









攻防世界Misc入门题之base64stego
继续开启全栈梦想之逆向之旅~
这题是攻防世界Misc入门题之base64stego
下载附件,解压,要密码,但是题目没有给密码:
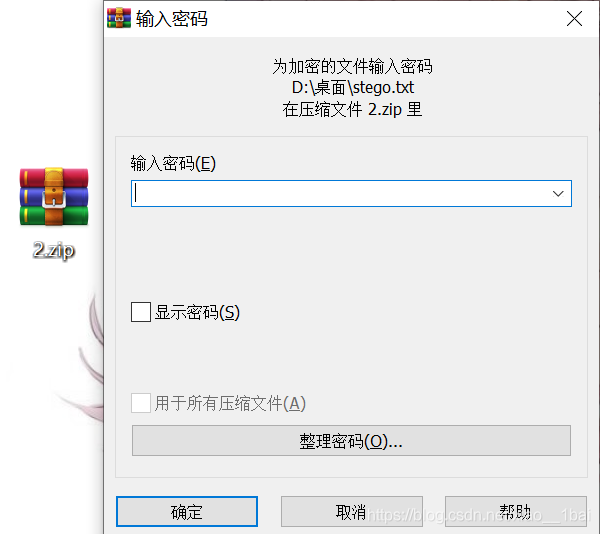
查资料,说是伪加密,推荐一篇好博客:
https://www.cnblogs.com/wushengyang/p/12436393.html
引用里面的话:
ZIP伪加密
一个ZIP文件由三个部分组成:压缩源文件数据区+压缩源文件目录区+压缩源文件目录结束标志。
伪加密原理:zip伪加密是在文件头的加密标志位做修改,进而再打开文件时识被别为加密压缩包。一般来说,文件各个区域开头就是50 4B,然后后面两个字节是版本,再后面两个就是判断是否有加密的关键了。
比如这题:
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50) 14 03:解压文件所需 pkware 版本 00
00:全局方式位标记(判断有无加密的重要标志) 08 00:压缩方式 68 BF:最后修改文件时间 9B 48:最后修改文件日期 FE 32
7D 4B:CRC-32校验 E9 0D 00 00:压缩后尺寸 B5 1B 00 00:未压缩尺寸 09 00:文件名长度 00
00:扩展记录长度压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50) 3F 03:压缩使用的 pkware 版本 14 03:解压文件所需
pkware 版本 00 00:全局方式位标记(有无加密的重要标志,这个更改这里进行伪加密,改为09 00打开就会提示有密码了) 08
00:压缩方式 68 BF:最后修改文件时间 9B 48:最后修改文件日期 FE 32 7D 4B:CRC-32校验(1480B516)
E9 0D 00 00:压缩后尺寸(25) B5 1B 00 00:未压缩尺寸(23) 09 00:文件名长度 24 00:扩展字段长度
00 00:文件注释长度 00 00:磁盘开始号 00 00:内部文件属性 20 80 ED 81:外部文件属性 00 00 00
00:局部头部偏移量压缩源文件目录结束标志:
50 4B 05 06:目录结束标记 00 00:当前磁盘编号 00 00:目录区开始磁盘编号 01 00:本磁盘上纪录总数 01
00:目录区中纪录总数 5B 00 00 00:目录区尺寸大小 10 0E 00 00:目录区对第一张磁盘的偏移量 00 00:ZIP
文件注释长度然后就是识别真假加密
1.无加密 压缩源文件数据区的全局加密应当为00 00 且压缩源文件目录区的全局方式位标记应当为00 00
2.假加密 压缩源文件数据区的全局加密应当为00 00 且压缩源文件目录区的全局方式位标记应当为09 00
3.真加密 压缩源文件数据区的全局加密应当为09 00 且压缩源文件目录区的全局方式位标记应当为09 00然后这题全局为00 00 但是在结尾发现是09 00,所以为假加密,把09 00 改成00 00就能解压打开文件了。



说得非常透彻了,那么直接继续看它博客~(笑):
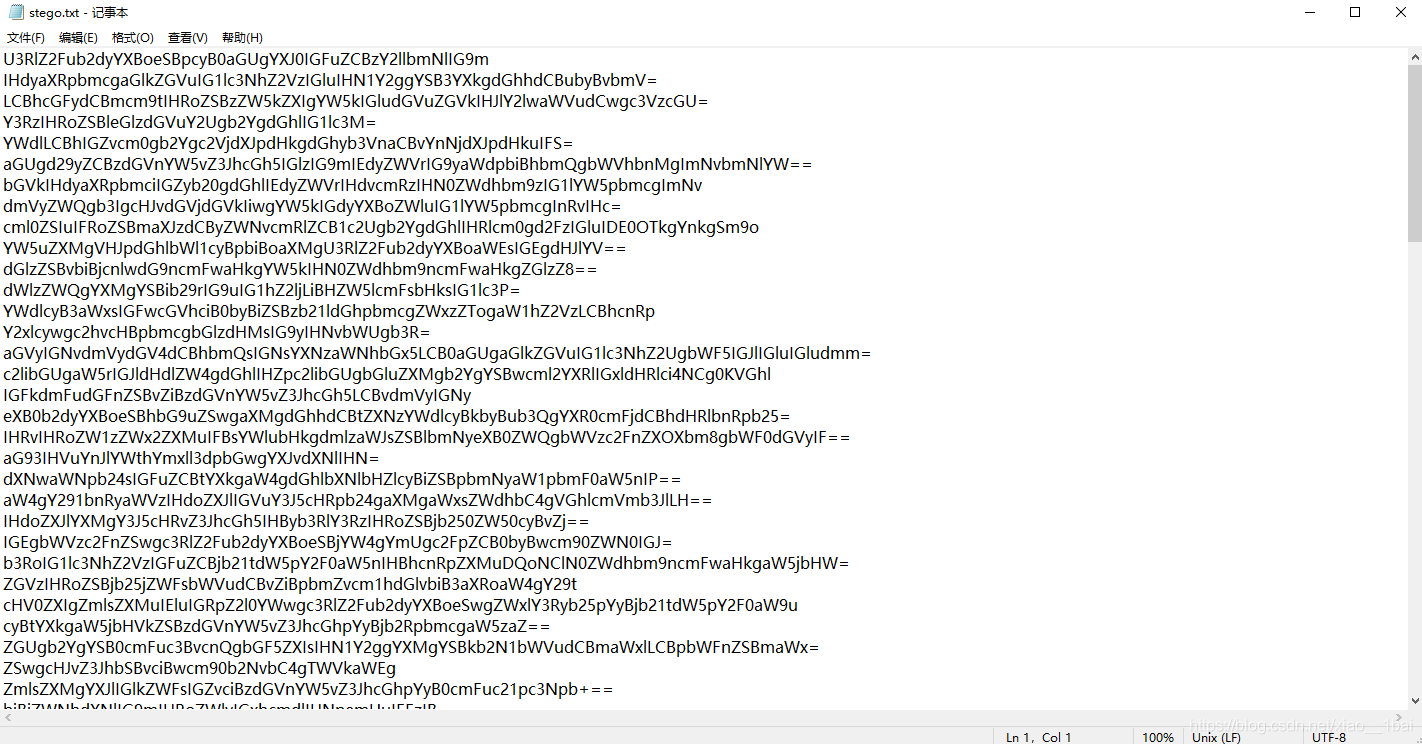
解压后下载txt文件,是一堆base64加密内容,但是简单base64解压后是一篇不相关的文章:
后来发现这是一道当年的俄罗斯的题目,是base64隐写题,原理如下:
我们知道,base64是6bit编为1个字符,而1个字节是8bit,因此base64可能会出现3种情况:刚好能编完(例如3个字节的字符串base64加密后有4个字符)、剩余2bit(例如2个字节的字符串base64加密后第3个字符只编码了4bit,此时使用=补充6bit)、剩余4bit(例如1个字节的字符串base64加密后第2个字符只编码了2bit,此时使用==补充12bit),由于第3/2个字符只编码了4/2bit,所以只有前面被编码的bit是有效的,而后面的bit则在正常情况下默认填0,因此可以将想隐写的数据隐藏在后面的bit中,即:1个=可以隐藏2个bit
我们将这些bit读出来,拼在一起转换为字符串即可获得flag
————————————————
版权声明:本文为CSDN博主「古月浪子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tqydyqt/article/details/102002577
直接上解密脚本:
import base64
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('stego.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = str(line, "utf-8").strip("\n")
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), "utf-8").strip("\n")
offset = abs(b64chars.index(stegb64.replace('=', '')[-1]) - b64chars.index(rowb64.replace('=', '')[-1]))
equalnum = stegb64.count('=') # no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print(''.join([chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)])) # 8 位一组
结果输出:
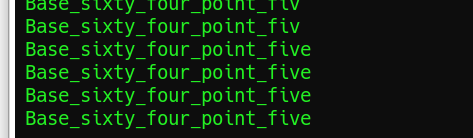
总结:杂项嘛,积累呀积累,就这样吧,开阔了视野,知道了伪加密,收集了个base64隐写脚本。















 7454
7454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











