







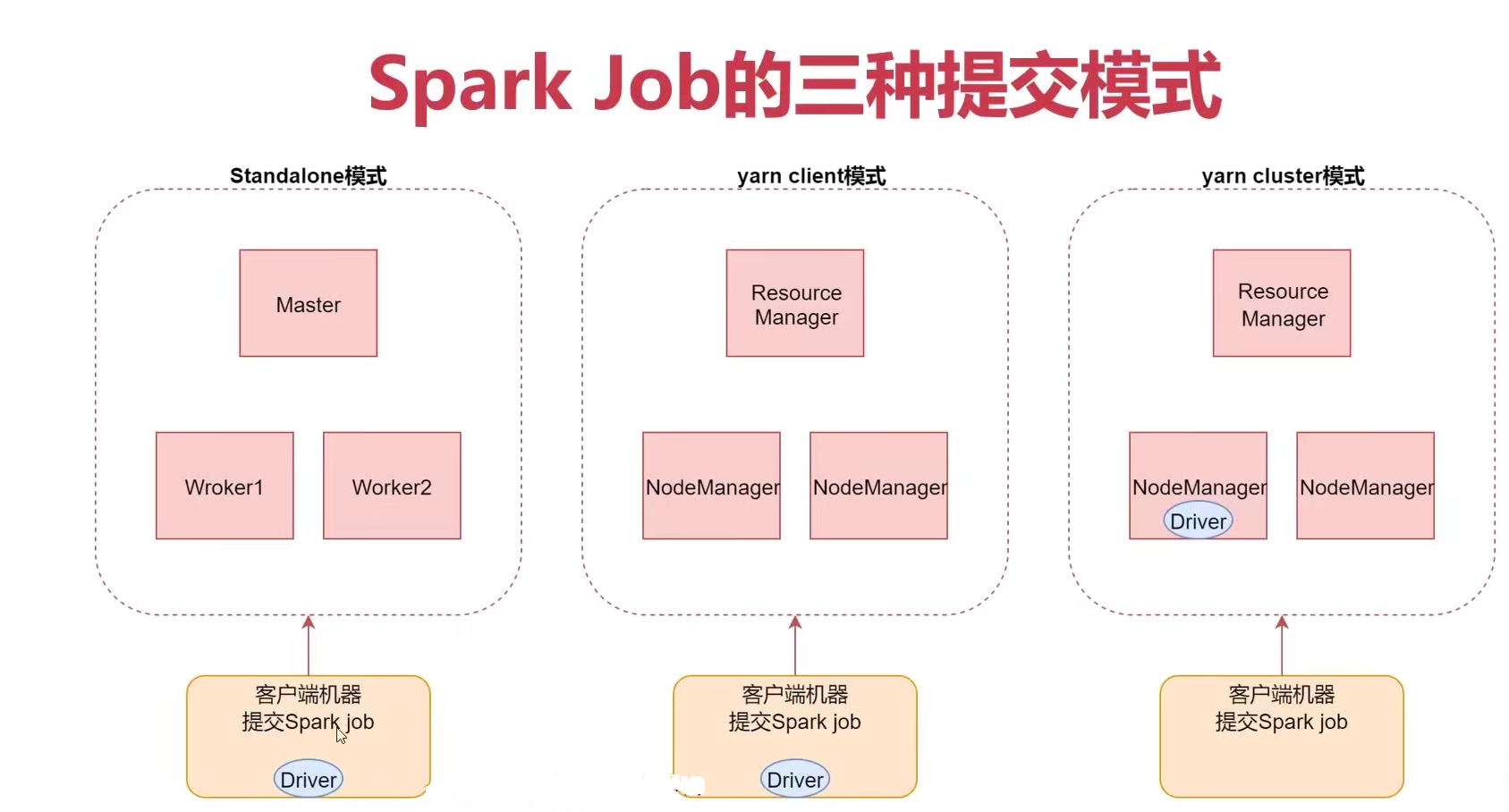
spark Job的三种提交模式
-
- standalone模式
standalone模式
spark-submit --master spark://bigdata01:7077
- standalone模式
-
2 : yarn client模式
spark-submit --master yarn --deploy-mode client
- 3: yarn cluster模式【推荐】
spark-submit --master yarn --deploy-mode cluster
Shuffle介绍
在spark中,什么情况下,会产生shuffle
reduceByKey,groupByKey,sortByKey,countByKey,join等等
spark shuffle一共经历了几个过程:
1:未优化的 Hash Based Shuffle
2:优化后的 Hash Bashed Shuffle
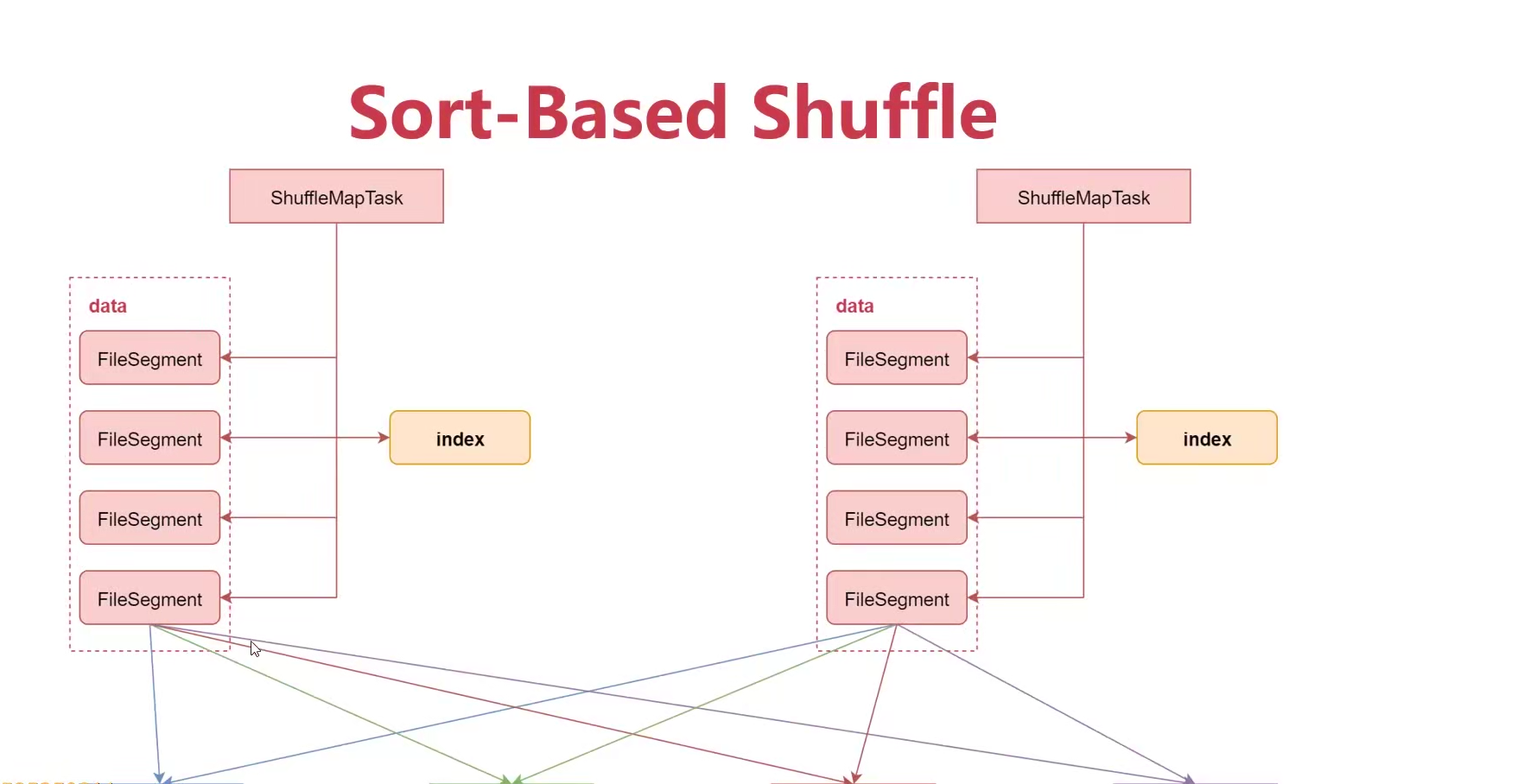
3: Sort-Based Shuffle
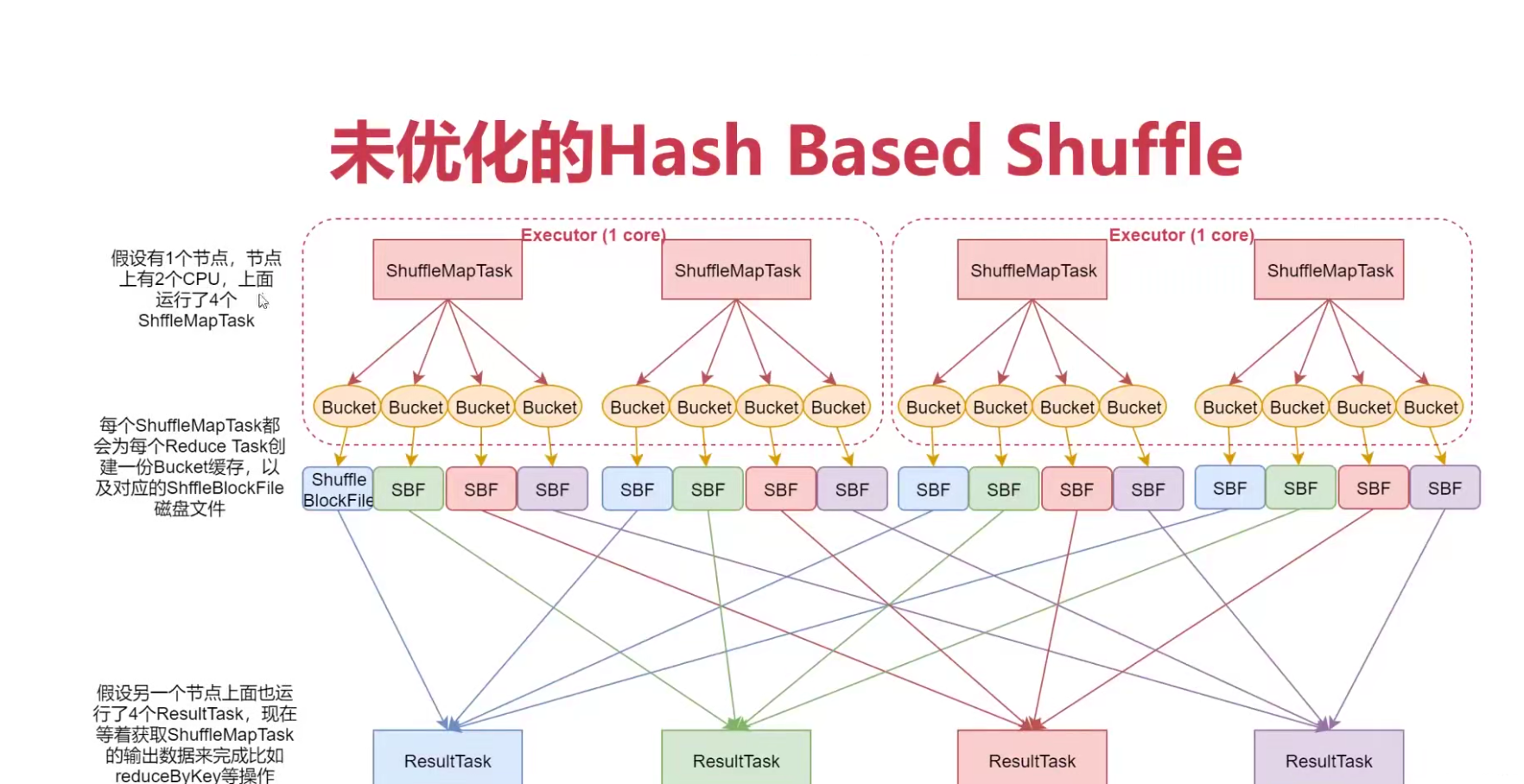
so:如果有100个map task,100个result task,那么本地磁盘会产生10000个本地,磁盘io过多,影响性能
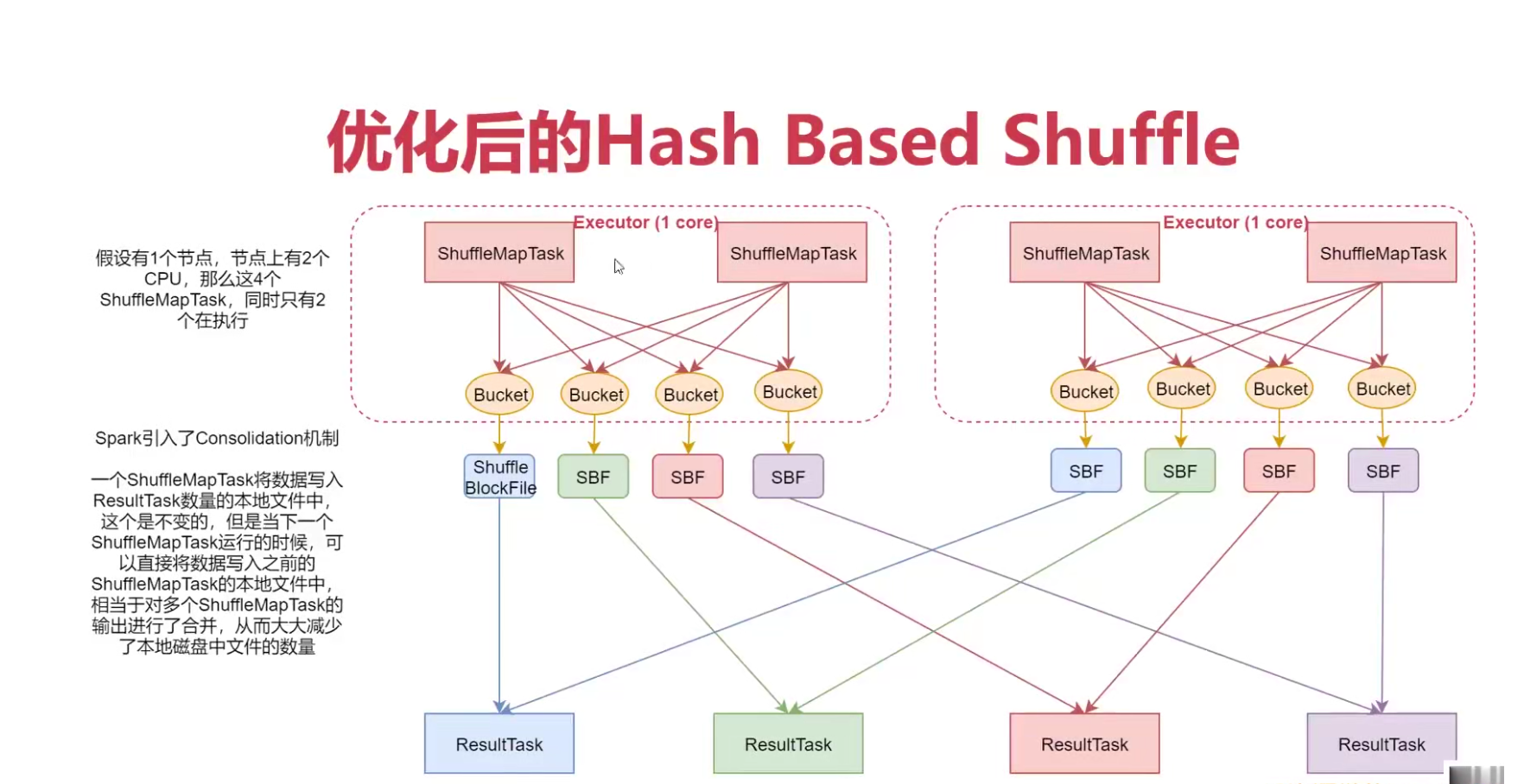
so:此时文件的数量变成了 cPU core 数量 * result task 数量,比如每个节点上有2个cpu,有100个resulttask,那么每个节点上会产生200个文件
checkpoint
checkpoint功能:
- 针对Spark Job,如果我们担心某些关键的,在后面会反复使用RDD,因为节点故障导致数据丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
checkpoint 类似于快照机制 - 首先调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统目录(HDFS),然后对RDD调用checkpoint()方法
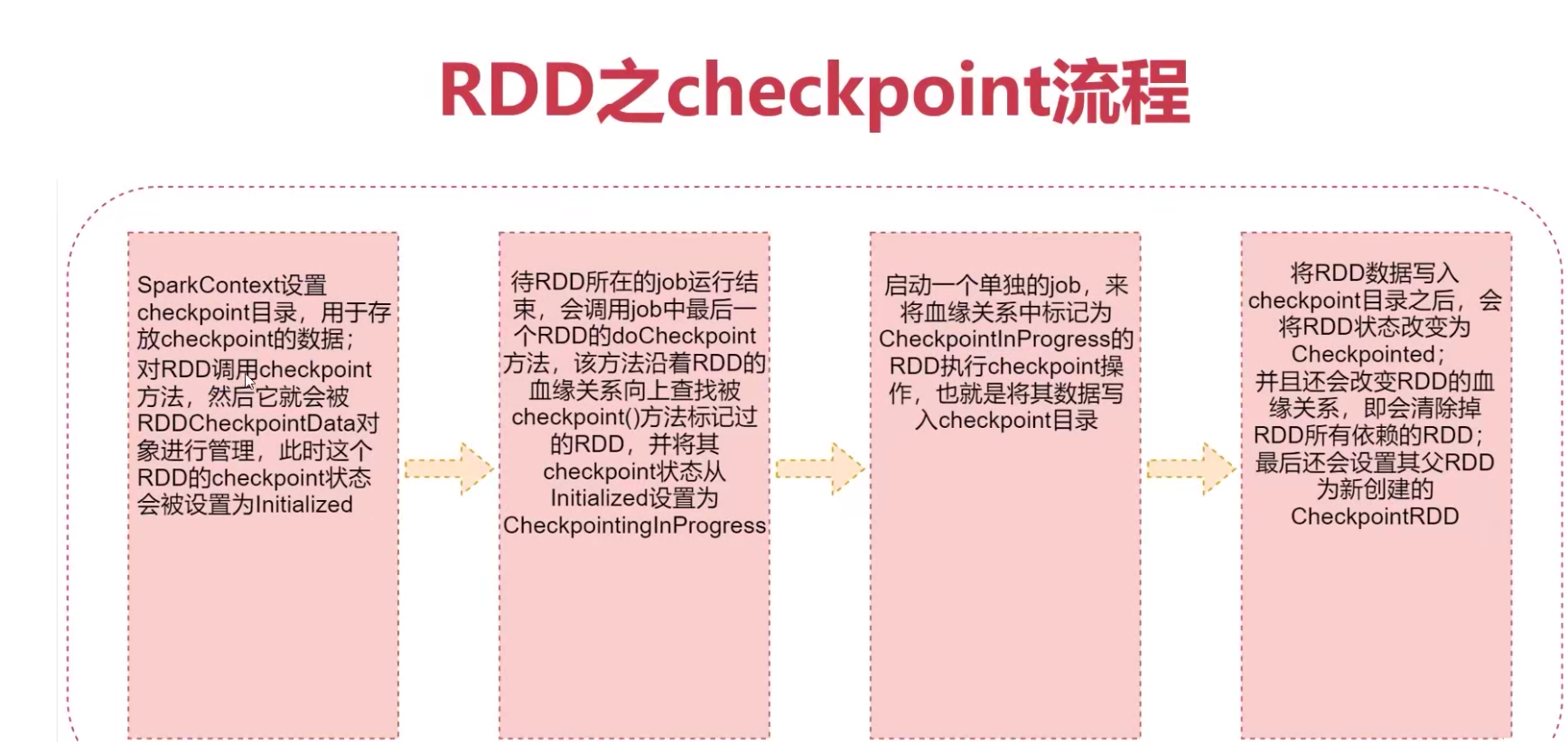
checkpoint与持久化的区别
- lineage(血缘关系)是否发生改变
- 丢失数据的可能性
- 建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









