







哈希表/散列表
哈希表是根据关键码值直接进行访问的数据结构。通过关键码值映射到表中一个位置来访问记录,加快查找的速度,这个映射函数叫做哈希函数(散列函数),存放记录的叫做哈希表(散列表)。
构造哈希函数的几种方法
1、直接定址法
2、 除留取余法
3、平方取中法
4、折叠法
哈希冲突/哈希碰撞
产生:不同的key值经过哈希函数处理以后,可能产生相同值的哈希地址,这就是哈希冲突,任何哈希函数都不能避免哈希冲突。
哈希函数的两个特点:
1、如果两个散列值是不同的(根据同一函数),那么这两个散列值的原始输入也是不同的。
2、散列函数的输入和输出不是唯一的对应关系,如果两个散列相同,两个输入值很可能是相同的,但也可能是不同的(这种情况就叫做哈希冲突或者散列冲突)。
缺点:哈希表的空间效率不够高,一般的存储效率只有50%。
解决哈希冲突
闭散列
1、线性探测
2、二次探测
#include<iostream>
using namespace std;
enum State
{
EMPTY,//空
EXCITE,//存在
DELETE,//标记为空,但不为空
};
template<typename T>
class Hashtable
{
public:
Hashtable(size_t capacity)
:_capacity(capacity)
, _size(0)
{
_table = new T[_capacity];//开辟哈希空间
_state = new State[_capacity];//开辟和哈希容量一样的空间存放状态
memset(_table, T(), sizeof(T)*_capacity);//初始化哈希表
memset(_state, EMPTY, sizeof(State)*_capacity);//初始化存放状态的空间
}
~Hashtable()
{
delete[]_table;
delete[]_state;
}
public:
bool Insert(const T& key)//插入元素
{
if (_size == _capacity)//满了就退出
return false;
size_t pos = hashFun1(key);//计算key值的下标
int idx = 1;
while (_state[pos] == EXCITE)//这个位置有值
{
if (_table[pos] == key)//该值为key
return false;//返回
//pos++;//继续向后找空白位置
//if (pos == _capacity)//找到最后一个回到第一个继续找
// pos = 0;
pos = hashFun2(pos, idx++);
}
_table[pos] = key;
_state[pos] = EXCITE;
_size++;
return true;
}
bool Remove(const T& key)
{
if (_size <= 0)//哈希表为空,直接退出
return false;
size_t pos = hashFun1(key);//计算key值的下标
int idx = 1;
while (_state[pos] != EMPTY)
{
if (_table[pos] == key && _state[pos] != DELETE)
{
_state[pos] = DELETE;
return true;
}
//pos++;
//if (pos == _capacity)
// pos = 0;
pos = hashFun2(pos, idx++);
}
return false;
}
bool Find(const T& key)
{
if (_size <= 0)//哈希表为空
return false;
size_t pos = hashFun1(key);
int idx = 1;
while (_state[pos] != EMPTY)
{
if (_state[pos] != DELETE && _table[pos] == key)
return true;
//pos++;
//if (pos == _capacity)
// pos = 0;
pos = hashFun2(pos, idx++);//二次探测
}
return false;
}
void Hashprint();
private:
//一次探测
size_t hashFun1(const T& key)
{
return key % _capacity;
}
//二次探测
size_t hashFun2(size_t lasthash,int idx)
{
return(lasthash + 2 * idx - 1) % _capacity;
}
private:
T* _table;//哈希表
State* _state;//状态
size_t _capacity;//容量
size_t _size;//元素个数
};
template<typename T>
void Hashtable<T>::Hashprint()
{
for (int idx = 0; idx < _capacity; idx++)
{
cout <<_table[idx]<<"->"<< _state[idx]<<" ";
}cout << endl;
}
void Funtest()
{
Hashtable<int> ht(10);
ht.Insert(18);
ht.Insert(49);
ht.Insert(10);
ht.Insert(58);
ht.Insert(43);
ht.Hashprint();
ht.Remove(18);
ht.Hashprint();
cout << "find:"<<ht.Find(18) << endl;
}
开链法(哈希桶 )
数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易。结合两种特性做出一种寻址、插入、删除都容易的数据结构——哈希表。
哈希表最常用的一种方法——开链法
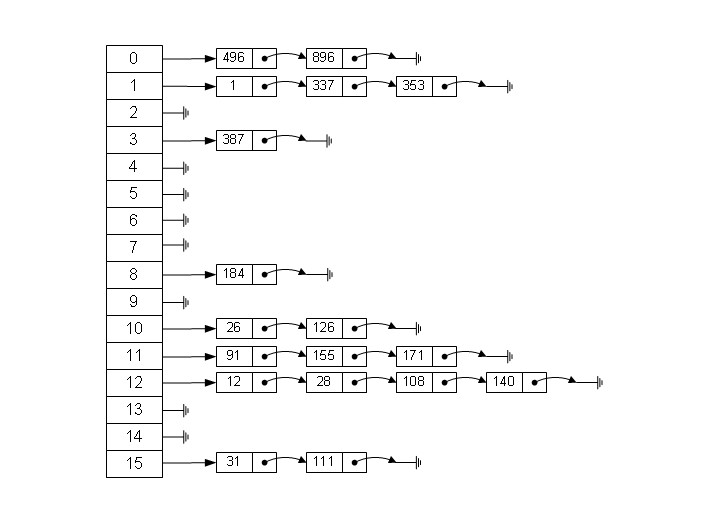
如图:
左边很明显是个数组,数组每个成员包括一个指针,指向一个链表的头,根据元素的特征把元素分配到不同的链表中去,根据这些特征,找到正确的链表,再从链表中找出这个元素。
布隆过滤器
原理:当一个元素被加入集合时,通过K个哈希函数将这个元素映射到一个位阵列中的K个点,把它们置为1.检索时,我们只要看看这些点是不是都是1就知道集合中有没有它:
1、如果这些点有任何一个0,则被检索元素一定不在。
2、如果都是1,则被检索的元素很可能在。
优点:
它的优点空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入/查询时间都是常数O(K)。
缺点:
1、随着存入元素数量的增加,误算率随之增加。
2、无法保证安全地删除元素。















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









