含义
|
?
|
出现零次或一次(最多出现一次)
|
+
|
出现一次或多次(至少出现一次)
|
*
|
出现零次或多次(任意次)
|
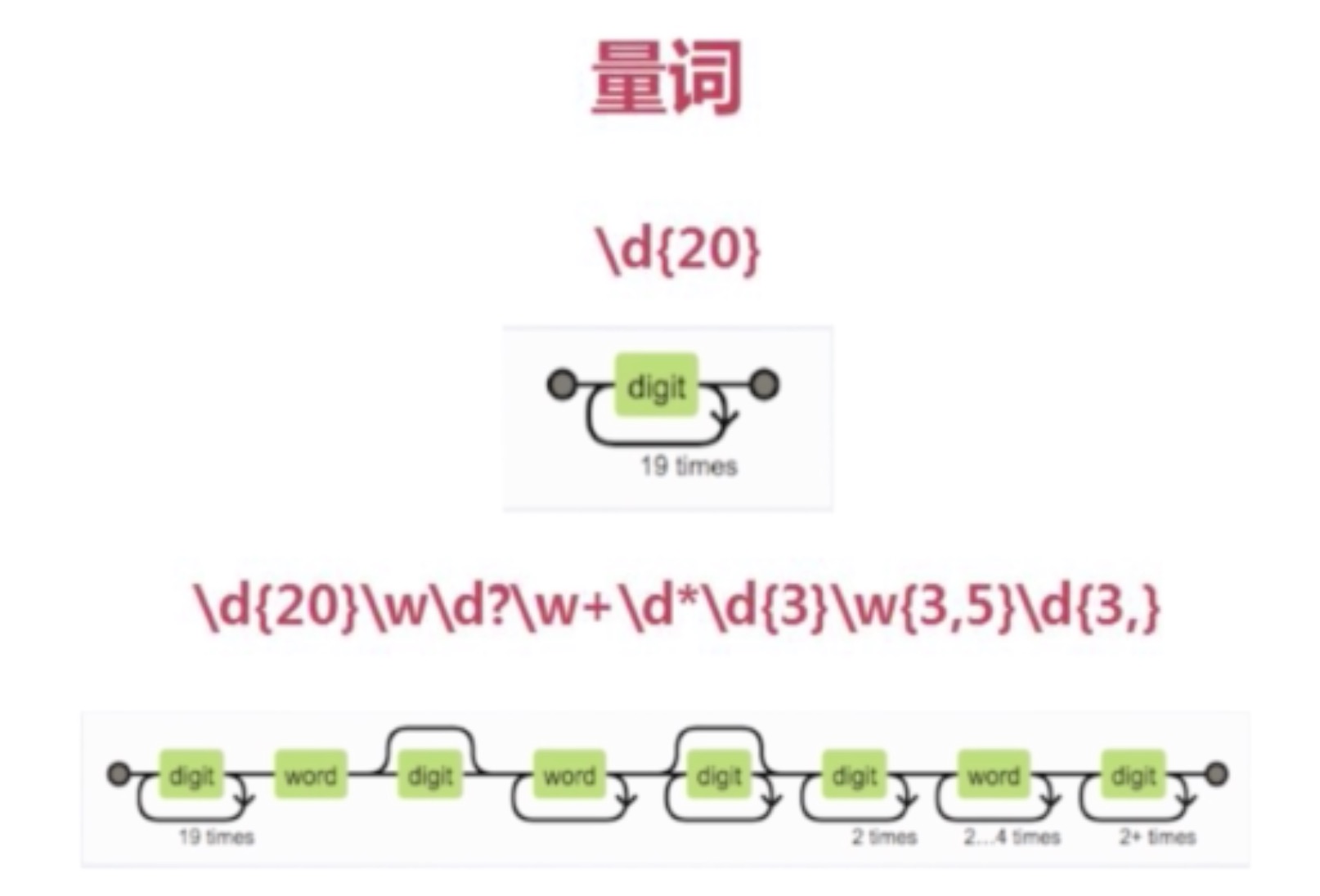
{n}
|
出现n次
|
{n,m}
|
出现n到m次
|
{n,}
|
至少出现n次
|
‘12345678’.replace('/\d{3,6}/g','X') ==========>结果:'X78'
12.非贪婪模式
1.让正则表达式尽可能少的匹配,也就是说一旦成功匹配不再继续尝试就是非贪婪模式
2.做法很简单,在两次后加上?即可
'12345678'.replace('/\d{3,6}?/g','X') ==========>结果:'XX78'
13.分组
1.匹配字符串byron连续出现3次的场景,会这么写byron{3},但这么写,只会 n 匹配3次,并非整个单词
2.使用()可以达到分组的功能,使两次作用于分组。然后就可以这么写 (byron){3}
'a1b2c3d4'.replace(/[a-z]\d{3}/g,'X') ===============>结果:'a1b2c3d4'
'a1b2c3d4'.replace(/([a-z]\d){3}/g,'X') ===============>结果:'Xd4'
'ByronCasper'.replace(/Byron|Casper/g,'X') ==============>结果:'XX'
'ByronsperByrCasper'.replace(/Byr(on|Ca)sper/g,'X') ==============>结果:'XX'
‘2015-12-25’.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$1') ===========>结果:'2015'
‘2015-12-25’.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$2') ===========>结果:'12'
‘2015-12-25’.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$3') ===========>结果:'25'
‘2015-12-25’.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$2/$3/$1')===========>结果:'12/25/2015'
14.忽略分组
1.不希望捕获某些分组,只需要在分组哪加上?:就可以(?:byron).(ok)
意思是匹配上了,括号里的不会被$1获取
例子1:
'A1okB2ok'.replace(/(?:[A-Z]).(ok)/g,'B') ===========》结果:"BB"
'A1okB2ok'.replace(/([A-Z]).(ok)/g,'$1$2')===========》结果:"AokBok"
'A1okB2ok'.replace(/(?:[A-Z]).(ok)/g,'$1$2')===========》结果:"ok$2ok$2" ps:
(?:[A-Z]) 被忽略了,不能被$获取了
15.前瞻
1.正则表达式从文本头部向尾部开始解析,文本为不方向,称为前
2.前瞻就上在正则表达式匹配到规则的时候,向前检查是否符合断言,后顾/后瞻方向相反
3.javascript不支持后顾
4.符合和不符合特定断言称为 肯定/正向 匹配和 否定/负向 匹配
名称
正则
|
含义
|
正向前瞻
|
exp(?=assert)
|
| |
负向前瞻
|
exp(?!assert)
|
| |
正向后顾
|
exp(?<=assert)
|
javascript不支持
|
负向后顾
|
exp(?<!assert)
|
javascript不支持
|
例子1:
'a2*3'.replace(/\w(?=\d)/g,'X')=========>结果:'X2*3'
'a2*34v8'.replace(/\w(?=\d)/g,'X')=========>结果:'X2*X4X8'
'a2*34vv'.replace(/\w(?=\d)/g,'X')=========>结果:'X2*X4vv'
'a2*34vv'.replace(/\w(?!\d)/g,'X')=========>结果:'aX*3XXX'
15.对象属性
1. g: global全文搜索,不添加,搜索到第一个匹配停止 默认 false
2. i: ignore case 忽略大小写,不添加,大小写就会区别开来 默认 false
3. m: multiple lines 多行搜索默认 false
4. lastIndex:是当前表达式匹配内容的最后一个字符的下一个位置
5. source:正则表达式的文本字符串
'He is a boy .Is he?'.replace(/\bis\b/g,'0') ====> 结果 'He 0 a boy.Is he?';
'He is a boy .Is he?'.replace(/\bis\b/gi,'0') ====> 结果 'He 0 a boy.0 he?';
muStr.replace(/^@\d/g,'Q') ====> 结果:
(为什么会是这样的结果,因为存在隐藏回车换行符的原因,所以就第一个被匹配了)
muStr.replace(/^@\d/gm,'Q') ====> 结果:
console.info(reg1.global )=============> '结果:false
console.info(reg1.ignoreCase )=============> '结果:false
console.info(reg1.multiline )=============> '结果:false
console.info(reg1.global )=============> '结果:false
console.info(reg1.source )=============> '结果:"\w"
console.info(reg2.global )=============> '结果:true
console.info(reg2.ignoreCase )=============> '结果:true
console.info(reg2.multiline )=============> '结果:true
console.info(reg2.global )=============> '结果:true
console.info(reg2.source )=============> '结果:"\w"
reg1.global = true //这些属性是只读的,不能更改
console.info(reg1) ===============>false;
16.test和exec的方法
1.RegExp.prototype.test(str)用于测试字符串参数中是否存在匹配正则表达式模式的字符串
如果存在则返回true,否则返回false
var reg = /\w/;
var reg1 = /\w/g;
console.info(reg.test('a')) =======>结果:true
console.info(reg.test('$')) =======>结果:false
console.info(reg.test('$')) =======>结果:false
console.info(reg.test('$')) =======>结果:false
console.info(reg1.test('ab')) =======>结果:true
console.info(reg1.test('ab')) =======>结果:true
console.info(reg1.test('ab')) =======>结果:false
console.info(reg1.test('ab')) =======>结果:true
console.info(reg1.test('ab')) =======>结果:true
console.info(reg1.test('ab')) =======>结果:false
while(reg2.test('ab')){
console.info(reg1.lastIndex);
}
结果为:
1
2
2.RegExp.prototype.exec(str) 使用正则表达式模式对字符串执行搜索,并将更新全局RegEx对象的数学已反映匹配结果
如果没有匹配的文本则返回null,否则返回一个结果数组
还有两个额外的属性
- index 声明匹配文本的第一个字符的位置
- input 存放被检索的字符串 string
返回的数组
第一个元素是与正则表达式想匹配的文本
第二个元素是 RegExpObject 的第一个字表达式相匹配的文本(如果有的话)
第二个元素是 RegExpObject 的第二个字表达式相匹配的文本(如果有的话),以此类推
var reg1 = /\d(\w)(\w)\d/;
var reg2 = \/d(\w)(\w)\d/g
var str = '*1az2bb3cy4dd5ee'
var ret = reg1.exec(str);
console.info(reg1.lastIndex+'\t')+ret.index+'\t'+ret.toString());
console.info(reg1.lastIndex+'\t')+ret.index+'\t'+ret.toString());
结果:
"0 1 1az2,a,z"
"0 1 1az2,a,z"
["1az2","a","z"]
ps:
非全局调用lastIndex都是0
while(ret=reg2.exec(str)){
console.info(reg2.lastIndex+'\t')+ret.index+'\t'+ret.toString());
}
结果:
"5 1 1az2,a,z"
"11 7 3cy4,x,y"
17.字符串对象方法
var reg1 = /\d(\w)\d/
var reg2 = /\d(\w)\d/g
var ts ='*1a2b3c4d5e'
var ret = ts.match(reg1);
console.info(ret);
console.info(ret.index+'\t'+reg1.lastIndex);
结果:
["1a2","a"]
"1
0"
var ret = ts.match(reg2);
console.info(ret.index+'\t'+reg2.lastIndex);
1.String.prototype.split(reg)
我们经常使用split 方法吧字符串分割为字符数组
'a,b,c,d'.split(','); //['a','b','c','d']
'a,b,c,d'.split(/\d/); //['a','b','c','d']
2.String.prototype.replace(reg)
String.prototype.replace(str,replaceStr)
String.prototype.replace(reg,replaceStr)
String.prototype.replace(reg,function)
'a1b1c1'.replace('1',2)==========>结果:'a2b1c1'
'a1b1c1'.replace(/1/
,2)==========>结果:'a2b1c1'
'a1b2c3d4'.replace(/\d/g,function(match,index,origin){
'a1b2c3d4'.replace(/(\d)(\w)(\d)/g,function(match,group1,group2,group3,index,origin){
最后这是我所学这篇文章的视频网站,有兴趣的人,可以去看看
http://www.imooc.com/video/12538
console.info(reg1.test('ab')) =======>结果:false






















 9360
9360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









