







Spring_09_IOC容器的刷新过程_06
在上一篇文章中我们完成了IOC容器刷新的第三个步骤的说明,这篇文章我们开始IOC容器刷新的下一步骤的讲解,由于第四个步骤本身没有实现,所以下文中我们大概说一下这个空实现能做什么事,就可以了,本篇文章的重点是第五的方法:执行Bean工厂的所有的后置处理器。
那么我们就来看一下IOC容器刷新的第四个方法能做什么事情:
// Allows post-processing of the bean factory in context subclasses.
//留给子类去实现的模版方法,允许子类继续对这个Bean工厂执行一些处理
//什么处理?在标准初始化之后修改应用程序上下文的内部Bean工厂。所有Bean定义信息都将被加载,但是尚未实力化任何Bean,此操作允许在某些ApplicationContext实现中注册特殊的BeanPostProcessor等操作。
postProcessBeanFactory(beanFactory);
示例:
org.springframework.web.context.support.AbstractRefreshableWebApplicationContext类中实现了该方法,该方法中注册进来了一个BeanPostProcessor(Bean的后置处理器ServletContextAwareProcessor),并且设置了忽略依赖接口,其实我们不仅仅可以在这个父类留下来的模版方法中注册进一个Bean的后置处理器,我们能干的事情还有很多,我们可以看一下此时的断点中的beanfactory:
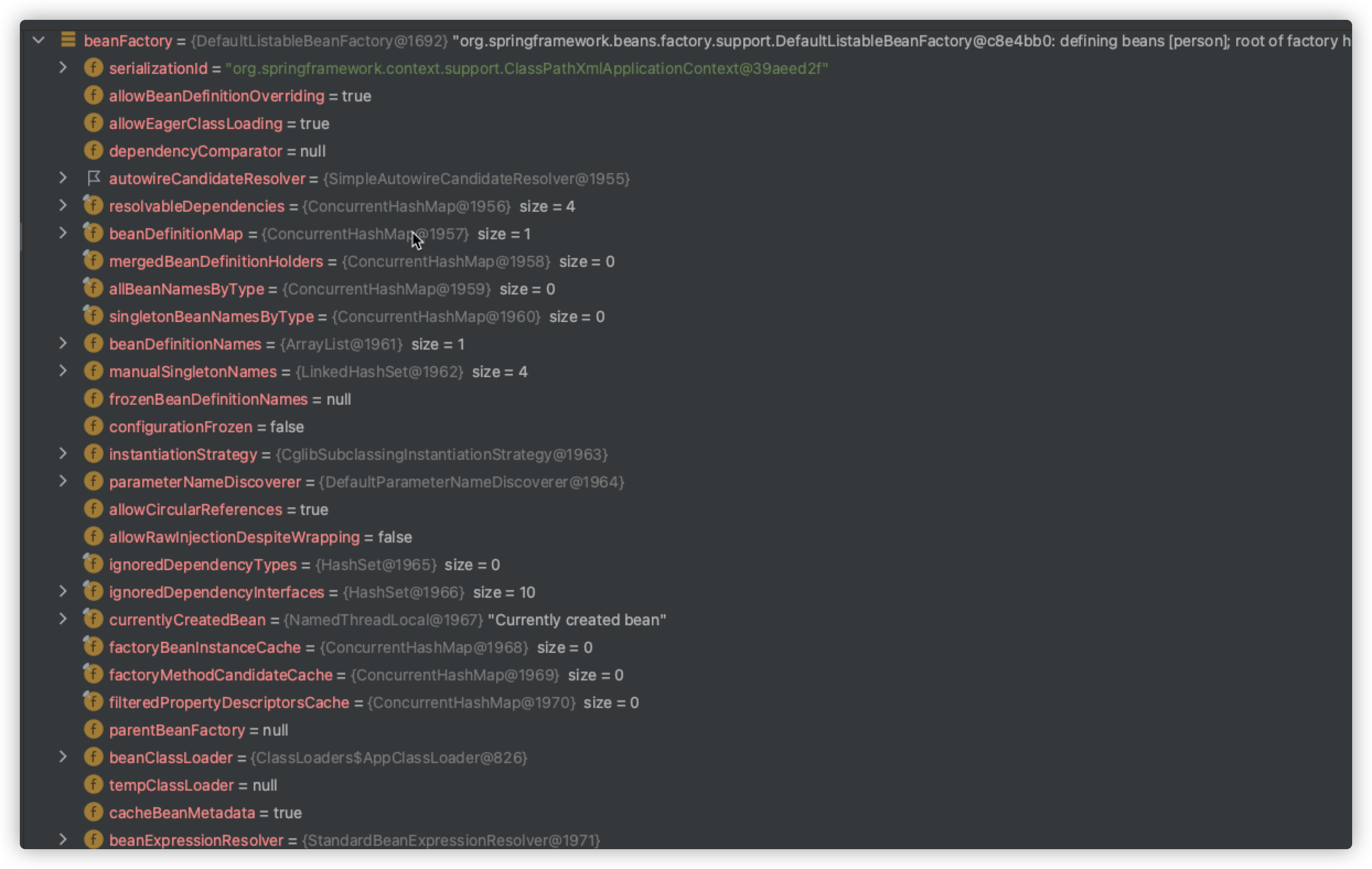
这里面的属性我们大部分都是可以进行操作的,比如设置几个需要忽略的类型,根据bean的名称获取Bean的定义信息等等。大部分的应用场景还是在此处进行添加Bean后置处理器的操作并且设置好相关的要忽略的这类Bean后置处理器子接口的自动装配。
接下来进入我们今天的主题:执行Bean工厂的所有的后置处理器,利用Beanfactory的后置增强器对Bean工厂进行修改或者增强,此时需要注意,如果我们现在使用的不是xml方式启动Spring,而是使用配置类的方式进行启动,那么我们的配置类的解析步骤也会在这一步进行。这个流程我们后续再来进行探讨,我们现在重点是xml形式的Spring的启动,现在是给大家的一个剧透。
下面我们进入这个断点,大家可以看到代码并不是很多:
1、调用了一个类的静态方法。
2、有一个if条件判断,如果判断等于true,则向Bean工厂中添加一个Bean的后置处理器和一个临时的用来于以类型匹配为目的的临时类加载器
但是此时我们最需要关注的一个重点就是里面的第一个步骤,并且重点关注一下这个类:PostProcessorRegistrationDelegate,翻译过来就是后置处理器的注册代理,也就是说执行bean工厂的所有后置处理器的流程都交给这个类来完成,并且这个类不仅可以执行Bean工厂的所有的后置增强器:
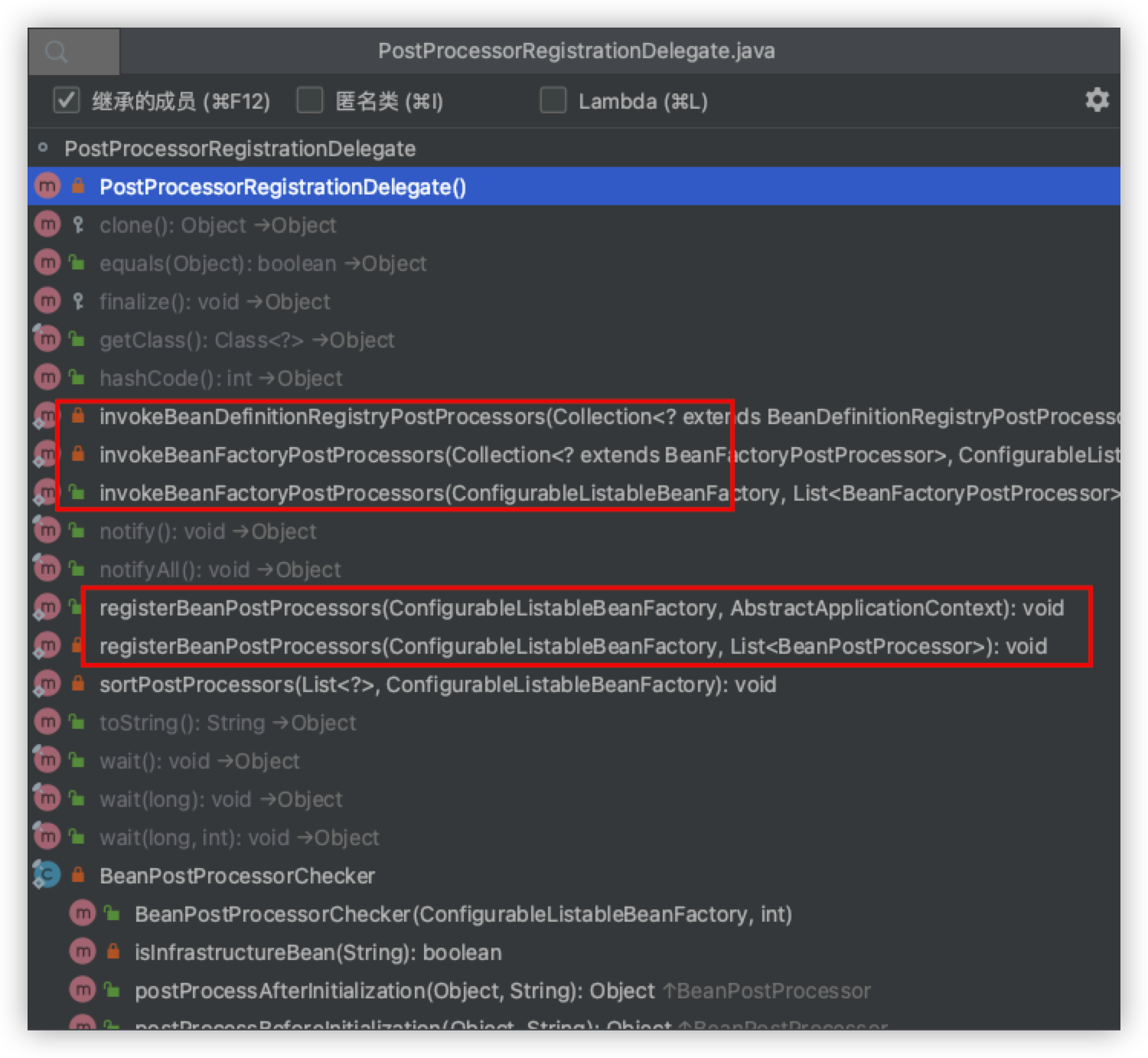
它还可以执行bean定义信息注册器的后置处理方法,但是此时我们要知道这个Bean定义信息注册中心的后置增强接口也是继承了Bean工厂后置处理器的。它也可以注册bean的一些后置处理器等等具体功能我们随着Spring的整个IOC容器的刷新过程慢慢探索。
接下来我们来进入这个方法,可以看见该方法中传递了两个参数,一个是当前的bean工厂对象,一个是当前bean工厂后置处理器的list集合。
细节:我们可以看到这个bean工厂后置处理器集合是从哪里获取到的,是从当前的AbstractApplicationContext类中获取到的,我们当前bean工厂对象(DefaultListableBeanFactory对象)中并没有存储所有bean工厂的后置处理器,所以如果我们想要手动添加一些bean工厂的后置处理器的话,那我们一定是可以在我们的MainTest中的ClassPathXmlApplicationContext这个对象引用中去add进行添加的,大家不妨试一下。
点进来这个方法之后我们可以看见该方法体中大概100多行的代码,不要懵逼,让我们一起一点点的探索。
在探索之前我们先搞明白一件事情,刚才我们提到可以在我们的MainTest中手动向容器中添加Bean工厂的后置处理器,这是一种添加方式,那么还有没有别向容器中的添加Bean工厂的后置处理器的方式呢?就是我们的xml形式的配置文件。
接下来我们就手动写几个BeanFactoryPostProcessor来体验一下整个执行的流程。我们写六个它的实现。
两个实现PriorityOrdered接口
两个实现Ordered接口
两个不实现任何接口
各自以不同的方式添加进去
现在可以看见我们已经写好了这6个BeanFactoryPostProcessor的实现,并且也实现了相应的接口。
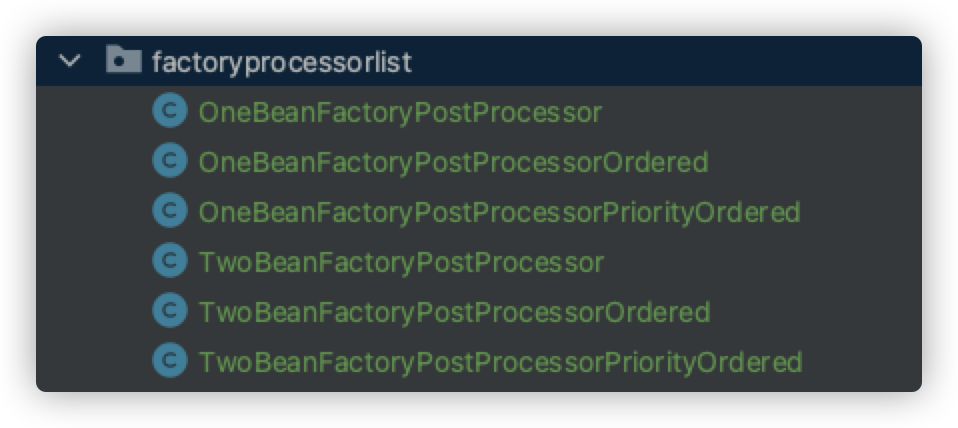
其中实现了什么样的接口这里就用了什么样的后缀来进行标识。
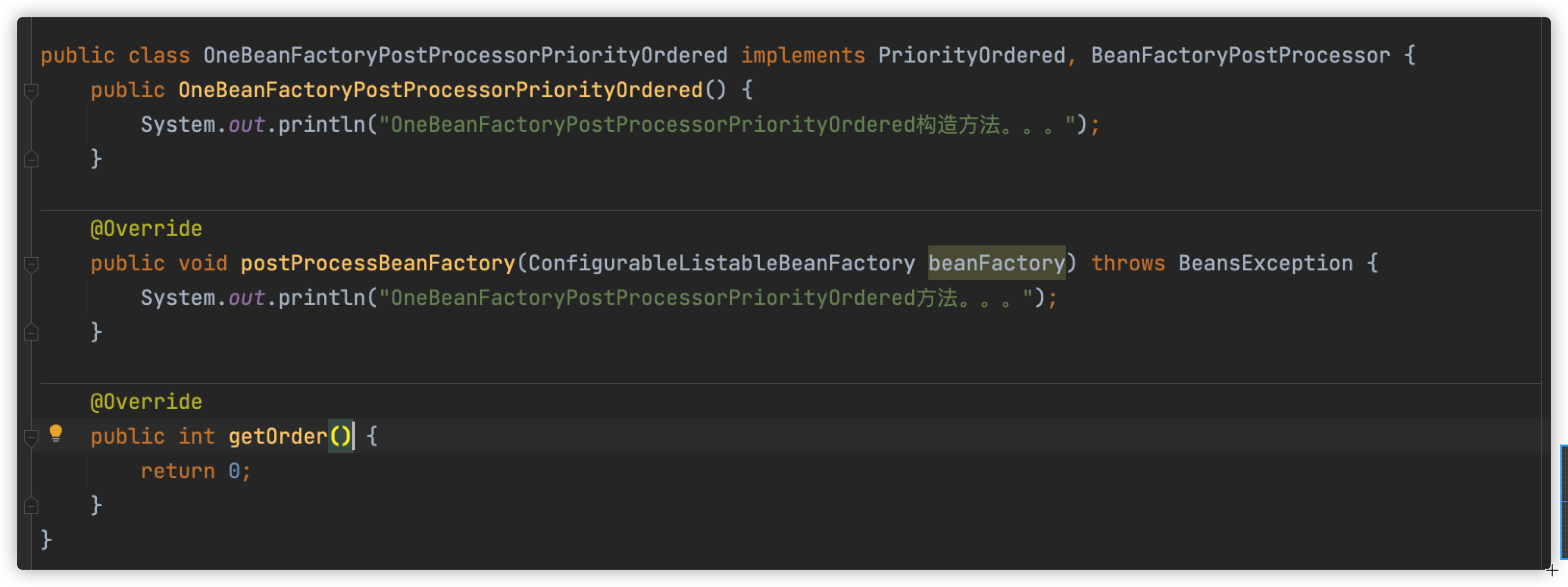
下面我们将我们实现了BeanFactoryPostProcessor接口以及排序接口的实现类添加到容器中。

我们现在将另外三个的实现添加到AbstractApplicationContext的bean工厂的后缀处理器集合中:

此时大家思考一个问题:我们现在在下面添加的这些bean工厂的后置处理器,在我们此时的执行所有bean工厂的后置处理器的getBeanFactoryPostProcessors()方法中是否可以被get到?
答案是很明显不可以的!
那么如果我们想让它在getBeanFactoryPostProcessors()能获取到,我们应该怎么办?

我们可以在方法的下面手动的调用refresh()方法,手动的刷新一下容器。这是一种方法。
其他的实践方案:
例如在springboot初始化时,ConfigurationWarningsApplicationContextInitializer类的initialize方法中就有调用:
@Override
public void initialize(ConfigurableApplicationContext context) {
context.addBeanFactoryPostProcessor(
new ConfigurationWarningsPostProcessor(getChecks()));
}
我们再来重新启动一下我们的Spring程序,走到该方法体中,此时我们的第二个参数(bean工厂的所有后置处理器集合)的大小仍然是0,什么都没有。
接下来看到的一大堆注释,一上来就可以看到这个WARNING,这段注释是在21年的1月份补充进该方法体中的,大概的意思就是说:下面方法体中的这些代码,看着重构起来是很容易的,以避免使用多个循环和多个List集合,但是使用这些循环和List集合是官方故意为之的,因为要遵守我们前面提到了两个Order接口的顺序,而且不得导致这些后置处理器以getBean()的方式被调用,或者以错误的顺序被注册在ApplicationContext中。并且还给我们贴了一个链接,链接里面全都是被拒绝的pr请求,意思就是他们犯过的错误我们就不要在犯了。有兴趣的可以粘贴这个链接,我们接着向下说。
在正式进去方法体之前我们先把下面一大堆的代码想要表达什么意思给大家提前说好,省的我们阅读起来没有头绪。
总体的方向就是:
如果存在Bean定义信息注册器的后置处理器,那么我们先来执行这个后置处理器,为什么?我在上面已经说过一次,我们的Bean定义信息注册器的后置处理器接口(BeanDefinitionRegistryPostProcessor)就是bean工厂后置处理器接口(BeanFactoryPostProcessor)的一个子接口,在Spring中首先是进行Bean定义信息注册器的后置处理器的判断逻辑的。
如果存在BeanDefinitionRegistryPostProcessor接口的实现,那么分为三类分别调用它们实现了接口中的方法postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry),分为哪三类?
1、实现了PriorityOrdered接口的所有的Bean定义信息注册器的后置处理器
2、实现了Ordered接口的所有的Bean定义信息注册器的后置处理器
3、什么排序接口都没有实现的所有的Bean定义信息注册器的后置处理器
接下来在对已经归好类的这些接口进行一个排序,排序针对的是实现了两个排序接口来说的,进行完排序之后,一个一个的去执行调用。
接着清空一下我们刚刚创建的List集合。
执行完所有的BeanDefinitionRegistryPostProcessor接口实现的后置处理bean定义信息注册方法后,开始执行实现BeanFactoryPostProcessor接口的方法之前,还有一件事要做!我们再次强调谁是谁的子接口,那么如果我的Bean定义信息注册器的后置处理方法又@Override了父接口的方法呢?当然我们还是要继续在当前流程的最后来回调一下BeanFactorPostProcessor接口的方法实现。
以上的操作都做完之后,就是执行实现BeanFactorPostProcessor接口的步骤,这个执行步骤就和上面的那些步骤是一样的了。这也就再次印证了我们在进入方法体的时候看见的那一个明显的WARNING了,就是把上面做的事情在下面又做了一遍,只不过是不同接口的实现。
说到这里的时候其实该方法大概也就都说完了,下面我们简单的看一下方法体里面的代码实现。
invokeBeanFactoryPostProcessors方法解析:
首先创建一个Set集合,里面存放的是所有的后置处理Bean的名称,包括Bean定义信息注册器的后置处理器的BeanName和Bean工厂后置处理器的BeanName。
接下来就是走一个If判断,判断我们当前的bean工厂是不是属于BeanDefinitionRegistry接口类型的,如果是属于这个类型的,那么我们才能应用这些后置处理器,否则没意义,我们贴一下这个bean工厂的所有父类的类图吧,感觉这样会更清晰一些。

Tips:
从图中我们可以看见实线表示的是extends,虚线表示的是implements,这是UML类图中的知识点
那么毋庸置疑我们此时的beanFactory肯定是属于BeanDefinitionRegistry接口类型的,接下来将beanFactory强转为BeanDefinitionRegistry,下面又创建了两个集合。
一个是regularPostProcessors表示的是常规的后置处理器集合,另一个是registryProcessors表示的是Bean定义信息注册器的后置处理器。
接着是一个For循环,被遍历的是我们作为参数传递过来的所有bean工厂的后置处理器的List集合,当然此时这个List集合是一个空的。但是我们还是先分析一下,如果不为空的时候是怎么样的一个情况。
如果不为空的情况下:
拿到每一个遍历得到的Item,判断当前的后置处理器是不是属于BeanDefinitionRegistryPostProcessor类型的
如果是这个类型的,将该后置处理器强制转为BeanDefinitionRegistryPostProcessor,然后执行这个接口中的方法(postProcessBeanDefinitionRegistry(); ),并且将我们上一步的被转换为BeanDefinitionRegistry的bean工厂对象传递进去。此时就已经开始进行了回调,回调完毕后将我们的这个BeanDefinitionRegistryPostProcessor添加到Bean定义信息注册器的后置处理器这个集合中,此步骤会反复执行,直到遍历完当前的这个集合。
如果不是这个类型的,那么将当前遍历得到的Item添加到**常规的后置处理器集合(范性为BeanFactoryPostProcessor)**中。
**如果为空的情况下:**什么也不做。
接下来断点继续向下执行,我们看到又创建了一个List集合,里面的范性是BeanDefinitionRegistryPostProcessor接口类型的,我们看这个对象变量的定义:currentRegistryProcessors,大概的意思就是当前正在使用到的哪些Bean定义信息的后置处理器的集合。
但是上面还有一些注释,我们大概的翻译一下:
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
不要在这里初始化那些工厂Bean,我们需要保留所有的常规的bean,在未初始化的状态下让bean工厂的后置处理器去对它们进行处理。
将实现了PriorityOrdered、Ordered 和其余部分的 BeanDefinitionRegistryPostProcessor进行区分开。
断点在往下的流程就是我们在进入方法体之前说的流程了。并且这部分的Bean定义信息注册器的后置处理器是来自我们的配置文件的。
我们看这个方法的名称:getBeanNamesForType(),根据类型来获取所有bean的名称,我们将我们需要的类型传递进去,就会给我们返回来所有的bean的名称的一个String类型的数组,至于为什么会返回来数组,就不解释了。
不知道大家有没有注意一点,我刚刚为什么提到要看这个方法的名称,并且刚刚在断点上面的那三个集合我都特意的解释了三个对象的变量名称。
因为在Spring里面包括它的类的命名,方法的命名,大部分都是看见了名字就能大概的知道这个类或者这个方法是干什么的/这个方法能为我们做些什么事情。
方法我们容易理解,传递参数和获取返回值的事儿,方法单独存在的时候我们也可以明白。但是如果单拿出来一个类来说明的话,不是一件容易的事情,因为我们要捋清楚这个类在哪个流程的哪个环节起到了什么样的作用,并且类与类之间的各种复杂关系掺杂了各种的设计模式与各种设计原则。当然在我们的断点进行中,是可以不用管类之间的关系的,走的是流程。
但是到这儿,不知道大家会不会有疑问,就是单单返回给我们的只有当前我们传递进去的接口类型吗?如果这个接口有子接口,那么会全部给我们返回来吗?答案是可以的,会返回来的。答案在哪里?
看ListableBeanFactory这个接口里面的该方法的注释即可。
我们看这个方法的@return注释:返回与给定对象类型(包括子类)匹配的bean(或者是由工厂创建出来的bean对象)的名称,如果没有的话,那么返回的是一个空数组。
这个方法是很重要的,我决定在IOC容器都梳理完毕之后单独拿出来一篇文章来讲解这个方法。
现在为了不影响我们的主线,我们放过这个断点,直接看它的返回值。
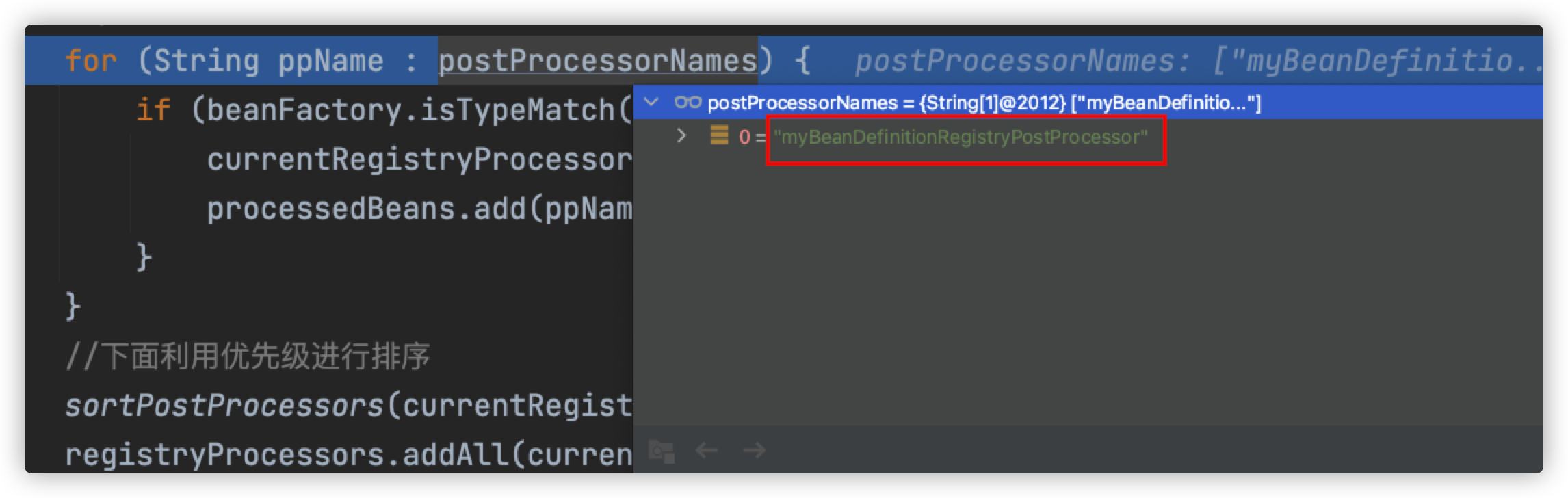
这里我们拿到了我们自己在配置文件beans.xml定义的bean名称。
接下来一个for循环,遍历刚刚拿到的所有属于指定类型的后置处理器名字数组。
根据bean的名称判断当前拿到的bean是不是属于PriorityOrdered接口类型的。如果是实现了PriorityOrdered接口,那么将该beanName对应的对象进行实例化(实例化是通过getBean();这个方法进行的,在IOC容器刷新的后续步骤中是我们的重点),并且添加到currentRegistryProcessors集合中,然后添加到我们进入方法体时创建的Set集合中,显然我们在配置文件添加的自己定义的后置处理器并没有实现该优先级接口。那么我们继续向下走。
下面对实现了排序接口PriorityOrdered的所有后置处理器进行一个排序,想要看见方法体究竟做了什么事,那么我们还要在配置文件中再添加一个定义信息注册器的后置处理器,并且还要实现该排序接口。因为如果我们传递的元素只有一个的话,是不会看见效果的,只有一个元素的话直接return了。
接下来,我们再写一个BeanDefinitionRegistryPostProcessor的实现类,并且将这两个实现类都实现排序接口PriorityOrdered,添加到配置文件beans.xml文件中,我们将断点来到sortPostProcessors();这个方法中。此时集合中就是我们刚刚创建好的两个Bean定义信息注册器后置处理器对象,另外也将bean工厂对象传递了进来。我们来看一下这个方法体中都做了什么事。那么我们为什么要分析这个接口呢?因为下面也有很多的for和if的循环与判断,我们理解了一个,下面的那些自然也就一看就懂了。
private static void sortPostProcessors(List<?> postProcessors, ConfigurableListableBeanFactory beanFactory) {
// Nothing to sort?
if (postProcessors.size() <= 1) {
return;
}
Comparator<Object> comparatorToUse = null;
if (beanFactory instanceof DefaultListableBeanFactory) {
comparatorToUse = ((DefaultListableBeanFactory) beanFactory).getDependencyComparator();
}
if (comparatorToUse == null) {
comparatorToUse = OrderComparator.INSTANCE;
}
postProcessors.sort(comparatorToUse);
}
其实点进来方法体中就明白了为什么这个集合的size为什么必须大于1了。如果size小于等于1,那么该方法就直接return;跳出这个方法了。但是此时我们的集合长度大小为2。
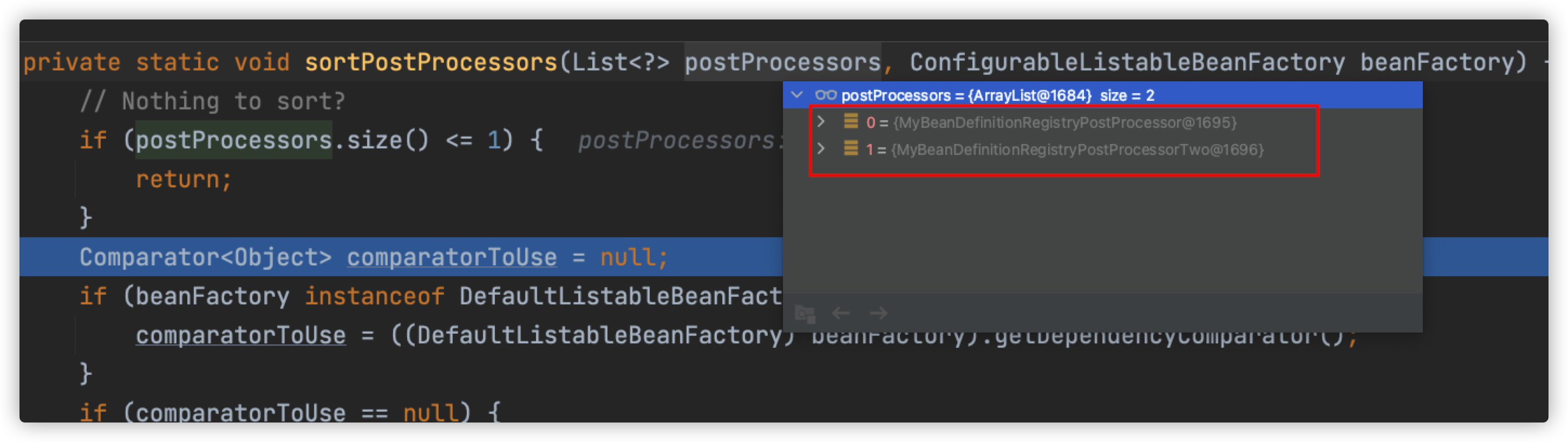
接下来再一次的判断我们当前传递进来的bean工厂是不是属于DefaultListableBeanFactory类型的,如果是的话,那么从DefaultListableBeanFactory对象中获取以来的比较器,如果拿不到的话(在我们的断点执行过程中拿到的是null),那么就使用可共享的顺序比较器(该比较器是单例对象并且是饿汉式的)。
将我们的比较器传递进集合中的sort排序方法中。我们断点继续向下执行,来到了OrderComparator类中的compare();这个方法中又调用了doCompare();。又在doCompare();方法中再一次的校验两个对象是否都实现了排序接口PriorityOrdered。
如果参加比较的两个元素中:
1、第一个元素实现了排序接口,第二个元素没有实现排序接口,那么返回的是-1,升序。
2、第二个元素实现了排序接口,第一个元素没有实现排序接口,那么返回的是1,降序。
可以看见如果真的是这种情况的话,仍然是我们实现了排序接口的后置处理器在数组的前面。
接下来如果两个元素都实现了排序接口的话,就拿到它们自己重写了getOrder()方法的返回值。将他们两个的返回值进行一个排序,排序使用的是Integer.compare(i1, i2);方法。如果该方法返回的是小于0的话,那么该集合的顺序就是升序的,如果返回的是大于0的话,那么该集合的顺序就是降序的。如果返回的等于0的话,那么他们两个的顺序就是一样的。
自此,我们的排序方法就分析完毕。
我们的断点继续向下走。
将我们已经排好序的bean定义信息注册器后置处理器集合添加到我们之前创建好的registryProcessors集合中(在上面有解释)。
接下来的方法我们看见方法名字就知道要做什么事儿:执行所有的Bean定义信息注册器后置处理器的回调方法。传递进去的参数有:
1、我们刚刚按照getOrder();排好序的集合。
2、Bean定义信息注册器(其实现在来看的话就是当前的bean工厂对象)
3、当前应用程序的启动指标:DefaultApplicationStartup对象
由于方法体中的代码不算太多,我们直接将它们贴在下面:
/**
* Invoke the given BeanDefinitionRegistryPostProcessor beans.
*/
private static void invokeBeanDefinitionRegistryPostProcessors(
Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry, ApplicationStartup applicationStartup) {
for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) {
StartupStep postProcessBeanDefRegistry = applicationStartup.start("spring.context.beandef-registry.post-process")
.tag("postProcessor", postProcessor::toString);
//核心:配置类的后置处理器会在此解析配置类
postProcessor.postProcessBeanDefinitionRegistry(registry);
postProcessBeanDefRegistry.end();
}
}
大家看到其实代码很简单,只不过是拿到了所有我们传递进来的实现了排序接口的Bean定义信息注册器的后置处理器,并挨个的进行方法的执行,并且在每个后置处理器的执行前后都有一个标识,表示着该方法的开始回调以及方法执行完毕之后的一个end()标识,因为就算end()方法我们点进去以后发现也是一个空的方法体。此时我们的invoke方法执行完毕。
我们的断点继续向下执行,将我们刚刚放在currentRegistryProcessors集合中的那两个实现了排序接口PriorityOrdered的元素移除出去,或者说直接将当前集合清空,那么为什么清空呢?是为了该集合的复用性,因为接下来按照我们一开始讲述的流程来说,此时我们应该做的事就是该拿到那些实现了Ordered接口的Bean定义信息注册器的后置增强器们了,我们知道此时我们的定义信息集合中是一定没有实现了Ordered接口的BeanDefinitionRegistryPostProcessor,但是此时我们先不着急修改我们现在的代码,我们先继续向下看。
还是一样的套路,先获取所有的,接下来遍历,但是在if中多了一个判断:!processedBeans.contains(ppName)判断当前processedBeans集合中是否已经含有当前bean的名字,如果有的话那么就不执行后面的代码逻辑,跳过本次循环,大家应该也知道这样做的目的是为什么,不解释了,再接下来的代码逻辑就是和上面我们分析的一样了。简单说:
将符合条件(就是实现了Ordered接口)的BeanDefinitionRegistryPostProcessor添加到刚刚置为空的集合中,将我们当前遍历得到的beanName添加到一进入方法体中就创建好了的Set集合中(刚才我们还用这个集合来进行contains判断了)。再接下来就是进行排序、将排序好的后置处理器添加进registryProcessors集合中,执行方法的回调、使用完currentRegistryProcessors集合之后再一次的将该集合置为空。此时实现了Ordered接口的BeanDefinitionRegistryPostProcessor对象也已经执行完毕。再接下来就是执行什么排序接口都没有实现的BeanDefinitionRegistryPostProcessor了。
现在我们将代码还原,将已经实现了排序接口的两个后置处理器进行一个还原,让它们仅实现BeanDefinitionRegistryPostProcessor接口。
现在我们的断点应该在
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
这行注释的下面,也就是boolean reiterate = true;这一行。
我们先来看这行注释是什么意思,其实不用看就能知道,我们在前面已经将实现了排序接口的所有Bean定义信息注册器的后置处理器的回调方法都执行完了,现在剩下的就只有未实现任何排序接口的后置处理器了。
由于代码不算多,我们贴在下面:
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
currentRegistryProcessors.clear();
}
执行流程:
进入方法体就将循环的标志设置为false,下面的代码大家肯定更是熟悉,拿到所有的后置处理器(其中还是包含所有的后置处理器),接下来挨个的进行遍历。在if里面校验当前的beanName是不是在该集合中存在(此时我们之前执行过回调方法的所有beanName都已经放在了这个Set集合中),如果不在这个集合中存在,那么将这个后置处理器对象添加到当前正在使用的后置处理器集合(currentRegistryProcessors)中,将该bean的beanName添加到Set集合(processedBeans)中。将循环的标记变为true。
直到遍历结束,我们对这个集合再一次的进行排序,现在我们什么排序接口都没有实现,我们是根据什么来对元素进行排序的呢?
我们在追溯源码的对底层发现返回来的Order是一Integer的最大值,那么自然这两个我们手动添加的类他们的顺序都是一样的,所以他们的顺序是不区分先后的。
代码的位置大概在:
将我们排序好的后置处理器添加到Bean定义信息注册器的后置处理器集合中(registryProcessors),再接下来就是原来的执行流程,执行完毕之后再一次的清空当前正在使用的Bean定义信息注册器的后置处理器集合(currentRegistryProcessors),此时我们的循环标记是true,意味着我们的while循环还没有结束,下面再一次的走到循环体中,直到在if标签中判断当前被遍历到的beanName发现已经存在于processedBeans集合中了,跳过本次循环。但是我们下面这四行代码还是会执行一遍:
//1、sortPostProcessors(currentRegistryProcessors, beanFactory);
//2、registryProcessors.addAll(currentRegistryProcessors);
//3、invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());
//4、currentRegistryProcessors.clear();
但是此时的循环标记已经是false了,接下来再一次走到while判断中为false,自此未实现任何排序接口的所有的BeanDefinitionRegistryPostProcessor接口里面的方法已经执行完毕了。但是不要忘记我们现在的这个接口还继承了BeanFactoryPostProcessor这个后置处理器接口,此时我们就需要回调既实现了BeanDefinitionRegistryPostProcessor后置处理器又实现了BeanFactoryPostProcessor这个后置处理器而且重写了BeanFactoryPostProcessor这个后置处理器接口里面的方法postProcessBeanFactory。
那么我们的这些后置处理器都在哪里存放着呢?
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();//正常的/常规的 Bean工厂的后置处理器集合
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();//Bean定义信息注册器的后置处理器集合
在这两个集合里面存放。
第一个集合(regularPostProcessors)它的数据来源:我们作为方法的参数传递进来的所有的Bean工厂的后置处理器,并且在一开始遍历的时候判断当前后置处理不属于BeanDefinitionRegistryPostProcessor接口的时候,才会将被遍历的后置处理器添加到此集合。
第二个集合(registryProcessors)的数据来源:在第一次遍作为参数传递进来的时候并且当前后置处理器也是属于BeanDefinitionRegistryPostProcessor接口类型时添加到集合、实现了两个排序接口、不实现任何排序接口的后置处理器的所有的符合条件的Bean工厂后置处理器。
这两个集合已经包含了:1、作为参数传递进来的Bean工厂的后置处理器集合。2、所有实现了BeanDefinitionRegistryPostProcessor接口的bean工厂的后置处理器。
执行方法的代码其实非常简单,与上面执行Bean定义信息注册器后置处理器集合代码逻辑无变化,并且两个集合执行的时一样的代码。将代码贴在下面,不进行解释了:
/**
* Invoke the given BeanFactoryPostProcessor beans.
*/
private static void invokeBeanFactoryPostProcessors(
Collection<? extends BeanFactoryPostProcessor> postProcessors, ConfigurableListableBeanFactory beanFactory) {
for (BeanFactoryPostProcessor postProcessor : postProcessors) {
StartupStep postProcessBeanFactory = beanFactory.getApplicationStartup().start("spring.context.bean-factory.post-process")
.tag("postProcessor", postProcessor::toString);
postProcessor.postProcessBeanFactory(beanFactory);
postProcessBeanFactory.end();
}
}
以上是BeanDefinitionRegistryPostProcessor后置处理器的执行流程,以及既实现了该接口,又实现了BeanFactoryPostProcessor接口,并且重写了BeanFactoryPostProcessor接口的postProcessBeanFactory方法的所有后置处理器的执行逻辑
以下为实现了BeanFactoryPostProcessor后置处理器接口的执行流程。
在根据类型获取实现了BeanFactoryPostProcessor接口的所有的bean的名称之前,我们看到该方法上面有两行注释,意思就是不要在此书进行FactoryBeans的初始化操作,需要保留所有常规的Bean,目的是为了让bean工厂的后置处理器去应用这些还没有初始化的Bean。
接下来创建三个集合:
1、priorityOrderedPostProcessors:这里用来存放所有实现了PriorityOrdered接口的后置处理器
2、orderedPostProcessorNames:这里用来存放所有实现了Ordered接口的后置处理器的bean的名称。
3、nonOrderedPostProcessorNames:这里用来存放所有什么排序接口都没实现的bean的名称。
接下来就是遍历所有我们刚刚获取到的后置处理器的bean的名称集合,在for循环中首先校验的就是当前被遍历出来的名字是否在Set集合中存在,如果存在的话,那么什么也不做,并且下面的注释已经说明:如果当前集合中已经存在该bean的名称,说明在上面的第一阶段中已经处理过该后置处理器了,并且跳过本次循环进入下一次循环。
我们来看不存在的情况,在下面的判断逻辑中,分别将实现了PriorityOrdered、Ordered和什么排序接口都没实现的bean工厂的后置处理器添加到对应的上面我们创建出来的集合中,此时如果整个遍历结束,那么各自集合中就会保存着各自的后置处理器。
接下来的操作我想大家都知道了,我在这里用文字阐述一遍,就不debug进入断点看了。
首先对实现了PriorityOrdered接口的bean工厂后置处理器进行排序,然后回调postProcessBeanFactory方法。其次创建一个List集合,范型为BeanFactoryPostProcessor,并且指定该集合的大小为上面orderedPostProcessorNames集合的size();至于为什么在创建List对象的时候就初始化它的大小,这里不在赘述,相信大家都明白。之后通过getBean();的方式去创建对象,并添加到刚刚创建好的集合中。下面就是对这个集合进行排序,处理回调方法。
最后执行什么接口都没有实现的 BeanFactoryPostProcessor,同样的方式,创建一个集合对象,初始化集合大小为nonOrderedPostProcessorNames的size();长度,通过getBean();的方式进行创建对象,通过invokeBeanFactoryPostProcessors方法来处理回调。
最后的最后调用bean工厂的清除元数据缓存的方法。清除缓存的合并bean定义信息,因为后置处理器可能修改了原始元数据,断点不带大家看了,因为现在还没有用到。
以上就是IOC容器刷新的第五大步骤:执行Bean工厂的所有的后置处理器。至此我们已经全部分析完。














 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









