







Storm - 大数据Big Data实时处理架构
什么是Storm?
Storm是:
• 快速且可扩展伸缩
• 容错
• 确保消息能够被处理
• 易于设置和操作
• 开源的分布式实时计算系统
- 最初由Nathan Marz开发
- 使用Java 和 Clojure 编写
Storm和Hadoop主要区别是实时和批处理的区别:

Storm概念 组成:Spout 和Bolt组成Topology。
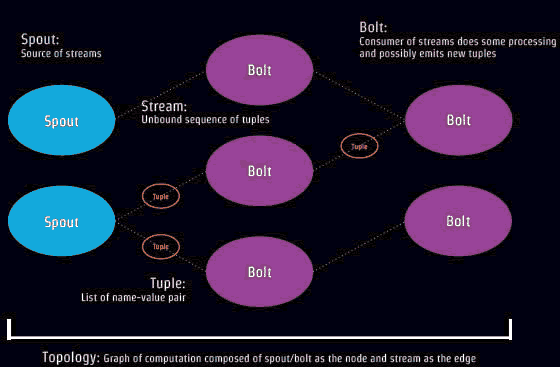
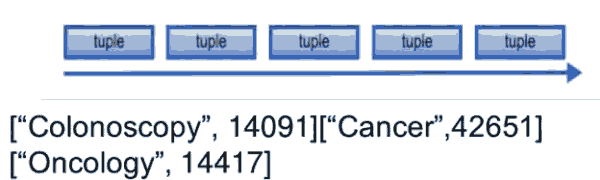
Tuple是Storm的数据模型,如['jdon',12346]
多个Tuple组成事件流:
Spout是读取需要分析处理的数据源,然后转为Tuples,这些数据源可以是Web日志、 API调用、数据库等等。Spout相当于事件流的生产者。
Bolt 处理Tuples然后再创建新的Tuples流,Bolt相当于事件流的消费者。
Bolt 作为真正业务处理者,主要实现大数据处理的核心功能,比如转换数据,应用相应过滤器,计算和聚合数据(比如统计总和等等) 。
以Twitter的某个Tweet为案例,看看Storm如何处理:

这些tweett贴内容是:“No Small Cell Lung #Cancer(没有小细胞肺癌#癌症)” "An #OnCology Consult...."
这些贴被Spout读取以后,产生Tuple,字段名是tweet,内容是"No Small Cell Lung #Cancer",格式类似:['No Small Cell Lung #Cancer',133221]。
然后进入被流 消费者Bolt进行处理,第一个Bolt是SplitSentence,将tuple内容进行分离,结果成为:一个个单词:"No" "Small" "Cell" "Lung" "#Cancer" ;然后经过第二个Bolt进行过滤HashTagFilter处理,Hash标签是单词中用#标注的,也就是Cancer&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









