







1、简单读写操作
读操作
import pandas as pd
file_name = u'文件名.xlsx'
excel_file = os.getcwd() + ‘/’ + file_name
data = pd.read_excel(excel_file, sheet_name=0, header=0)
其中sheet_name表示excel文档中的sheet表,要取起一个sheet,sheet_name=0,以此类推。
header表示列表名是在哪一行出现,如果是第一行,则header=0,以此类推。
写操作
data.to_excel(os.getcwd() + ‘/文件名.xlsx’, encoding='utf_8_sig', index= False) #data的属性是dataframe
index = Flase代表写进excel的时候不自动加进的index这一列。
2、根据一列分组
比如应用中想要按照一列进行分组,下面的例子是按照人名分组,人名相同的为一组,然后组内按照课程分数进行排序。
# 根据"人名"分组
listType = data[u'人名'].unique()
data_remo = pd.DataFrame(columns=data.columns) # 新建一个空dataframe,用于存储去重后的dataframe
for i in listType:
data_group = data[data[u'人名'].isin([i])]
data_group = data_group.sort_values(by=[u"课程分数"], ascending=True)
# data_group = data_group.iloc[[0]] #如果想取值,去重,取这个人最高分数,则ascending=False,然后加上这一句
data_remo = data_remo.append(data_group, ignore_index=True)
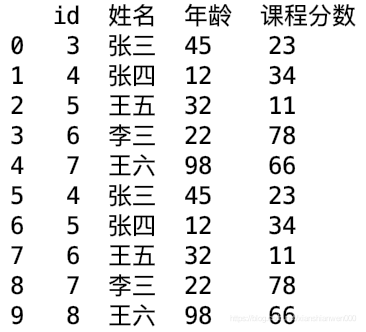
下图是原始的dataframe和分组后的dataframe
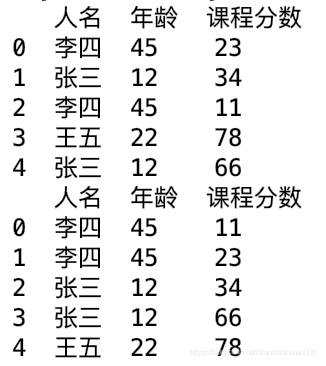
3、按照条件合并两个表
merge,只记录这个我用的多的。
和数据库相似,比如左链接
data1为左表,data2为右表
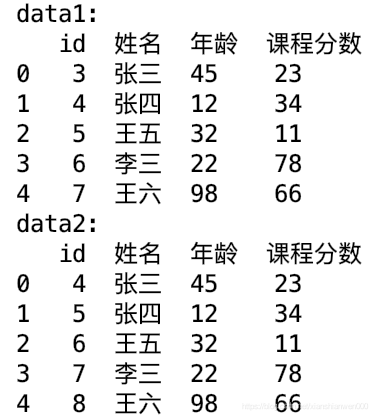
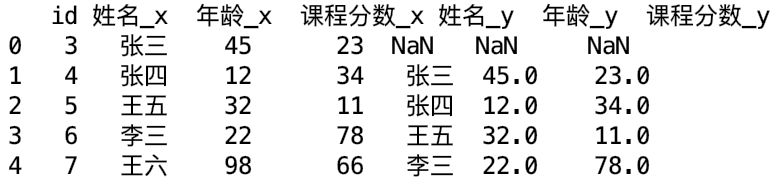
data_final = data1.merge(data2, how = 'left', left_on = 'id', right_on = 'IP')
print data_final
结果:
4、添加行
以data1和data2为例
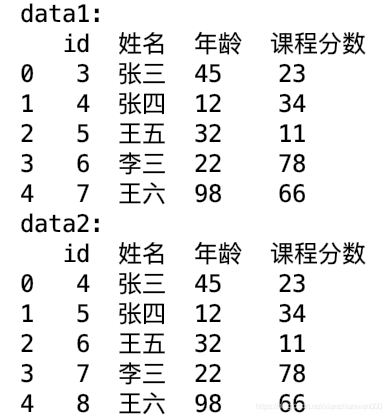
data_final = data1.append(data2, ignore_index=True)
print data_final
结果:
5、根据列中特定条件选择行
取id为5和6的行
data = data_final[data_final['id'].isin([5,6])]
结果:















 9001
9001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









