







哈夫曼编码简介:
一定能获得最优解的算法。
应用领域:压缩
知识扫盲
1.节点的权(W):赋予叶子节点有意义的值
2.节点的路径长度(L):从根几点到当前节点的边的个数。
3.节点的带权路径长度:W*L
4.一棵二叉树的带权路径长度:所有叶子节点的带权路径长度之和
哈夫曼树(最优二叉树)
一棵二叉树的带权路径长度之和最小。
需求:设有一篇英文文章,出现的字母和对该字母出现的频率如下:
a——–9
b——–3
c——–6
d——–4
将字母存放到二叉树的叶子节点中,使得该二叉树的带权路径之和最小。
算法原理
1.将字母和字母所对应的权值看成一个只有根节点的二叉树。
2.将这些二叉树放到一个数组中形成“森林”。
3.每次在森林中寻找权值最小和权值次小的二叉树,将这两个二叉树看成叶子节点(约定:权值最小的为左子树,权值次小的为右字数),重新创建一个二叉树,该二叉树的双亲的权值为这两个二叉树的权值之和。
4.将创建好的二叉树重新放回“森林”中。
5.重复步骤3动作,直到“森林”中只剩下一棵二叉树。
最优二叉树创建完毕!
图示:
最初的森林:
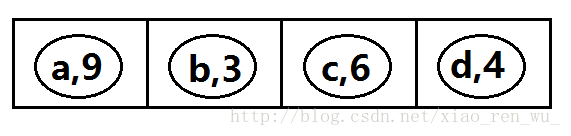
第一次创建二叉树:
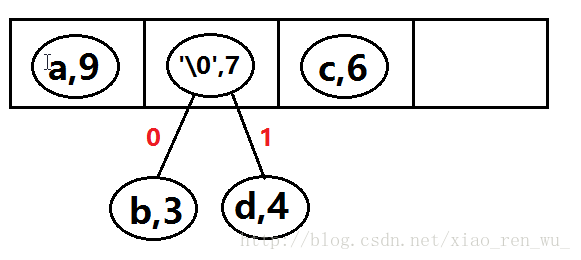
第二次创建二叉树:
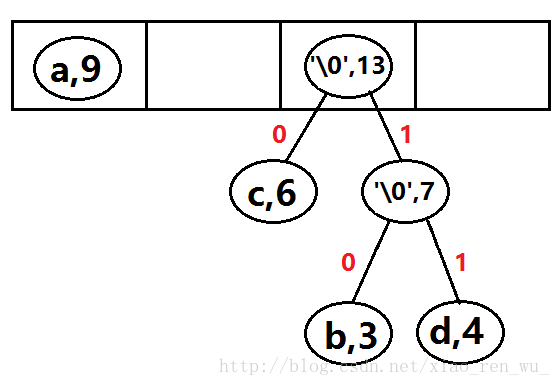
第三次创建二叉树:
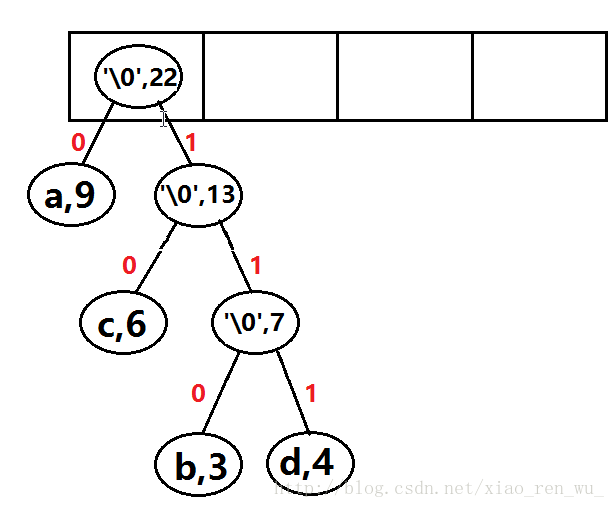
此时,“森林中”只有一个二叉树,该哈夫曼树创建完毕。
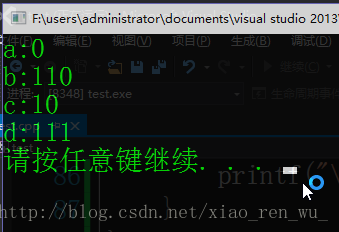
a—–>0
b—–>110
c——>10
d——>111
[注意]并不是所有的哈夫曼树都是像例子这样向一个方向偏,这只是一种巧合。
数组实现:
1.存储:定义一个结构体数组,
每个元素里面包括:
字母————–char word
权值————–int weight
左子树————int left
右子树————int right
双亲————–int parent
编码————–int *code
默认初始化:
left=right=parent=-1,code=null
数组的长度问题:
该数组中不仅存放叶子节点,还应该存放双亲节点,双亲节点的个数为叶子节点的个数减一
所以设叶子节点为n,则双亲节点为n-1,所以该数组的长度为n+n-1=2*n-1个。
将数组中的元素初始化后如图:
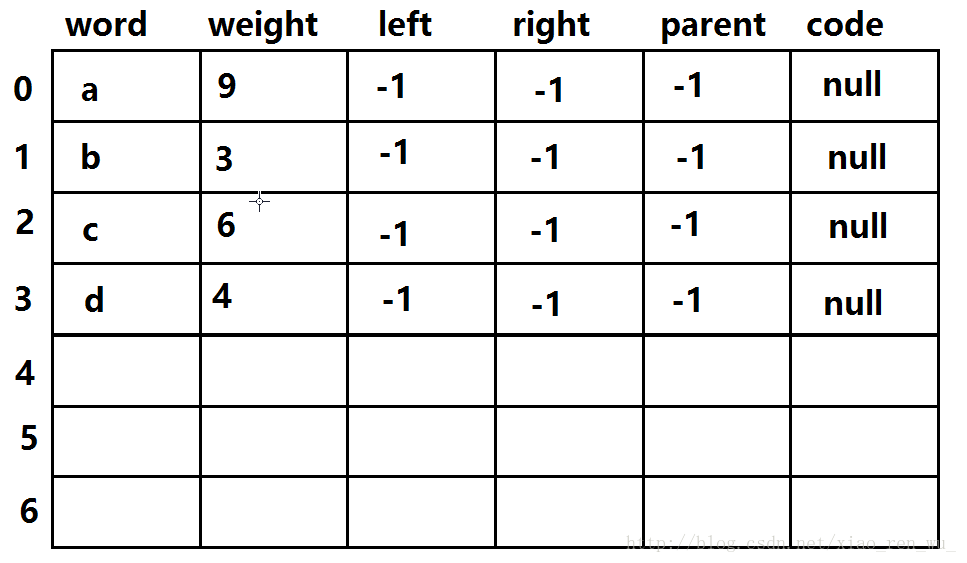
经过一次处理后:
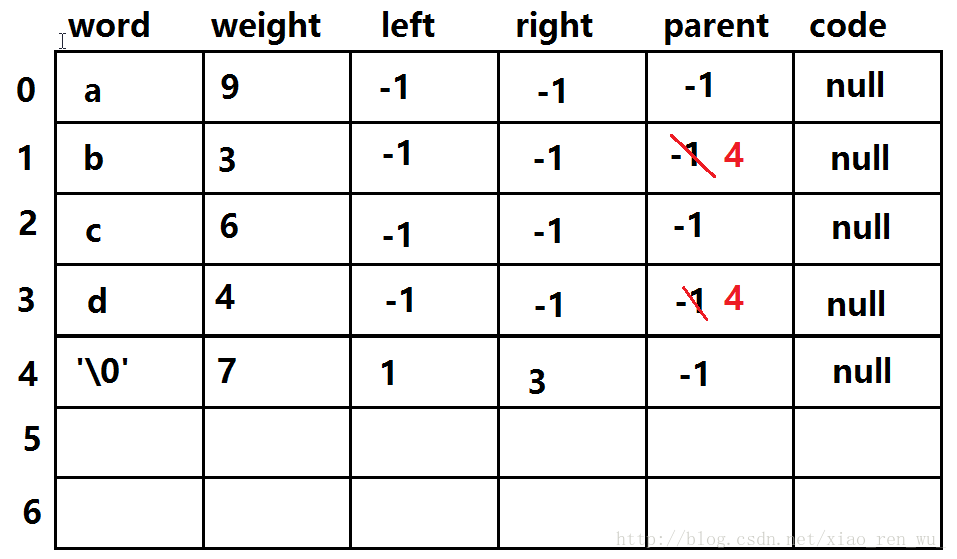
经过一次处理后:
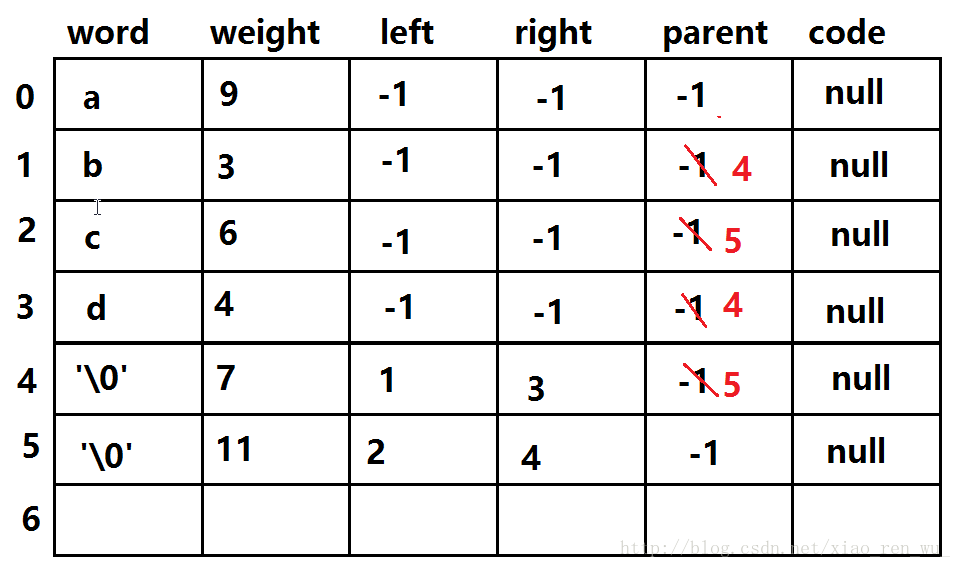
经过一次处理后:
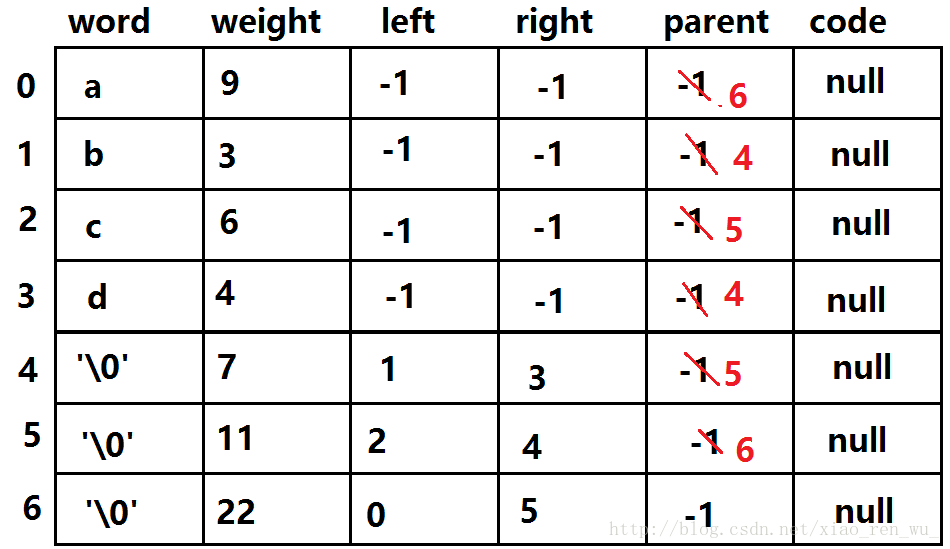
数组中只剩下一个没有双亲的二叉树,哈夫曼树创建完毕。
具体代码实现:
//定义存放信息的结构体
typedef struct {
char word;//用来存储数据
int weight;//用来存储权值
int left, right;//用来存储左右子女
int parent;//用来存储双亲节点
int *code;//用来存储编码
}HuffNode;
//创建哈夫曼树
HuffNode* creatHuffTree(char str[],int weight[]){
int i, k1, k2,n;
n = strlen(str);//记录传入数据的个数
HuffNode *F = (HuffNode*)malloc(sizeof(HuffNode)*(2*n-1));
//初始化二叉树中的叶子节点
for (int i = 0; i < n; i++){
F[i].code = NULL;
F[i].parent=F[i].left = F[i].right = -1;
F[i].word = str[i];
F[i].weight = weight[i];
}
//每次将森林中的二叉树的权值最小和次小的二叉树作为叶子节点,
//重新构成一棵二叉树
for (int loop = 0; loop < n - 1; loop++){
//循环找到森林中第一棵没有双亲的二叉树
for (k1 = 0; k1 < n + loop && (F[k1].parent !=-1); k1++);
//循环找到二叉树中的第二棵没有双亲节点的二叉树
for (k2 = k1 + 1; k2 < n + loop && (F[k2].parent !=-1); k2++);
//找到二叉树中的最小和次小值
for (i = k2; i < n + loop; i++){
if (F[i].parent == -1){//当前二叉树没有双亲
if (F[i].weight < F[k1].weight){
k2 = k1;
k1 = i;
}
else if(F[i].weight<F[k2].weight){
k2 = i;
}
}
}
//将权值最小二叉树和次小二叉树作为叶子节点,重新创建成一棵二叉树
//此时出循环的i所指向的数组空间正好为空,所以将双亲节点放到这个位置
F[i].word = '0';//为了比避免冲突,规定双亲节点word值为0
F[i].left = k1;//规定权值最小的二叉树为双亲的左子女
F[i].right = k2;//规定权值次小的二叉树为双亲的有子女
F[i].parent = -1;
F[k1].parent = F[k2].parent = i;
F[i].code = NULL;
F[i].weight = F[k1].weight + F[k2].weight;
}
return F;
}哈夫曼编码
实现原理:从第一个叶子节点开始,找到双亲节点所在数组的下标,根据双亲节点中的left和right域判断是左子女还是右子女,左子女在code所指向的数组中加入0,右子女加入1,然后该双亲节点作为子女,重复上面的动作,直到找到根节点为止。然后开始编码第二个叶子节点,以此类推,直到编码完毕。
代码实现过程:
//huffman编码
void creatHuffmanCode(HuffNode *F,int n){
for (int i = 0; i < n; i++){
int *p = F[i].code = (int*)malloc(sizeof(int)*n);//用来存储huffman编码的数组
//第一个元素用来记录huffman编码的长度
p[0] = 0;
int c= i,pa;
while (F[c].parent != -1){
pa = F[c].parent;
if (F[pa].left == c){
p[++p[0]] = 0;//规定左子女为0
}
else{
p[++p[0]] = 1;//规定右子女为1
}
c = pa;
}
}
}
//输出huffman编码
void printHuffmanCode(HuffNode F[], int n){
for (int i = 0; i < n; i++){
printf("%c:",F[i].word);
for (int j = F[i].code[0]; j >0; j--){
printf("%d",F[i].code[j]);
}
printf("\n");
}
}【注意】存到code数组中的编码是反的,输出时倒着输出即可。
主函数:
int main(void){
int weight[8] = { 9, 3,6,4};
char word[9] = "abcd";
HuffNode*F=creatHuffTree(word, weight);
int len = strlen(word);
creatHuffmanCode(F,len);
printHuffmanCode(F, len);
system("pause");
return 0;
}测试结果:














 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









