







什么是跳表
1.跳表,也是基于链表实现的,他其实和链表一样,也是一个数据结构中的查找结构,用于解决一些查找问题而产生。
2.跳表虽然是基于链表所实现的,但是不同于链表的是,他的查询效率比较高,也可以说他的出现是链表的一个优化,具体优化的思想如下:
- 链表我们知道,每次都是一个节点指向一个节点,中间没有跳过任何节点,一条路指到头的,所以他的查找的时间复杂度都是O(N)。如下图,就是一个链表的形式。

- 因为链表的查找时间很慢,所以制造跳表的人就想了想,如果说每次相邻的两个节点升高一层,增加一个指针,让指针指向下下个节点,这样新增加的节点又构成了一个链表,并且长度是原来链表长度的一般,这样我们查找一个数的时候,查找效率会提高一倍。如下图,就是优化后的链表:

- 这时他又想提高效率,在每隔两个双层的节点上再增加一层,这样提高的效率就很高了,如下图:

- 跳表其实就是这样被创造出来的,按照上面的情况分析,每一层都是下一层节点数的一半,这样的查找会根据节点所处层的高低将查找的时间复杂度降低为O(log n),但是虽然这样查找的效率很高,但是对于跳表的操作就会显得很复杂,如果插入或者删除一个节点的话,那么就会打乱每两个节点升高一层这样的结构,所以这样的结构还是出现问题了,所以也有了下一步的优化。
- 跳表的设计为了避免这样的问题出现,做了一个大胆的处理,不严格要求对应的比例关系,直接每次插入节点的时候随机一个高度插入,这样插入和删除某个节点的时候,就不用考虑周围节点的高度变化了。
跳表的性能分析
因为跳表在插入节点的时候,是随机一个节点的高度进行插入的,所以会指定一个最高的高度,并且会设计一个概率函数去制定每次插入的节点的高度是多少,并且计算高度的这段伪函数如下:

在Redis中跳表的实现中两个值的参数分别为:
p = 1/4; //概率
maxLevel = 32; //最高高度
通过上面的伪代码,我们可以看出来,高度越高的节点,出现的概率越小,因为random()这个区间的分布为0~1,而p = 1/4,只有当random()<p的时候,才能让高度增加,而每次都将是1/4的n次方(n代表的是出现到几),概率是非常小的。
所以也有了下面这个概率的公式,为取到固定高度的公式: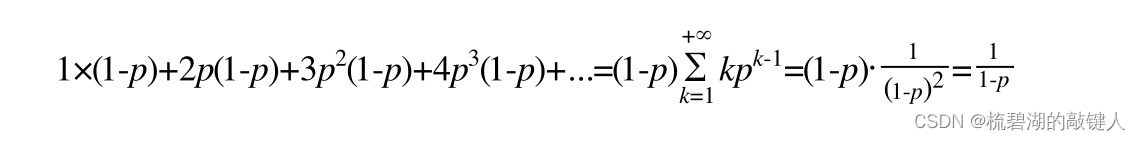
跳表的实现
其中删除节点和插入节点的时候比较复杂.
首先,我们先看操作的节点信息:
template<class T>
struct SkipNode
{
T data;
vector<SkipNode*> _vNext;
SkipNode(int val, int level)
:_vNext(level, nullptr)
, data(val)
{}
};
1.因为是跳表操作,所以每次增删的时候,都必须知道增加节点的前一个节点和后一个节点,此时要用数组保存起来,为了方便后面进行修改:
//寻找插入或删除节点时要修改的节点
vector<Node*> _Findpre(const T& val)
{
vector<Node*> ret(_head->_vNext.size(),_head); //提前开好空间,然后赋值
Node* p= _head;
int level = _head->_vNext.size() - 1;
while (level >= 0)
{
if (p->_vNext[level] == nullptr || p->_vNext[level]->data >= val) //往下跳
{
ret[level] = p; //保存插入节点直接相连的前面个节点
level--; //这块注意一定要赋值,不能给push_back,因为push_back后的结果
} //会让原来水平的方向颠倒,因为我这个是level是--。
else
{
p = p->_vNext[level]; //往后跳
}
}
return ret;
}
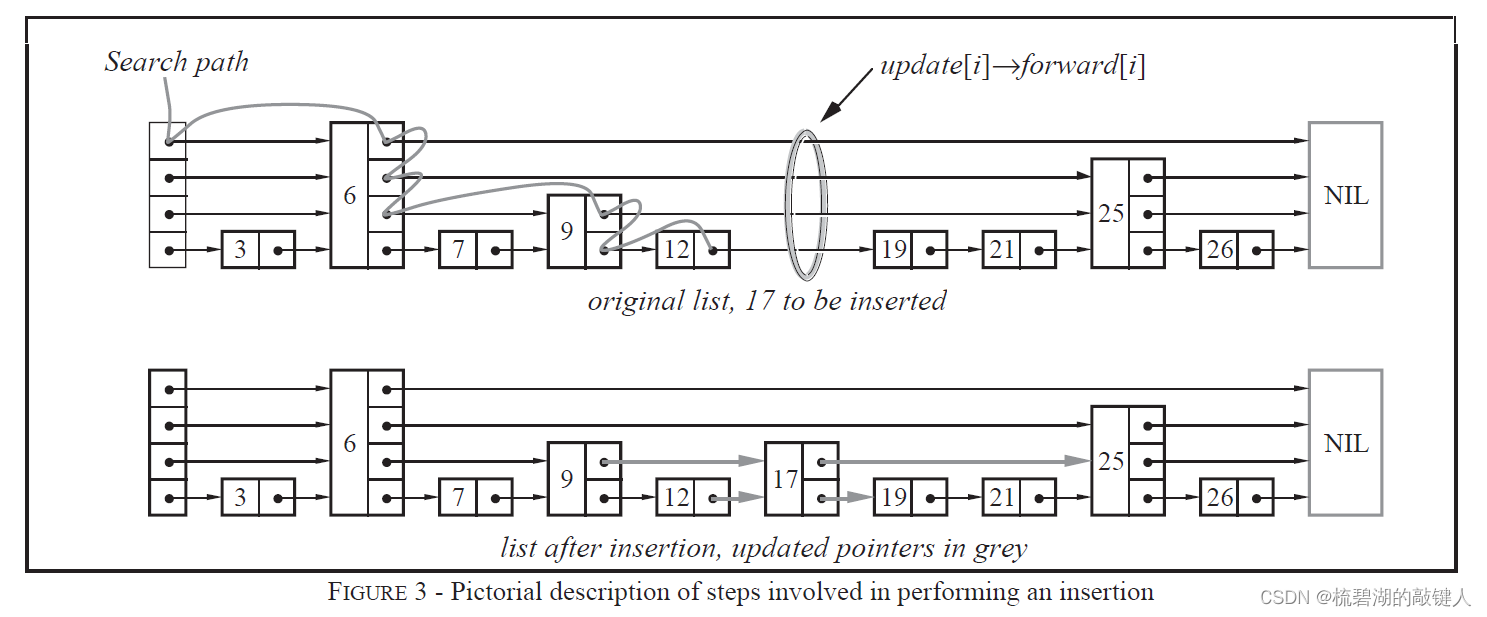
2.插入节点:插入节点是有些没法,但是只要在插入节点的找到该节点插入的位置,并且插入节点的高度,并且将需要修改的节点保存起来,然后进行按层插入即可,如下:
/插入节点
bool Insert(T val)
{
if (_head == nullptr) //如果调表为空,直接插入
{
Node* p = new Node(val, 1);
_head = p;
return true;
}
size_t h = Gethight();
Node* node = new Node(val, h);
vector<Node*> pre = _Findpre(val); //寻找插入节点时需要修改的值
if (h > _head->_vNext.size()) //如果新产生的节点高度大于根节点高度
{
_head->_vNext.resize(h,nullptr); //修改根节点高度,那么赋值应该还是根节点的data
pre.resize(h,_head);
}
for (size_t i = 0; i < h; ++i) //插入节点
{
node->_vNext[i] = pre[i]->_vNext[i];
pre[i]->_vNext[i] = node;
}
return true;
}
3.删除操作也一样,只需要找到删除节点的前一个节点,就可以进行操作了:
//删除节点
bool erase(T val)
{
if (_head == nullptr || FindVal(val) == false) //节点不存在表中
{
return false;
}
//找到节点删除
vector<Node*> pre = _Findpre(val);
Node* del = pre[0]->_vNext[0];
for (int i = 0; i < del->_vNext.size(); ++i)
{
pre[i]->_vNext[i] = del->_vNext[i];
}
delete del;
//如果说删除的节点是存在的最高节点,那么头节点的高度要降
int i = _head->_vNext.size()-1;
while (i > 0)
{
if (_head->_vNext[i] == nullptr)
{
--i;
}
else
{
break;
}
}
_head->_vNext.resize(i+1);
return true;
}
4.整体代码如下:
#include<iostream>
#include<vector>
using namespace std;
template<class T>
struct SkipNode
{
T data;
vector<SkipNode*> _vNext;
SkipNode(int val, int level)
:_vNext(level, nullptr)
, data(val)
{}
};
template<class T>
class SkipTable
{
typedef struct SkipNode<T> Node;
public:
SkipTable()
:_head(nullptr)
,_maxLevel(32)
, _p(0.25)
{}
public:
//获取该新节点的高度
size_t Gethight()
{
size_t level = 1;
// rand() ->[0, RAND_MAX]之间 //经典取随机数算法
while (rand() <= RAND_MAX * _p && level < _maxLevel) //获取多个随机数,手机随机数的大小小于
{ //_maxLevel的数量
++level;
}
return level;
}
//查找节点是否存在跳表中
bool FindVal(const T& val)
{
if (_head == nullptr)
{
return false;
}
Node* p = _head;
int level = p->_vNext.size()-1; //头节点的高度(也代表者跳表中存在节点的最高高度)
while (level >= 0)
{
if (p->_vNext[level] == nullptr || p->_vNext[level]->data > val) //往下跳
{
level--;
}
else if (p->_vNext[level]->data == val)
{
return true;
}
else
{
p = p->_vNext[level]; //往后跳
}
}
return false;
}
//寻找插入或删除节点时要修改的节点
vector<Node*> _Findpre(const T& val)
{
vector<Node*> ret(_head->_vNext.size(),_head); //提前开好空间,然后赋值
Node* p= _head;
int level = _head->_vNext.size() - 1;
while (level >= 0)
{
if (p->_vNext[level] == nullptr || p->_vNext[level]->data >= val) //往下跳
{
ret[level] = p; //保存插入节点直接相连的前面个节点
level--; //这块注意一定要赋值,不能给push_back,因为push_back后的结果
} //会让原来水平的方向颠倒,因为我这个是level是--。
else
{
p = p->_vNext[level]; //往后跳
}
}
return ret;
}
//插入节点
bool Insert(T val)
{
if (_head == nullptr) //如果调表为空,直接插入
{
Node* p = new Node(val, 1);
_head = p;
return true;
}
size_t h = Gethight();
Node* node = new Node(val, h);
vector<Node*> pre = _Findpre(val);
if (h > _head->_vNext.size()) //如果新产生的节点高度大于根节点高度
{
_head->_vNext.resize(h,nullptr); //修改根节点高度,那么赋值应该还是根节点的data
pre.resize(h,_head);
}
for (size_t i = 0; i < h; ++i) //插入节点
{
node->_vNext[i] = pre[i]->_vNext[i];
pre[i]->_vNext[i] = node;
}
return true;
}
//删除节点
bool erase(T val)
{
if (_head == nullptr || FindVal(val) == false) //节点不存在表中
{
return false;
}
//找到节点删除
vector<Node*> pre = _Findpre(val);
Node* del = pre[0]->_vNext[0];
for (int i = 0; i < del->_vNext.size(); ++i)
{
pre[i]->_vNext[i] = del->_vNext[i];
}
delete del;
//如果说删除的节点是存在的最高节点,那么头节点的高度要降
int i = _head->_vNext.size()-1;
while (i > 0)
{
if (_head->_vNext[i] == nullptr)
{
--i;
}
else
{
break;
}
}
_head->_vNext.resize(i+1);
return true;
}
void Print()
{
for (int i = _head->_vNext.size()-1; i >= 0; --i)
{
Node* p = _head;
while (p)
{
cout << p->data << "->";
p = p->_vNext[i];
}
cout << endl;
}
}
private:
Node* _head;
size_t _maxLevel;
float _p;
};















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









