







回溯算法的理解
回溯算法是什么?
首先我们看官方的说法:
①:回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。
②:回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
③:许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
④:在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)
⑤:若用回溯法求问题的所有解时,要回溯到根,且根结点的所有可行的子树都要已被搜索遍才结束。
⑥:而若使用回溯法求任一个解时,只要搜索到问题的一个解就可以结束。
⑦:除过深度优先搜索,常用的还有广度优先搜索。
从官方的说法上,我们可以看出来,回溯算法其实就是一个对该问题进行解决的所有方法的集合,对于一件事情,我们将所有的方法都列出来,然后将这些方法一一尝试,如果可行,那么将可行的方法记录下来,然后又开始尝试,也就是一个类似枚举的方法,枚举出所有方案,然后使用可行的,但是回溯算法又与枚举优点不同,主要在于回溯算法会及时止损(对于及时止损的方法会在下面详细说到)。
而对于回溯算法,我们先看看深度优先的搜索
深度优先的搜索(DFS)
深度优先的搜索,被常常说为一条路走到黑的搜索。
深度优先的搜索:
首先,我们先看在二叉树中查找一个节点的例子:
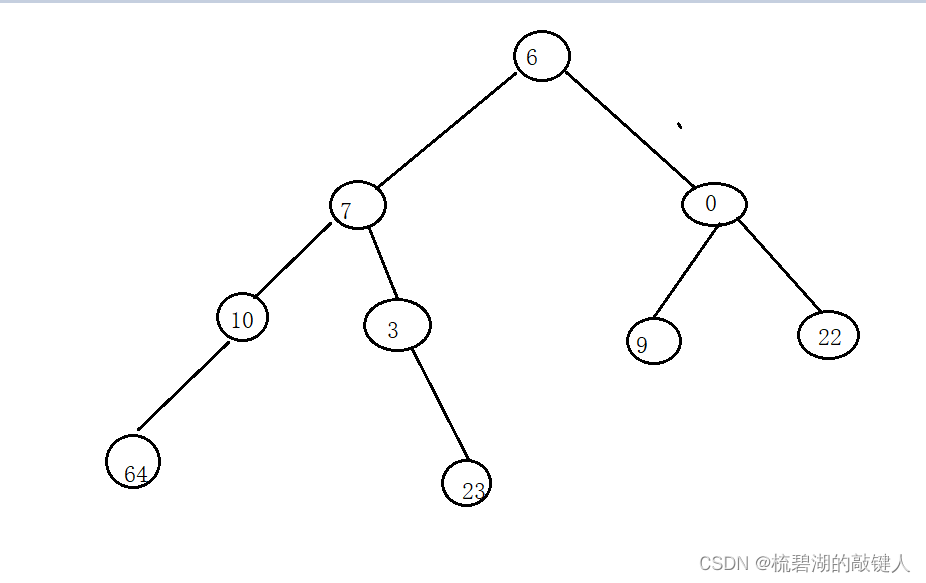
假设有如上的这个二叉树,其中因为这个二叉树没有顺序,如果我们要在里面去查找一个节点,我们就只能从根节点出发,然后往下进行查找,但是我们应该如何操作呢?(假设我们查找的节点是23这个节点)
答:我们可以进行递归调用,从根节点出发,去递归调用其子节点,然后进行查找,当找到的某个节点的子节点的值就是我们要查找的值时,返回其子节点。
所以,对于其上例中的查找23这个节点,我们查找路线应该是这样的:
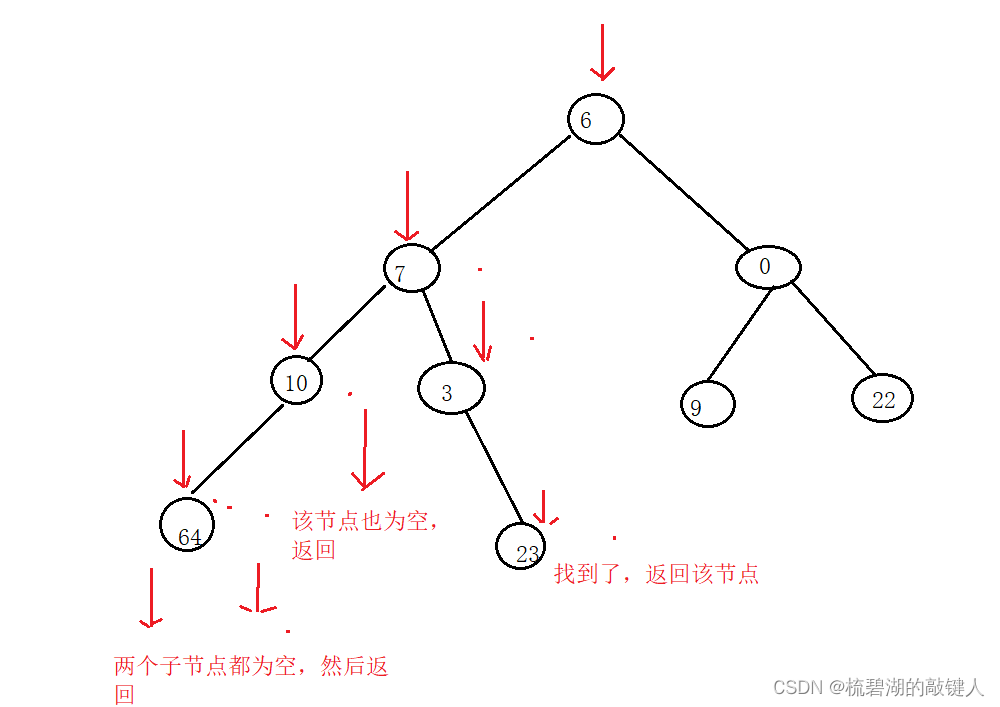
他会依次遍历它的左右孩子,然后遍历到最后一个节点,如果找到了,最后返回的就是找到的节点,如果没找到,最后返回的就是空,代码如下:
//假设TreeNode就是二叉树的节点结构体,而root就是二叉树的根节点
TreeNode* FindNode(TreeNode* root,int val)
{
if(root == nullptr || root->val == val) //找到节点,或者遍历到空节点
{
return root;
}
else
{
TreeNode* node = FindNode(root->left,val); //先遍历左节点,然后遍历右节点
if(node == nullptr)
{
node = FindNode(root->right,val);
}
return node;
}
}
2.回溯和深度优先搜索有什么关系呢?
①:上面我们可以看到,我们在使用深度优先搜索二叉树节点的时候,因为我们并不知道节点到底是在二叉树的哪个部分,对于二叉树这种数据结构,我们查找一个不知道位置的节点是比较困难的,所以如果我们使用递归的方法进行,那么就变得比较简单了。而递归就是对当前的处理进行递归,也就是如上面查找节点,我们对每个节点的左右子节点都进行查找,这样查找的就是全树的节点,并且它的查找方式是从节点开始,一致到最左边的一个节点,也就是遍历的时候,直接一开始搜索到二叉树的最底层,然后开始往上回溯(也就是回溯的官方定义,如果说我们遍历的这个节点是根节点或者是空节点,那么就代表此次递归到头了,要返回上去,由上一层再选择另外一个子节点进入,如果说另外一个子节点都已经被使用了,那么就继续往上走就证明此路不通了,要继续向上返回找通路)而这种搜索方式和回溯的很像。
②:如何才能一次性走到黑呢?所以这也就是递归的用法了,其实对于回溯算法和深度优先的搜索,它们的实现基本上都是和递归有关,因为递归可以让我们有回溯这个功能,当遍历一条路走不通的时候,然后退出该子路然后回来还可以选择其他的路。( 其实在很多情况下,深度优先的搜索其实就是回溯的搜索)
广度优先的搜索(BFS)
广度优先的搜索和深度优先的搜索方式是不同的。
(以搜索二叉树的某个节点为例):
- 深度优先搜索:搜索方式是从根节点出发,一次性直接搜索到到一个条路的尽头。(也就是搜索到第一个叶子节点,然后再往回依次回溯)
- 广度优先的搜索:搜索方式也是从根节点出发,但是他并不是直接一条路走到黑直接走到第一个叶子节点,而他是每层每层的遍历,就是先遍历根节点这一层,然后遍历根节点的子节点这一层,然后依次往下,知道遍历到我们需要的哪个节点或者最后一层遍历完成。
所以广度优先的搜索也叫一石激起千层浪。
假设我们还是在上面那个二叉树身上进行操作,我们要在上面这个二叉树上找到我们想找到的那个值,我们可以这样操作:
TreeNode* FindNode(TreeNode* root,int val)
{
queue<TreeNode*> q;
q.push(root); //使用队列这个结构(先进先出),可以让我们更方便的去管理每层的数据
while(!q.empty())
{
TreeNode* node = q.front(); //取出队头节点
q.pop(); //取出之后就可以在队列中删除该节点
if(node->val == val) //如果说队头节点就是我们查找的节点,那么就返回
{
return node;
}
if(node->left != nullptr) //然后加入子节点,因为不能加入空节点,所以我们先判空再加入。
{
q.push(node->left);
}
if(node->right != nullptr)
{
q.push(node->right);
}
}
return nullptr;
}
通过上述数的代码,我们就可以按找顺序(从上到下,从做到右的顺序),去遍历这个树。
回溯算法的剪枝环节
对于回溯算法,其实一般情况下就是这些步骤,大体结构如下:
void backtrack()
{
//1.终止条件
if(终止条件) //(就是达到我们的要求时,证明这个顺序是可以的)
{
存放结果
return;
}
for(遍历每层)
{
//2.去重
if(重复了)
{
continue;
}
//3.处理节点(一般我们会用某个结构来保存这个节点)
ans.push_back(节点数据)//ans是我们假设一个的数据结构
//4.进行递归
backtrack();
//5.删除刚才加入的节点(也就是回溯)
ans.pop();
}
}
而所谓剪枝,就是上面的去重环节,而对于剪枝,顾名思义,也就是给树剪树枝,剪树枝肯定是剪我们不要的东西。(对于递归来说,因为他是递归,所以和树很像,第一个开始调用自己函数的函数可以看作是根节点,然后每次同一个函数的递归,可以把当前的递归看成是开始调用递归的那个子函数,这样下来,就形成了一个树)
具体我们通过下面的例题来进行说明:
我们来看如下例题(取自力扣):
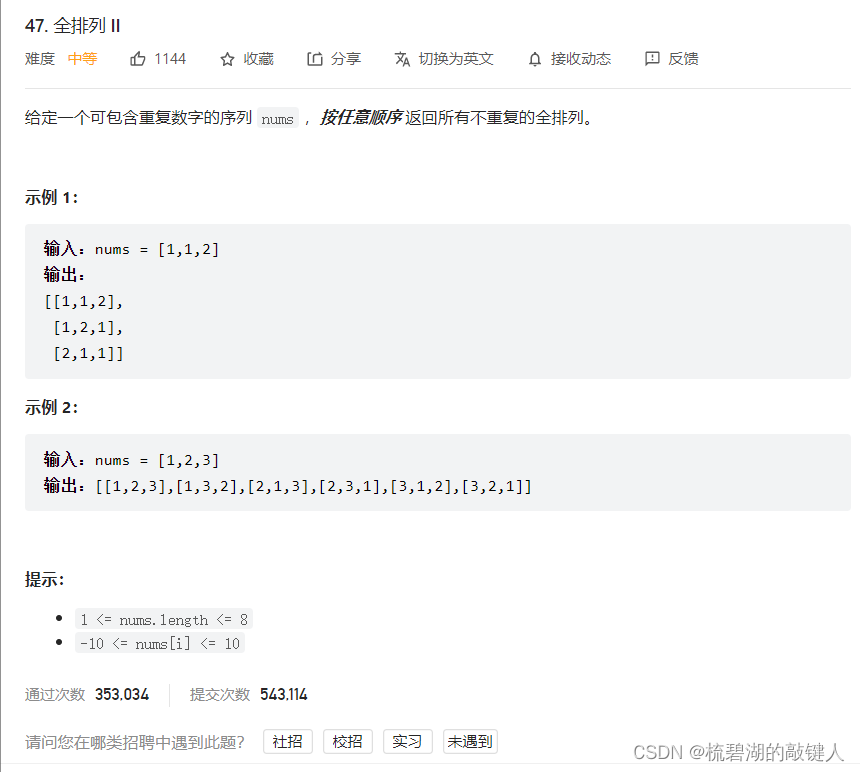
这道题的要求我们在数组nums中去取出它的所有组合,但是要求是不重复。
所以我们的解题顺序如下:
- 因为是全排列,所以返回的这个容器里面应该保存的是数组元素,所以我们返回的结构是
vector<vector<int>> ans,然后再设置一个结构,来表示当前路径vector<int> combine; - 全排列的意思是对nums中的数据重新组合,所以对于当前路径来说,当前路径的长度如果和nums的长度相等了,那么就证明我们已经找到了一个合适的路线,所以第一步终止条件应该是这样的:
if(combine.size() == nums.size())
{
ans.emplace_back(combine); //保存该数据然后返回
return;
}
- 接下来我们就要看我们要遍历多少次了,因为对于这个nums来说,他是全排列组合,所以他里面的每个数,都有机会称为这个全排列的头部,所以我们要循环的次数应该是nums的长度,所以对于遍历次数我们这样写:
for(int i = 0;i < nums.size();++i)
{}
- 去重环节,我们知道对于一个递归而言,它的操作就像是对一个树进行操作一样,而对重复的(也就是不符合我们要求的)直接终止走这条路即可,而我们是如何操作呢,先看如下图:
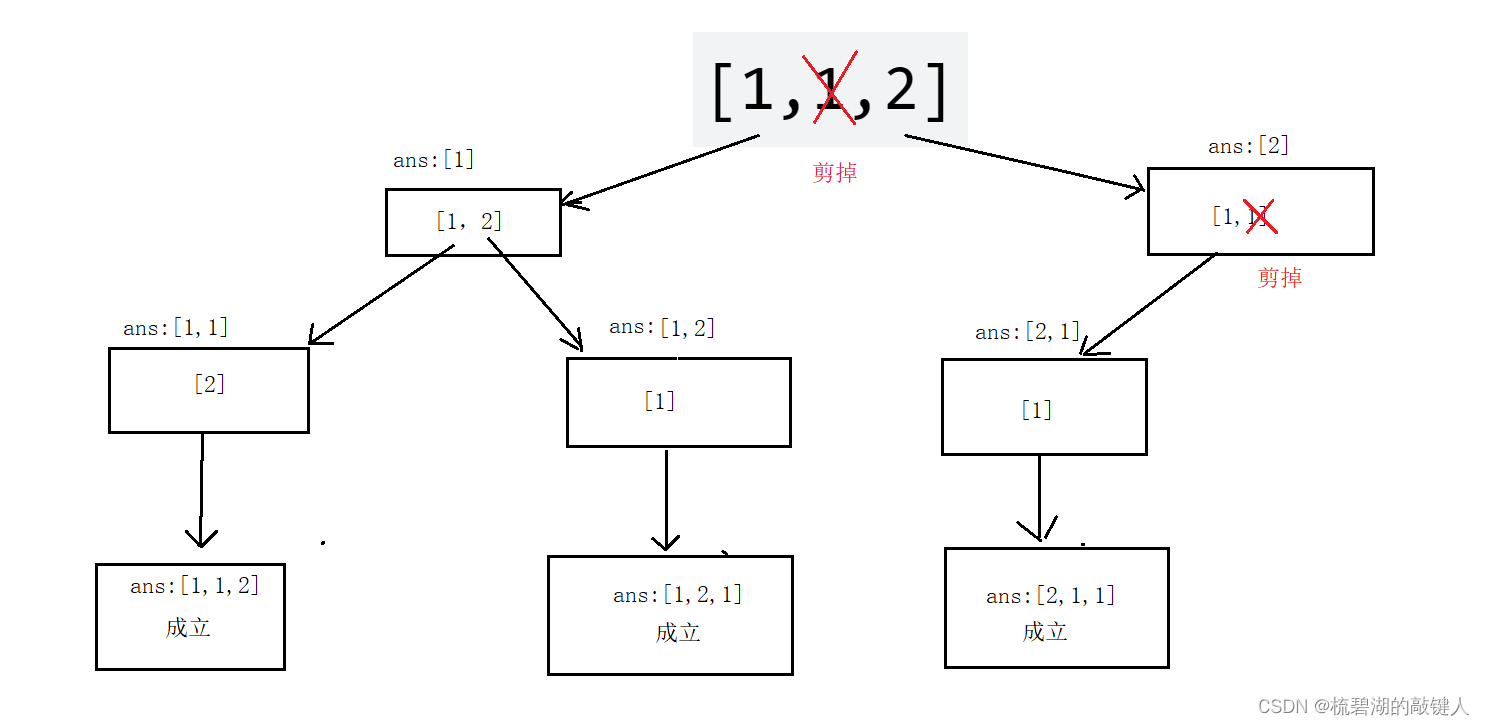
对于上面的例子,我们进行对二叉树的操作,如上图:上图中,我们对符合题意的组合进行了往下保留,而对于不符合题意的要求,我们进行了剪纸,也就是去重。
①:为什么这样去重?
-
对于一个不要重复排列的全排列而言,而对于重复的排列的产生,主要的原因就是重复数字来造成的,如上图的如果我们不进行去重,那么就会再出现[1,1,2],[2,1,1],[1,2,1],主要的原因是有两个1,而这两个重复的1分别在自己上次排列的相对位置,因为操作的时候,它俩的下标不一样,我们不能通过下标的选取直接进行判断,所以我们必须通过去重环节进行去重。
-
首先为了方便我们对重复元素进行操作,所以我们对原始的nums进行排序,这样重复的元素就会集中起来。然后我们操作的时候,这些相同的元素在一块,而对于重复的元素进行操作,要满足不会出现重复的组合情况,那么就必须让他们的出现的顺序就和排列时的顺序一样。
-
假设在nums中上例的排序是这样[1,1,2],出现重复的原因是,重复数据在同一个位置的重复选择,而我们不要重复排列组合,那么就必须保证重复数据直接不能出现重复选择,所以对于上面的例子,第一个1对应的位置下标一定要小于第二个1对应位置的下标,只有保证它们所处相对位置是固定的,这样对于相同元素排序在每个排列中出现的。(这样会避免下标不同的重复数据的重复排列组合)
代码如下:
if(book[i] || nums[i] == pre)//其中,book是保存那个数是否被使用,如果被使用,就不可以用该树,或者该数与它前一个数相等( pre表示该数在数组中的前一个位置)
{
continue;
}
- 然后就处理节点、进行递归、回溯操作。
总体解题代码如下:
class Solution {
public:
vector<vector<int>> ans;
vector<int> combine;
vector<bool> book;
void DFS(vector<int>& nums,int& sz)
{
if(combine.size() == sz)
{
ans.emplace_back(combine);
return;
}
int pre = -11; //题目所说最小数是-10,所以取-11,刚好不会出现在第一次就出现相等的错误情况。
for(int i = 0;i < sz;++i)
{
if(book[i] || nums[i] == pre)
{
continue;
}
pre = nums[i];
book[i] = true; //该数被使用过
combine.emplace_back(nums[i]); //保存该数
DFS(nums,sz);
combine.pop_back(); //回收该数,则该数又可以备选了
book[i] = false;
}
}
vector<vector<int>> permuteUnique(vector<int>& nums)
{
int sz = nums.size();
book.resize(sz,false);
sort(nums.begin(),nums.end()); /进行排序
DFS(nums,sz);
return ans;
}
};















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









