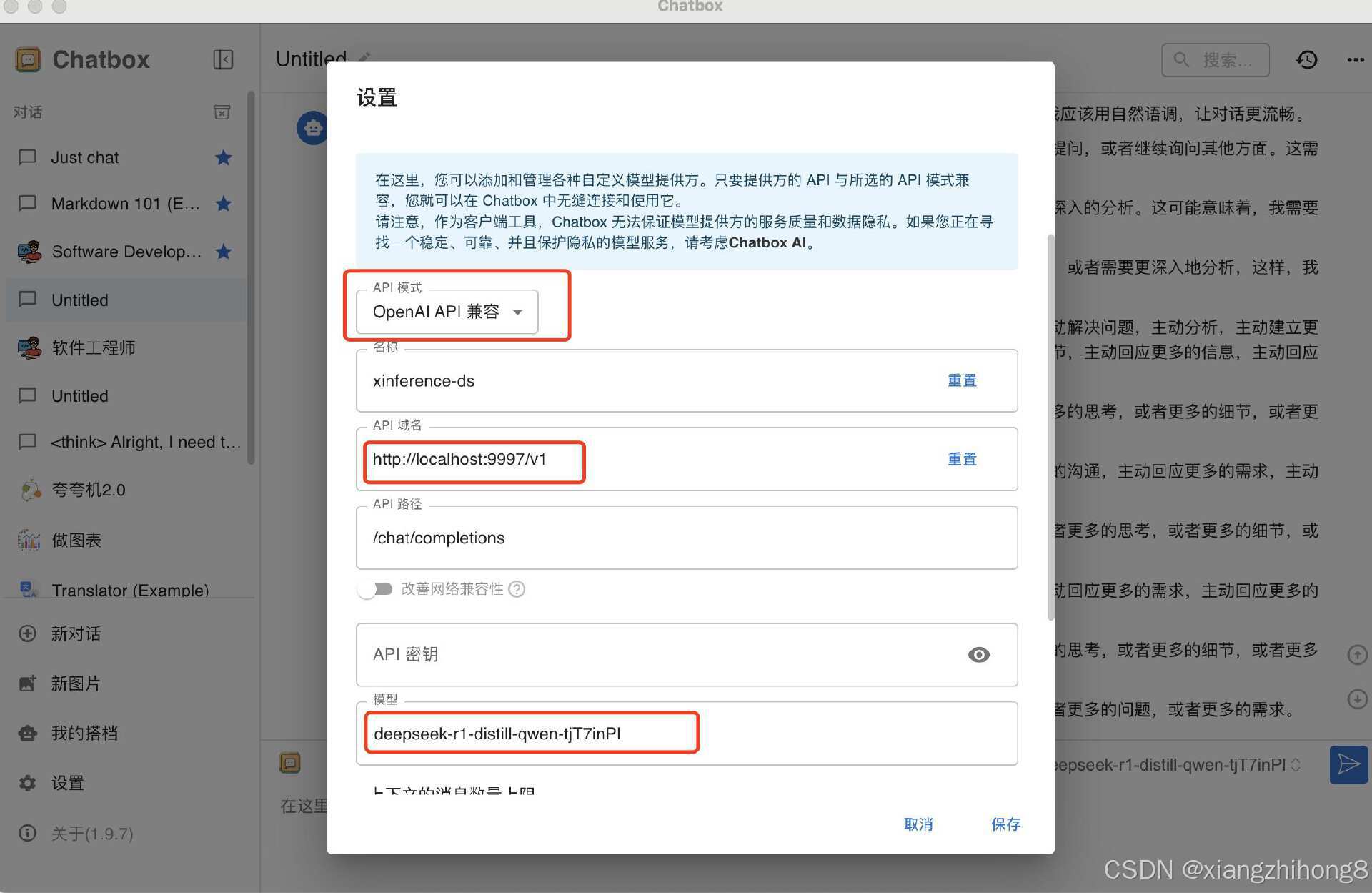
现在,你就可以在 Chatbox 中选择 Xinference 提供的模型 (例如deepseek-r1-distill-qwen-tjT7inPl) 进行对话了。
集成 Dify
Dify 是一个强大的 LLM 应用开发平台,可以用于构建各种 AI 应用,包括聊天机器人、知识库、自动化工作流等。
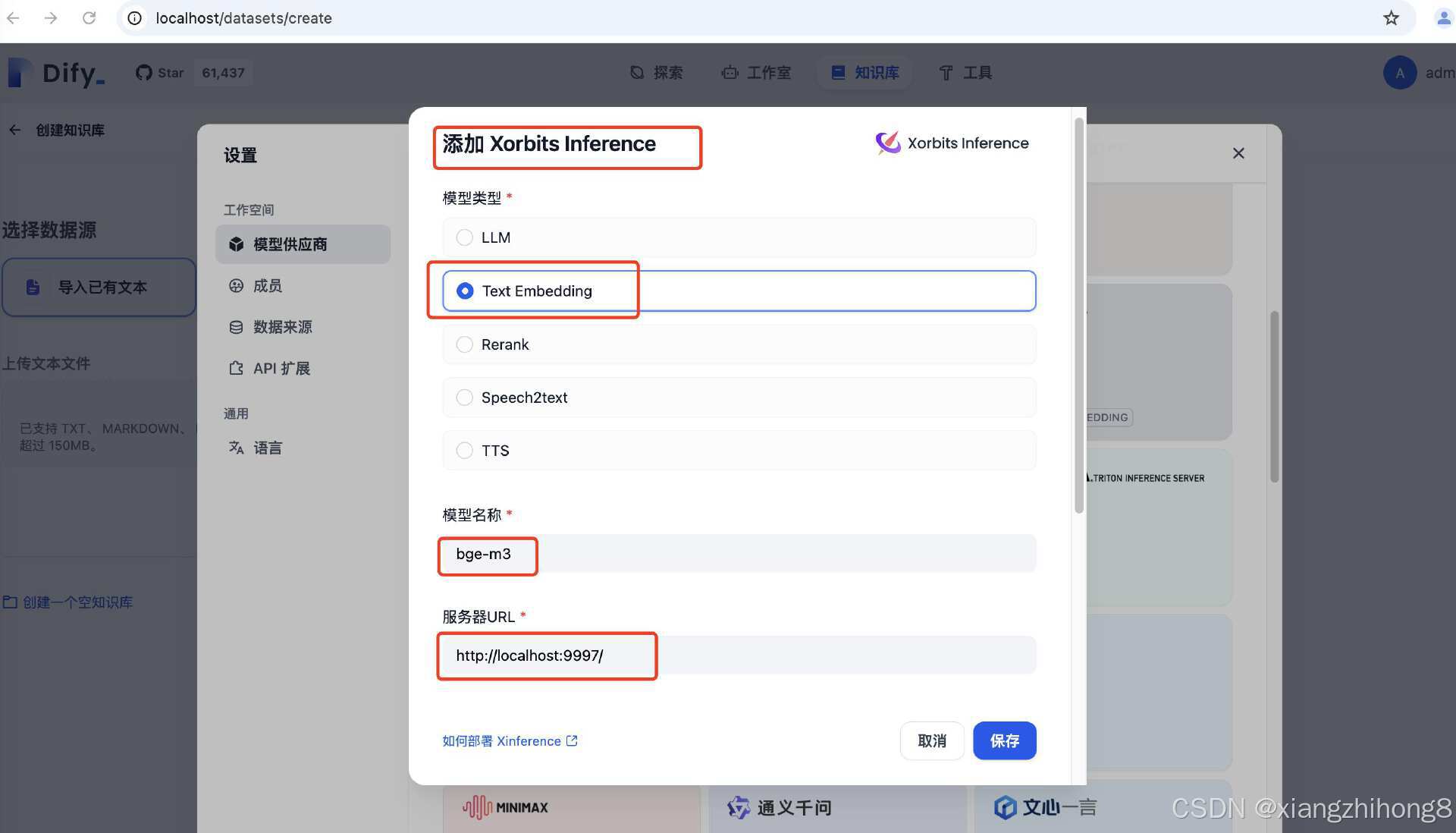
增加Embedding,模型名称和服务器URL都按图填写就可以。
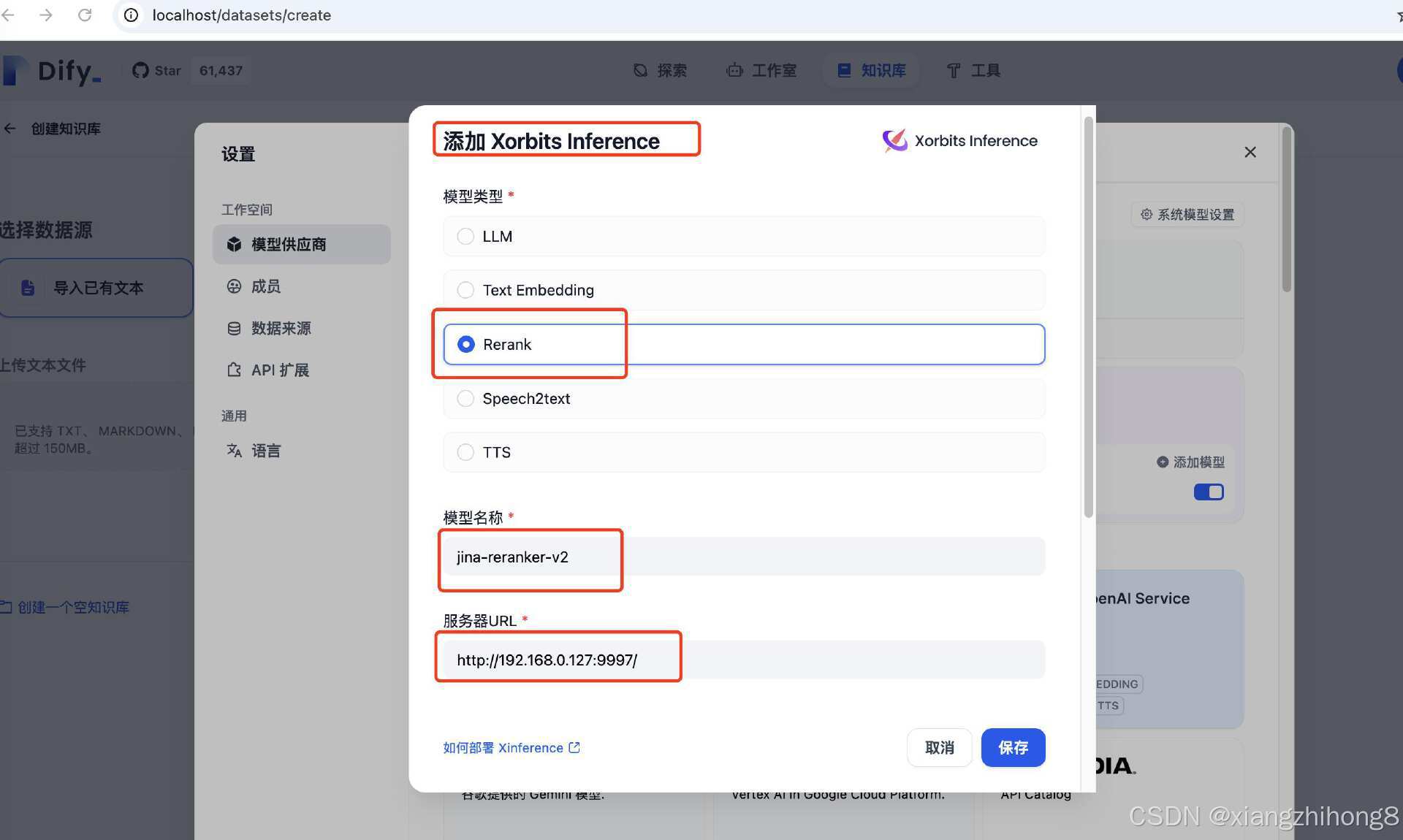
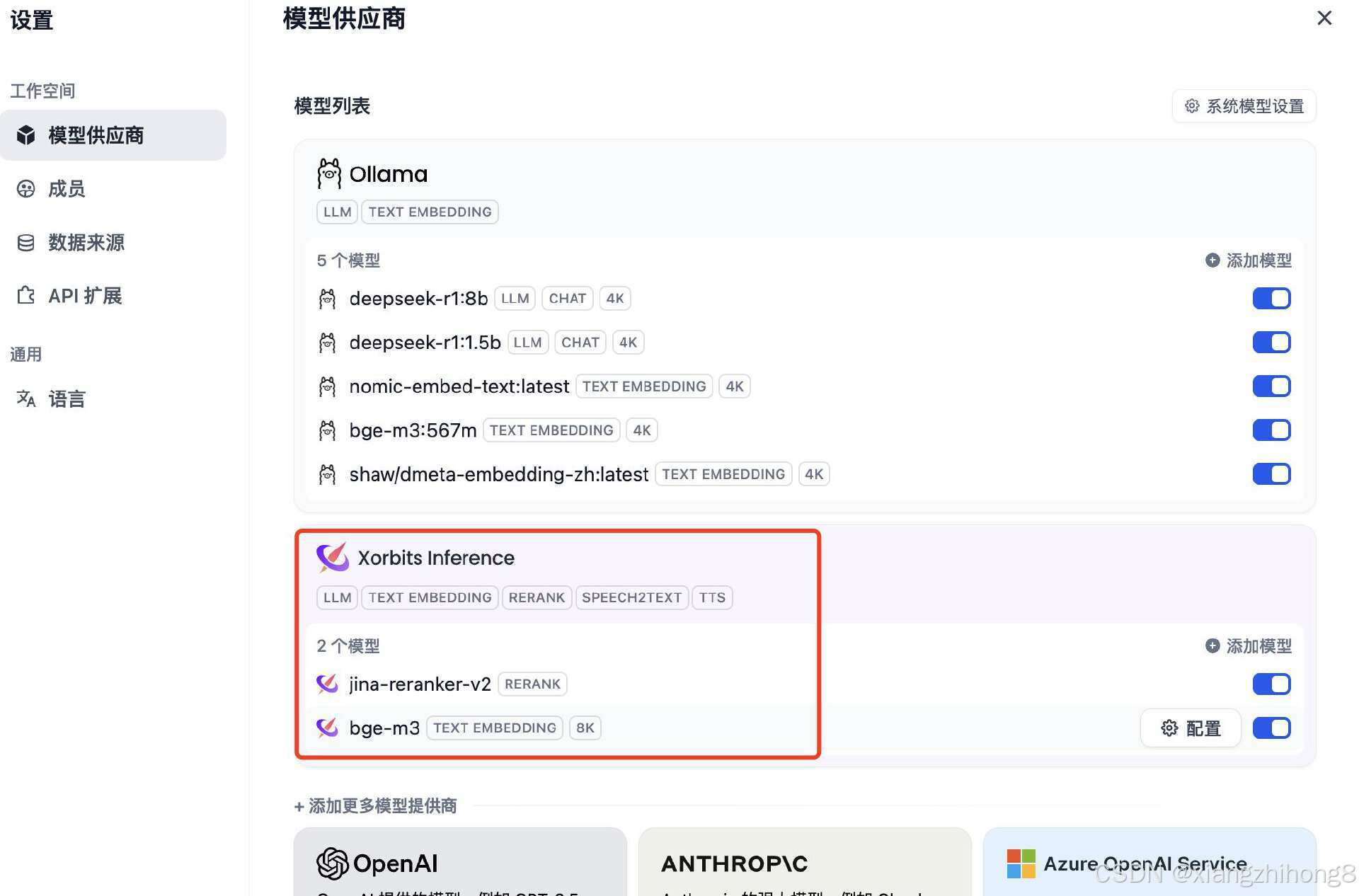
嵌入模型和重排模型都添加后的如下图:
添加知识库如下图:
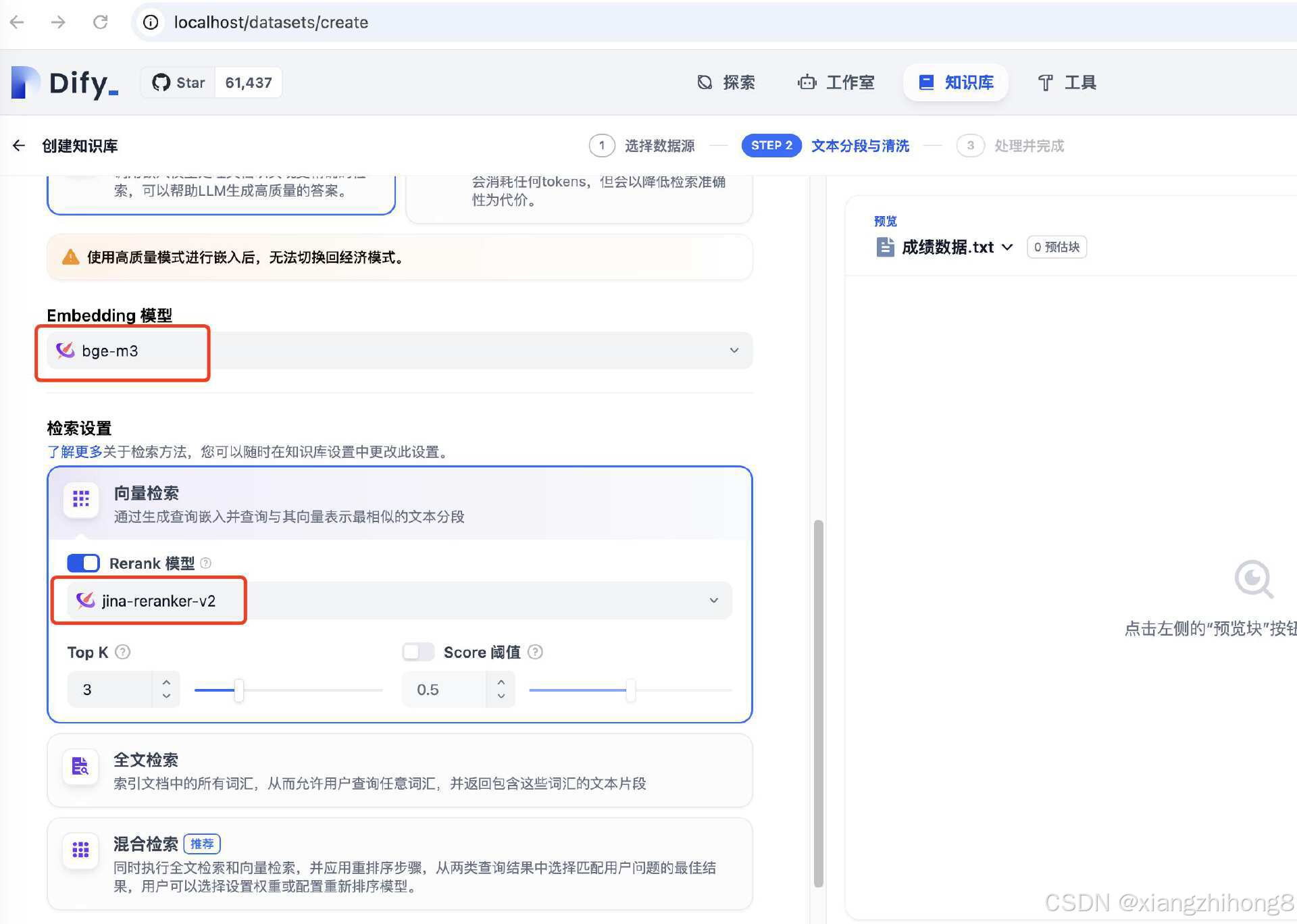
现在可以利用 Dify 的 RAG (Retrieval-Augmented Generation) 功能,结合 Xinference 构建本地私有知识库应用。



















 7517
7517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











