









前几天面试被问到“大数据量下如何做分页”。
大数据量分页的消耗在于要捞出很多不必要的数据,
优化思路:先查出条件分页后的记录id,再根据这个id去捞确切的数据,此时由于走了主键索引,查询会很快
有个博客写得不错:海量数据分页处理方案
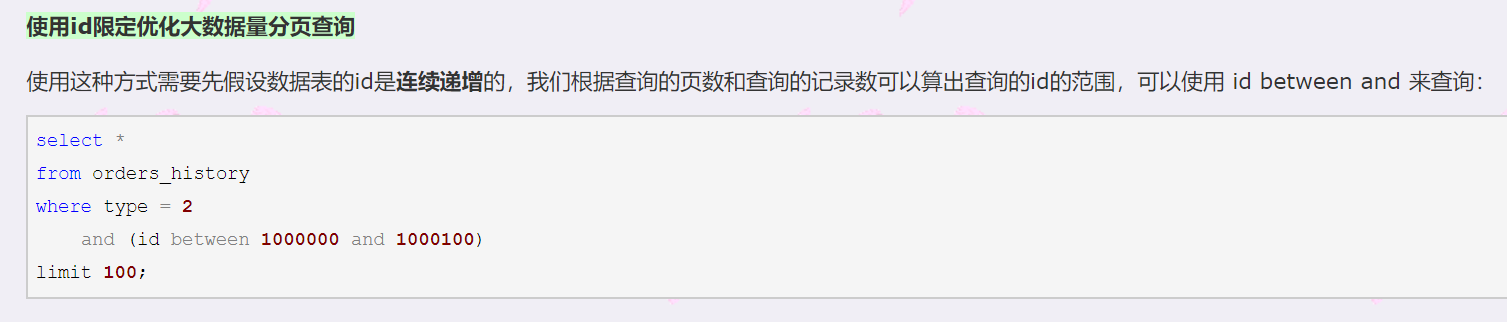
使用in查询理论上也可以,但是使用in时,如果id太离散了可能就不会走索引了:
select... from table where id in (分页查询出对应记录的id)
解决方式
对超过特定阈值的页数进行 SQL改写:
SELECT
a.*
FROM
`sys_user` a,
( SELECT id FROM `sys_user` LIMIT 4000000, 20 ) b
WHERE
b.id = a.id
将语句抽离成一个可以复用的sql
SELECT a.*
FROM 表 1 a,
(select id from 表 1 where 条件 LIMIT 100000,20 ) b
where a.id=b.id
原理
利用覆盖索引来进行查询操作,避免回表
我们语句中的覆盖索引就使用的就是
SELECT id FROM `sys_user` LIMIT 4000000, 20
这条sql直接拿到我们要查询的20条数据的id,再去表中查询它的具体数据















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









