






参考文献:
【主要参考(万分感谢)】https://blog.csdn.net/qq_26848943/article/details/81011709
https://blog.csdn.net/lisonglisonglisong/article/details/46974723#t0
hbase跟hadoop版本关系https://hbase.apache.org/book.html#basic.prerequisites
zookeeper下载地址https://zookeeper.apache.org/releases.html
hadoop下载地址:https://archive.apache.org/dist/hadoop/common/
snappy压缩内容:https://hbase.apache.org/book.html#compression
- 准备安装包
openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
hbase-2.5.5-bin.tar.gz
hadoop-2.10.2-src.tar.gz
apache-zookeeper-3.8.2-bin.tar.gz
2.为每个服务器都安装好java环境,服务器要开通相应端口如3888
3.添加Hosts映射关系
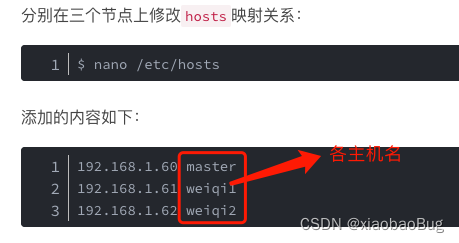
4.集群之间SSH无密码登陆
主节点执行
ssh-keygen -t rsa
子节点执行
cp ~/.ssh/id_rsa.pub ~/.ssh/《替换当前主机名》.id_rsa.pub //复制备份
scp ~/.ssh/《替换当前主机名》.id_rsa.pub 《替换主节点主机名》:~/.ssh //拷贝到master准备认证
回到主节点执行
参考:https://blog.csdn.net/qq_26848943/article/details/81011709
完成后可通过以下代码来测试是否无密连接
ssh 《节点主机名》
5.配置hadoop
参考:https://blog.csdn.net/qq_26848943/article/details/81011709
6.配置zookeeper
参考:https://blog.csdn.net/qq_26848943/article/details/81011709
遇到的问题:
1.zookeeper启动报错:错误: 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain
原因:https://blog.csdn.net/succing/article/details/127837281
2.zookeeper无法连接子节点3888端口,拒绝连接
原因:3888绑定在本地回环地址127.0.0.1上。
解决:需要在zookeeper配置zoo.cfg上加
quorumListenOnAllIPs=true
3.hadoop无法连接DataNode
原因:端口9000绑定在127.0.0.1上
解决:修改/etc/hosts文件,将本机名对应的ip改成对外访问的ip
4.snappy压缩
4.1将hadoop的这两个文件和snappy的这两个文件在同一个地方
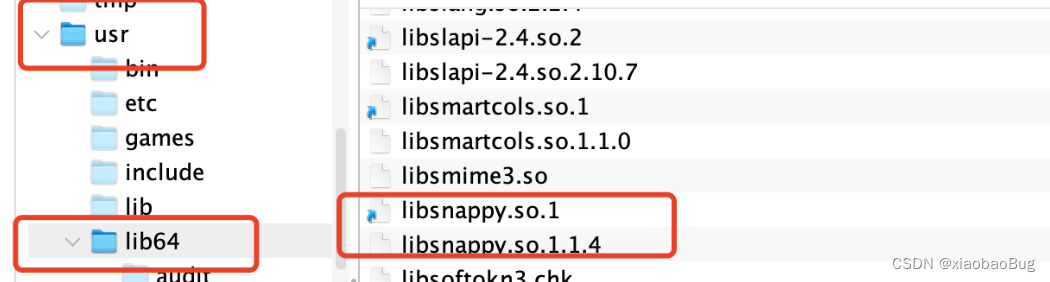

4.2配置hbase中hbase-env.sh文件
这里的路径是上面的文件存放路径
`export HBASE_LIBRARY_PATH=/usr/lib64`
5.java无法连接到hbase集群
修改本机的hosts文件(主机名跟hbase-site中的节点一样)
《外网ip》 主机名














 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









