







SQL执行的顺序
第一 步:使用from子句选择初始的表。
第二步:计算行函数,事实上,这是向初始表添加新行。
第三步:使用where子句选择哪些行的数据需要处理,删除所有不满足条件的行。
第四步:使用selecct子句选择要处理哪些列以及在结果表中列出哪些数据。这个过程也包括group by,having和order by子句中使用的其它列。删除所有其它的列。
第五步:group by 子句将行分为不同的组。
第六步:列函数汇总每一组的数据。
第七步:having子句选择将那些已汇总的数据行放到结果表中。
第八步:order by子句选择使用哪些列对结果表来排序。
标准的SQL语言的用法
SQL(Structured Query Language):结构化查询语言,但是实际上它除了具有数据查询功能,还具有数据定义,数据操纵和数据控制功能。
下图中列出SQL语言的类型。

1:数据完整性
当用户向数据库输入数据时,由于各种原因,用户有可能输入错误数据。保证输入的数据符合规定,成为数据库系统,尤其是多用户的关系数据库系统的首要关注的问题,为了解决这个问题,在数据库领域出现了数据完整性的概念。数据完整性(Data Integrity)就是指数据必须符合规范,它主要分为三类:实体完整性(Entity Integrity),域完整性(Domain Integrity)和参照完整性(Referential Integrity)。
(1):实体完整性
实体完整性规定表的每一行(即每一条记录)在表中是唯一实体。实体完整性通过表的主键来实现。如果把CUSTOMERS表的ID字段定义为主键。数据库系统会保证每条记录有唯一的ID值,当用户试图向CUSTOMERS中插入主键重复的记录时,数据库系统会禁止这一非法操作。
(2):域完整性
域完整性是指数据库表的列(即字段),必须符合某种特定的数据类型或约束。Not null约束就属于域完整性的范畴。如果CUSTOMERS表的NAME字段设置了not null约束,数据库系统就会保证NAME字段的取值不为null。当用户试图向CUSTOMERS表插入一条NAME字段值为null的记录时,数据库系统会禁止这一非法操作。
(3):参照完整性
参照完整性保证一个表的外键和另外一个表的主键对应。如果把ORDERS表的CUSTOMER_ID字段作为外键参照CUSTOMERS表的ID主键。那么数据库系统会保证主键与外键的对应关系,这体现在以下的几个方面。
-> 当用户试图向ORDERS表插入一条CUSTOMER_ID为1的记录时,如果在CUSTOMERS表中没有ID为1记录,数据库系统会禁止这一非法操作。
-> 当用户试图把ORDERS表中一条记录的CUSTOMER_ID改为1时,如果在CUSTOMERS表中没有ID为1的记录,数据库系统会禁止这一非法操作。
-> 当用户试图从CUSTOMERS表中删除ID为1的记录时(加入没有设置级联删除选项),如果在ORDERS表中还存在CUSTOMER_ID为1的记录,数据库系统会禁止这一非法操作。
2:DDL数据定义语言
DDL语言用于定义数据库中的表,视图和索引等。
-> create table 语句:创建一个表。
-> alter table 语句:修改一个表。
-> drop table 语句:删除一个表,同时删除表中所有的记录。
以下的SQL语句用于创建CUSTOMERS表:
create table customers(
id bigint not null,
name varchar(15) not null,
age int,
primary key(id)
);
创建ORDERS表:
create table orders(
id bigint not null,
order_number varchar(15) not null,
price double precision,
customer_id bigint,
primary key (id),
foreign key(customer_id) references customers(id)
);
上在创建数据库Schema中,通常所有白哦的DDL语句都放在同一个SQL脚本文件中,
必须按照先父表后子表顺序定义DDL语句。假如表之间的参照关系发生变化,就必须修改DDL语句的顺序。这就增加的维护SQL脚本文将的难度。为了解决这一问题,可以采用另外一种方式来定义外键。
create table orders(
id bigint not null,
order_number varchar(15) not null,
price double precision,
customer_id bigint,
primary key (id)
);
alter table orders add constraint FK_CUSTOMER foreign key (customer_id) references customers(id);
上面的这种方式可以使得主表与子表的创建可以不分先后顺序。
为了提高主表与子表的连接查询性能,可以为ORDERS表的CUSTOMER_ID属性建立索引,
alter table orders add index idx_customer (customer_id),
add constraint FK_CUSTOMER foreign key (customer_id) references customers(id);
此外,还可以为ORDERS表设置级联更新或级联删除选项。
alter table orders add index idx_customer (customer_id),
add constraint FK_CUSTOMER foreign key (customer_id) references customers(id) on delete cascade;
Tips:级联更新一般不用,是指你更新的customers表中的id字段,再orders中的customer_id字段也会相应同步更新。但是在一个好的系统中,数据库的主键是不应该改变的。Hibernate实现级联删除功能并不依赖底层数据库的级联删除功能,可见如果在映射文件中设置了级联删除的,不管数据库的ORDERS表有没有设置级联删除,Hibernate都会保证删除的Customer对象时,同时删除关联的所有Order对象。
对于Hibernate应用,提倡由Hibernate来负责各种级联操作,应避免由底层数据库进行自动级联更新或级联删除,因为数据库所作的自动级联操作对Hibernate透明的,这个会导致Hibernate的第一级缓存和第二级缓存中的数据和数据库中的数据不一致。在定义表的外键时,应避免使用”on delete cascade”和”on update cascade”子句。
3:DML数据库操纵语言
DML用于向数据库插入,更新或删除数据,这些操作分别对应insert,update和delete语句。
Insert into customers(ID,NAME,AGE) values(1,’Tom’,21);
4:DQL数据查询语言
SQL语言的核心就是数据查询语言。查询的语法如下:
select 目标列
from 基本表(或视图)
[where 条件表达式]
[group by 列名1[having 条件表达式]]
[orer by 列名2[asc|desc]]
下面demo的数据
create table customers(
id bigint,
name varchar(20),
age int,
primary key(id)
);
create table orders(
id bigint,
order_number varchar(20),
price double,
customer_id bigint,
primary key(id)
);
alter table orders add constraint FK_ORDERS foreign key (customer_id) references customers(id);
insert into customers values(1,'Tom',21);
insert into customers values(2,'Mike',24);
insert into customers values(3,'Jack',30);
insert into customers values(4,'Linda',25);
insert into customers values(5,'Tom',null);
insert into orders values(1,"Tom_Order001",100,1);
insert into orders values(2,"Tom_Order002",200,1);
insert into orders values(3,"Tom_Order003",300,1);
insert into orders values(4,"Mike_Order001",100,2);
insert into orders values(5,"Jack_Order001",200,3);
insert into orders values(6,"Linda_Order001",100,4);
insert into orders values(7,"UnknowOrder",200,null);
表的数据如下图:
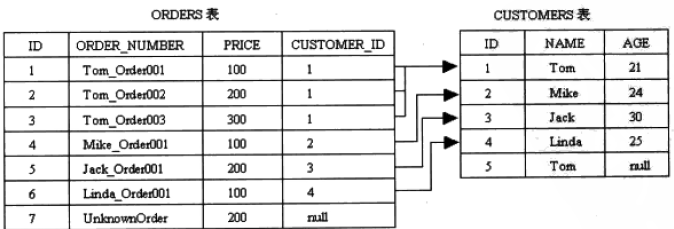
(1):简单查询
查询年龄在18到50之间的客户,查询结果先按照年龄降序排序,在按照名字升序排列。
Ans:select * from customers where age between 18 and 50 order by age desc,name asc;
Tips:between and 是包括18和50的。
(2):查询名字为”Tom”,“Mike”,或者”Jack”的客户:
select * from customers where name in('Tom','mike','jack');
(3):查询姓名的第二个字母是”a”的客户:
select * from customers where name like '_a%';
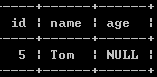
(4):查询年龄为null的客户的名字:
Select name from customers where age is null;
5:连接查询
连接查询的from子句的连接语句格式为:
From TABLE1 join_type TABLE2[on (join_condition)][where (query_condition)];
Join_type表示的连接类型,可以分为3种。
-> 交叉连接(cross join):不带on子句,返回连接表中所有数据行的笛卡尔积。
-> 内连接(inner join):返回连接表中符合连接条件以及查询条件的数据行。
-> 外连接:分为左外连接(left outer join),右外连接(right outer join)。
与内连接不同的是,外连接不仅返回连接表中符合连接条件及查询条件的数据行,
也返回左表(左外连接时)或右表(右外连接时)中仅符合查询条件但不符合连接条件的数据行。
(1):交叉连接查询CUSTOMERS表和ORDERS表:
select * from customers,orders;
CUSTOMERS表中有5行数据,ORDERS表中有7行数据,查询的结果中包含35行数据。
(2):显示内连接(普通连接或者自然连接)查询,使用inner join关键字,在on子句中设定连接条件:
select c.id,o.customer_id,c.name,o.id order_id,order_number from customers c inner join orders o on c.id = o.customer_id;
图:
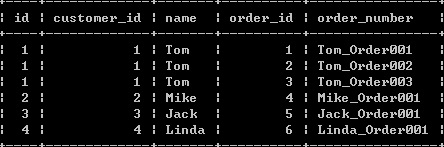
(3):隐式内连接查询,不包含inner join关键字和on关键字。在where子句中设定连接条件:
select c.id,o.customer_id,c.name,o.id order_id,order_number from customers c ,orders o where o.customer_id = c.id;
(3):左外连接查询,使用left outer join关键字,在on子句中设定连接条件:
select c.id,o.customer_id,c.name,o.id order_id,order_number from customers c left outer join orders o on c.id = o.customer_id;
以上查询语句的查询结果不仅包含符合c.ID=o.CUSTOMER_ID连接条件的数据行,还包含CUSTOMERS左表中的其它数据行:
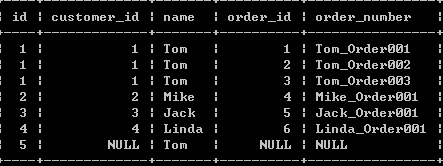
(5):带查询条件的左外连接查询,在where子句中设定查询条件:
select c.id,o.customer_id,c.name,o.id order_id,order_number from customers c inner join orders o on c.id = o.customer_id where o.id > 4 and c.id >2;
以上查询语句对(4)中的结果进一个筛选,仅返回其中符合ORDERS表中的ID大于4并且CUSTOMERS表的ID大于2的数据行:

(6)::右外连接查询,使用right outer join 关键字,在on子句中设定连接条件:
select c.id,o.customer_id,c.name,o.id order_id,order_number from customers c right outer join orders o on c.id = o.customer_id;
以上查询语句的查询结果不仅包含符合c.id = o.customer_id连接条件的数据行,还包含ORDERS右表中的其他数据行:
图:
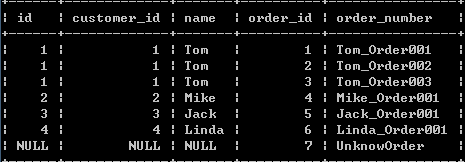
6:子查询
子查询也叫嵌套查询,是指在select子句或者where子句中又嵌入select查询语句。
(1):查询具有3个以上订单的客户:
select * from customers c where 3 <= (select count(*) from orders o where c.id = o.customer_id);
图:
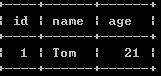
(2):查询名为”Tom”的客户的所有订单
select * from orders o where o.customer_id in(select ID from customers where name = 'tom' );
图:
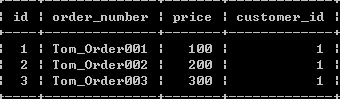
(3):查询没有订单的客户
select * from customers c where 0 = (select count(*) from orders o where o.customer_id = c.id );或者
select * from customers c where not exists (select id from orders o where o.customer_id = c.id);
图:
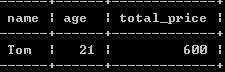
(4):查询ID为1的客户姓名,年龄及他的所有订单的总价格。
select name,age, (select sum(price) from orders where customer_id = 1) total_price from customers where id = 1;
图:
上面的查询也可以通过左外连接查询来完成相同的功能:
select name,age, sum(price) total_price from customers c left outer join orders o on o.customer_id = c.id where c.id = 1 group by c.id;
Tips:如果数据库不支持子查询,可以通过连接查询来完成相同的功能。事实上所有的子查询语句都可以改写成连接查询语句。
7:报表查询
报表查询对数据进行分组统计,其语法格式为:
[select....] from ....[where....] [group by...[having ...]] [order by...]
其中group by子句指定按照那些字段分组,having子句设定分组查询条件。
在报表中可以使用以下的SQL聚集函数(又称为列函数)。
-> count():统计记录条数
-> min():求最小值
->max():求最大值
->sum():求和
->avg():求平均值
下面举例说明报表查询的用法。
(1)按照客户分组,查询每个客户的所有订单的总价格:
select name,age,sum(price) total_price from customers c left outer join orders o on o.customer_id = c.id group by c.id;
图:
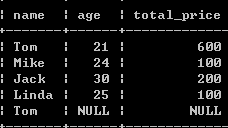
(2):按照用户分组,查询每个客户的所有订单的总价格,并且要求订单的总价格大于100:
select name,age,sum(price) total_price from customers c left outer join orders o on o.customer_id = c.id group by c.id having total_price >100;
以上查询语句对(1)的查询结果进一步筛选,只返回订单的总价格大于100的数据行。
图:
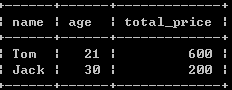
补充:
在mysql中:
修改
ALTER TABLE TableName CHANGE Field_name_tobe_change new_Name VARCHAR (32);
删除
ALTER TABLE TableName DROP Field_name_tobe_delete















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









