






总结前:不会的语法内容一定要学会如何查找mysql文档
一 : MySql的安装以及注意事项
不要安装到中文路径下
1.1配置环境变量
1.找到mysql安装目录的server 下的bin
2.将此目录添加到 环境变量的系统变量的path内
C:\install\mysql\server\bin
1.2 MySql的登录
cmd 打开dos窗口
mysql -u用户名 -p密码
mysql -uroot -p123456注意 :启动的过程需要mysql服务启动
1.3连接mysql (后期都会使用可视化工具)
开启服务
打开 我的电脑 右键 服务和应用程序 服务 运行
管理员身份 运行 cmd
net start 服务名
net stop 服务名
二:MySql的基本操作
- 创建数据库
- 展示所有数据库
- 创建表
- 选择数据库
- 展示当前库内所有的表
2.1中文乱码问题
方式一(在创建数据库时指定编码集 但是在其他数据库还会乱码)
create database B charset 'utf8';
查看数据库的编码集
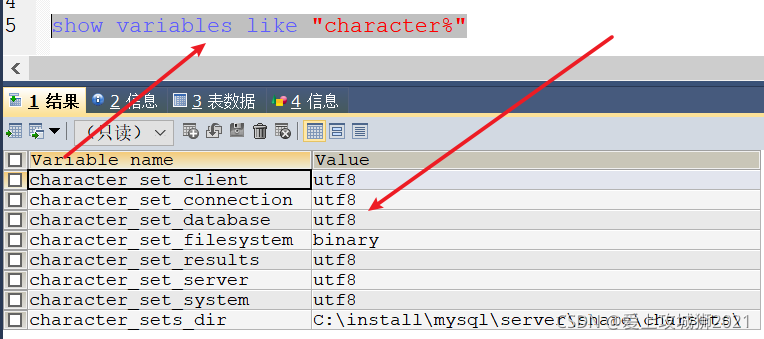
解决二:一劳永逸解决不能插入中文问题
安装路径下
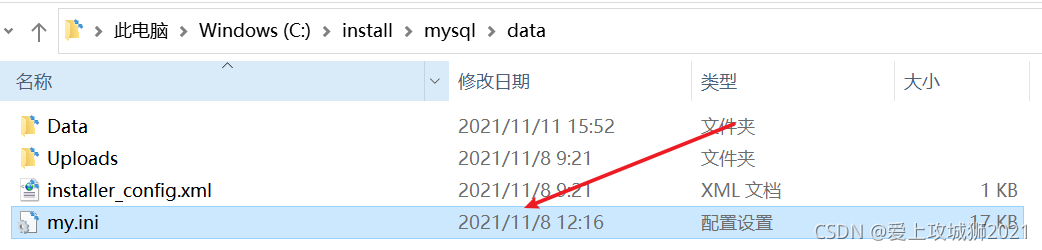
此操作一定要关闭mysql 重启服务
去掉 66 99 行 # 在等号后面写 utf8
default-character-set=utf8
character-set-server=utf8
重启服务之后,需要再次创建数据库进行测试,因为已经更改的操作对于之前的所有数据库的编码集不产生影响,只对后来的数据库有作用,因此要重新创建数据库进行测试
三.数据类型
3.1整型
整型 int
有符号 有正负
无符号 没有正负
3.2浮点型
double(5,3) 最多有5位数字 其中3位小数 对小数进行四舍五入
double 能存多少存多少decimal(20,18)最多有20位数字 其中18位小数 对小数进行四舍五入
默认保留(10,0) decimal 只会保留整数部分 且会对小数 四舍五入
3.3字符串类型
char: 定长字符串
varchar(20): 可变字符串
enum(男, 女):规定了列的值
set(a,b,c,d);规定了列的值 取值更加灵活 1 2 4 8 set 最多有64个
3.4 日期类型
create table datetest( y year,-- 年 d date,-- 年月日 t time,-- 时分秒 dt datetime, -- 年月日 时分秒 tt timestamp -- 年月日 时分秒 随着时区的变化 自动变化 );-- 新增数据 now() 获取当前时间 insert into datetest values(now(),now(),now(),now(),now());timestamp 会随着时区发生改变
设置时区
set time_zone='+9:00';
四:MySql的与法规范(见day01)
五:Sql分类
DDL: 数据定义语言 创建库 创建表 删除库 删除表
DML:数据操作语言 对数据的增删改
DQL:数据查询语言
DCL:数据控制语言
注意在有不会操作的语法时一定要学会查找MySql使用手册
5.1DDL(用来操作表)
创建篇
展示所有的库
创建数据库
删除库
创建表
展示所有的表
删除表
展示建表语句 (show create table 表名)
表中字段操作篇(查看文档)
- 列的定义 : 列的名字+列的类型
- 添加字段 (ALTER TABLE tbl_name ADD 列的定义 [FIRST | AFTER col_name ])
- 删除字段 (ALTER TABLE tbl_name DROP [COLUMN] col_name)
- 修改字段 (ALTER TABLE tbl_name CHANGE [COLUMN] old_col_name column_definition [FIRST|AFTER col_name])
- 修改字段类型 (ALTER TABLE tbl_name MODIFY column_definition [FIRST|AFTER col_name];)
- 更改表名 (alter table ctest rename 新表名;)
5.2 DML (操作表中的数据 不会查看文档)
数据新增
- insert into 表名 values(字段1....);-- 给所有字段添加值
- insert into 表名(字段) values(字段值);-- 给指定字段新增
- insert into 表名 set 字段 = 字段值。。。。; (添加的新数据只对本字段有效)
修改
- update 表名 set 字段 = 字段值 [where 。。。。]
- 如果没有筛选条件 则修改表中所有的数据
删除数据
delete from 表名 [where 筛选条件]
truncate table 表名;(是DDL 删除的效率比delete高,全部删除,创建一个新表)
六:Doc命令下的数据导入导出(一般会使用可视化工具)
数据导出
mysql 处于退出登录状态
- mysqldump -h主机名 -pmysql端口号 -u用户名 -p密码 导出的数据库名 > 磁盘地址
- mysqldump -uroot -p123456 variabletype >D:/a.sql
数据导入
- mysql 要处于登陆状态
- source 磁盘sql文件的路径
七:MySQL运算符
7.1 算数运算符
+
-
*
/ 可以保留 小数点(默认4位)
div 只保留小数点之前
% 取余数
mod 取余数
7.2比较运算符
>
<
>=
<=
!= 或者 <>
= 不能判断null值
<=> 等于 判断null值也可以判断正常值
7.3:逻辑运算符
逻辑与 : && 或 and
逻辑或: || 或 or
逻辑非: ! 或 not 取反
逻辑抑或 ^ 或 xor
相同为false,不同为true 两个条件不能同时满足 只能满足一个
比如:薪资大于10000的男生 或者 薪资<=10000的女生
select * from t_employee where salary >10000 xor gender ='女';(e.`salary` > 10000 && e.`gender` = '男') xor (e.`salary` <= 10000 and e.`gender` = '女')xor左右两端的条件不能同时满足
7.4:其他运算符
范围运算:
1> between and (salary between 10000 and 20000;) 在某个范围
2> in (1,3,5,7) 在某几个数中
模糊查询
1> %: 匹配任意0个或多字符
2> _:任意一个字符
关键字 like
7.5:位运算符 (和java中一样)
八:null值处理
方式一:
is null 表示是 null
is not null 表示不是null
方式二:
字段名 <=> null 表示是 null
not 字段名 <=> null 表示不是null
九:主键约束(目的保证插入的数据唯一)
9.1:添加主键约束:
建表时:
方式一:直接写在字段的后面
方式二:在字段的最后 插入主键 (primary key(id,age))
建表后:
alter table 表名 add primary key(字段名);
删除主键:删除联合主键也是如此,因为主键一张表中只有一个
alter table 表名 drop primary key;
查看主键名
select * from information_schema.`TABLE_CONSTRAINTS` where table_name = 表名
注意点:
1.主键的值不能重复
2.主键约束添加完毕会自动给该列建立索引
3.主键不能为null
4.联合主键/复合主键 只有当插入的数据完全一样时 才不能插入
5.一张表只能有一个主键
6.主键删除后会自动删除索引
查看索引的方式(show index from 表名)
9.2:唯一键约束
建表时
方式一: 在字段的后面 unique key
方式二: 在所有字段的后面 unique key(字段的名字)
建表后
- alter table 表名 add unique(字段名);
- 例如:alter table customer add unique (email);
- 或者: alter table customer add unique key (email);
删除唯一约束
方式一:查找索引名字的方法(show index from 表名) (删除联合唯一键一样)
alter table 表名 drop index 索引的名字;
方式二:可以在添加联合唯一键的时候起个名字,删除的时候可以直接引用这个名字。


注意:
1.可以保证设置唯一键约束的值是在整张表中是唯一的;
2.设置唯一约束后 可以添加null值 且 null值没有唯一性校验;
3.添加唯一约束 也会自动创建索引;
4.删除索引就是删除唯一键约束;
5.可以设置联合唯一约束 那么当所有的字段值都一样 才不能添加;
6.一张表唯一约束可以设置多个
补充:
查看所有的约束信息:
select * from information_schema.`TABLE_CONSTRAINTS` where table_name = 'person';查看索引
show index from person;
十:非空约束(目的是保证字段值不为null)
建表时
在字段后直接添加 not null
建表后
alter table 表名 modify 列的定义 not null;
删除
alter table 表名 modify 列的定义;
十一: 自动增长约束
建表时
键列后 auto_increment;
建表后
alter table 表名 modify 列的定义 auto_increment;
删除
alter table 表名 modify 列的定义;(此时只能删除自动增长不能删除主键)
注意:
1.自动增长约束 用于数据自动递增;
2.自增约束 必须用到键列上 主键 唯一键 外键
3.设置自增约束后 自增列可以设置为null 值会从1开始递增
4.自增列 要整数类型
补充:
-- delete from 删除数据 从累积的原来的基础之上开始继续自动增长
-- truncate table 删除数据 从1开始添加(truncate DDL语言)
十二:外键约束(包证参照的完整性)
建表时:
在所有的字段后 (只有这一种方式,不能在一个字段后面)
例如:foreign key(本表字段) references 父表(键列)(标红的可以名字不一样)
建表后:
alter table 表名 add foreign key(本表要关联的字段) references 父表(键列);
删除:
alter table 表名 drop foreign key 外键的名字;
查询外键的名字
select * from information_schema.`TABLE_CONSTRAINTS` where table_name = "person";

注意:
1.保证参照的完整性
2.被参照的列(子表中的列)必须是键列(可以是主键或者唯一键) 父表中被关联的字段必须设置了键约束
3.一张表可以设置多个外键

重要知识点:
外键的级联策略:
casecade: 当父表字段被子表引用时父表字段删除 子表数据一同删除
父表字段修改 子表引用字段一同修改set null: 当父表字段被子表引用时 父表字段更新或者删除 子表对应字段会变为 null
no action 没有动作 和 restrict一样
restrict 严格的 当父表字段被子表引用时 那么父表字段不能删除 不能 修改
-- 建表后添加外键约束
alter table student add foreign key(cid) references clazz(cid) on update cascade on delete set null;
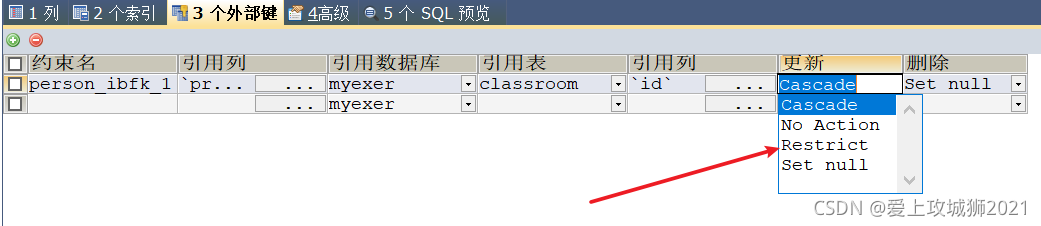
补充: 各种约束的设置
一. sql命令的方式进行设置
二.图形化界面设置
十三:字符串函数(mysql 下标从1开始 )
-- 拼接 select concat("你好","世界");
-- 按照指定的分隔符进行拼接 select concat_ws("-","你好","世界","Hello");
-- length() 返回的是字节数 select length("ABC");-- 3
select length("你好");-- 6
-- 返回的是字符数 select char_length("你好");
-- insert(str,pos,length,newStr) 将newStr插入到指定下标位置替换指定数量的字符
select insert("ABCDE",2,3,"你好"); -- A你好E
-- upper() 转为大写 lower() 转为小写
-- 在左边进行数据填充 select lpad("A",4,"EFG"); --EFGA
-- trim 去除两边的空格
-- 去除两端指定的内容******AB****** select trim(both "*" from "******AB******");
-- 去除左边指定的内容 select trim(leading '%' from "%%%%%%AB%%%%%%");
-- 去除右边指定的内容 select trim(trailing '%' from "%%%%%%AB%%%%%%");
-- 替换 指定的内容 select replace("ABCDEFAB",'AB',"你"); --你CDEF你
补充:
Mysql会在主键、唯一键、外键列上自动创建索引,其他列需要建立索引的话,需要手动创建。
其中主键删除,对应的索引也会删除
删除唯一键的方式是通过删除对应的索引来实现的
删除外键,外键列上的索引还在,如果需要删除,需要单独删除索引。
十四:数学函数
14.1 数学函数
-- 绝对值 select abs(1),abs(-1);
-- 向下取整floor()
-- 向上取整 ceil() select floor(3.6),floor(4.3),ceil(4.3),ceil(5.6);
-- 四舍五入 -- round(3.56) 只要整数部分对小数部分四舍五入
-- round(小数,整数) 保留整数位小数 对整数位后面的小数 进行四舍五入
select round(3.12345,2);
-- 保留指定位数的小数 不会进行 四舍五入 select truncate(3.56,1);
-- 保留0位小数 select truncate(3.56,0);
-- 开平方 select sqrt(16);
-- x^y select pow(3,3);
14.2 日期函数
-- 获取当前的年月日 ,时分秒 select curdate(),curtime();
-- sysdate()执行那一刹那的时间 select now(),sysdate(),sleep(5),now(),sysdate();
-- 获取年 月 select year(now()),month(now());
-- 获取月份的名字 select monthname(now()),monthname('2021-2-10');
-- dayofweek 周日是1 weekday 周一是 0
-- 返回周几的英文字母 select dayname(now());
-- 两个日期之间的差值 select datediff(date1,date2); date1 -date2
select datediff(now(),'2021-11-7'); -- 4
-- 改变日期 select date_add(now(),interval -1 year);
14.3:其他函数
-- 返回正在操作的数据库 select database();
-- 返回数据库的版本 select version();
-- 返回正在操作数据库的用户 select user();
-- 加密方式 select password(123456); select md5("窗前明月光");
14.4:流程函数
1> IF(条件判断,t ,f) value 真 t 假 f
类似于三目运算例如:
-- 如果薪资 >=15000 高工资 一般工资 select salary ,IF(salary > 15000 ,"高工资","一半工资") from t_employee;2> IFNULL(value1, value2)
如果 value1 不是null 返回 value1
如果 value1 是null 返回 value2select ename,salary,commission_pct , salary*12*(1+ifnull(commission_pct,0 )) '年薪' from t_employee;3> CASE WHEN 条件1 THEN result1
WHEN 条件2 THEN result2
.... [ELSE resultn] END判断薪资等级 >20000 A 15000 <= 20000 B 10000 <=15000 C <10000 D */ select * from t_employee; select ename , salary,case when salary>20000 then "A" when salary >=15000 then "B" when salary >=10000 then "C" else "D" end '薪资等级' from t_employee;4> CASE expr WHEN 常量值1 THEN 值1
WHEN 常量值2 THEN 值2
.... [ELSE 值n] END
select ename ,did , case did when 1 then '教学部' when 2 then '咨询部' when 3 then '运营部' when 4 then '财务部' else '没有此部门' end '部门名称' from t_employee;
14.4:多行分组函数
SQL执行顺序(重要) 12个

avg() 求平均数
sum() 求总和
max() 求最大值
min() 求最小值
count() 求数量
注意:
1. 把多条记录 汇总为一条结果
2. 会自动忽略null值
3. count(主键)>count(*)>count(3) (主键效率最高)
count(主键)>count(1)>count(*)
十五:查询 DQL
15.1 关联查询(去除笛卡尔积 找到符合要求的结果)
sql标准:
sql92
会将连接条件和筛选条件放到一起
sql99
将连接条件和筛选条件分开
15.2 关联查询的7中结果 (重要)

15.2 内连接(可以省略 inner)
sql99:
select 展示的字段
from A [inner] join B
on 连接条件
where 筛选条件;
sql92:
select 展示的字段
from A,B
where 连接条件 ,筛选条件;
15.3 外连接
左外连接 left join 展现左表所有的数据
右外连接 right join 展现右表所有的数据
全外连接 union 将两个结果集并到一起注意: 全外连接的时候 两张表 A B 表展示的字段 和顺序要一致
select e.`eid` ,e.`ename` , e.`did` ,e.`salary` , d.`did` ,d.`dname` ,d.`description`
from t_employee e
left join t_department d
on e.`did` = d.`did`
union
select e.`eid` ,e.`ename` , e.`did` ,e.`salary` , d.`did` ,d.`dname` ,d.`description`
from t_employee e
right join t_department d
on e.`did` = d.`did` 15.4 自连接
-- 获取 每一个员工的 员工编号 名字 薪水 上级编号 以及上级员工的 员工编号 名字 薪水 入职日期
-- 当前员工的上级编号 = 上级员工的员工编号
select e.`eid` , e.`ename` ,e.`mid` , m.`eid` , m.`ename` from t_employee e join t_employee m on e.`mid` = m.`eid`;

十六:select七大子句上
16.1 7个关键字
(1)from:从哪些表中筛选
(2)on:关联多表查询时,去除笛卡尔积
(3)where:从表中筛选的条件
(4)group by:分组依据
(5)having:在统计结果中再次筛选
(6)order by:排序
(7)limit:分页
注意:
distinct 字段1 字段2 去除字段1 2 的组合重复情况。
16.2:group by 进行分组 (难点)(select后面一定放分组字段)
group by 分组的条件:
在进行分组时 select 后面放分组字段 放其他字段 有结果 没意义
-- 统计 每一个部门的平均薪水 select e.`did` , AVG(e.`salary`) from t_employee e group by e.`did`;-- 统计 每一个部门的最高薪水 select e.`did` , max(e.`salary`) from t_employee e group by e.`did`-- 统计 每一个部门的男生 平均薪水 显示 平均薪资>30000 select e.`did` , AVG(e.`salary`) from t_employee e where e.`gender` = "男" group by e.`did` having AVG(e.`salary`) > 3000;- 对原始数据进行筛选使用where ,对分组后的数据再次筛选 使用having 子句;
- 如果分组完毕 就已经拿到了所有的分组结果 可以根据自己的实际需求进行数据展示,没展示的数据并不是没有拿到。
- 可以按照多个条件进行分组
-- 统计 每一个部门的男生 平均薪水 显示 平均薪资>30000
select e.did, avg(e.`salary`)
from t_employee e
where e.`gender`='男'
group by e.`did`
having avg(e.`salary`)>30000
-- 显示每一个部门的最高薪水 及其部门名称
select e.`did`,max(e.`salary`),d.`dname`
from t_employee e join t_department d
on e.`did` =d.`did`
group by e.`did`;
-- 进行多个条件分组
select did, job_id ,salary from t_employee;
select e.`did`,e.`job_id`,avg(salary)
from t_employee e
group by e.`did`,e.`job_id`;16.3:子查询
where:
如果子查询的结果数量>1 应该使用 all any 对结果进行修饰
all 是与子查询所有结果比较
any 是与子查询任意一个结果比较
from :
将子查询作为数据源
exists :(用的相对较少)
去除没有关联的数据
-- 薪资最高的人的信息
select *
from t_employee e
where e.`salary` = (
select MAX(e.`salary`)
from t_employee e
);
-- 薪资比 孙红雷 黄晓明 贾乃亮 工资高的人的信息
-- 两种情况 ①都高 用all ②有一个 any
select *
from t_employee e
where e.`salary` > all
(
select e.`salary`
from t_employee e
where e.`ename` in ("孙红雷","黄晓明","贾乃亮")
);
select *
from t_employee e
where e.`salary` > any
(
select e.`salary`
from t_employee e
where e.`ename` in ("孙红雷","黄晓明","贾乃亮")
)
-- 求每一个部门的平均薪水 部门的名称
select e.`did`,d.dname,AVG(e.`salary`)
from t_employee e ,t_department d
where e.`did` = d.did
group by e.`did`;
-- 子查询
select d.`did`,d.`dname`,emp.avgsal
from t_department d
join (
-- 查询每一个部门的平均工资 之后作为一个表 ,连接到部门表
select `did` ,AVG(e.`salary`) avgsal
from t_employee e
group by e.did
) emp
on d.`did` = emp.did;
-- 找 有员工的部门 exists
select d.`did`,d.`dname`
from t_department d
where exists(
select *
from t_employee e
where e.`did` = d.`did`;-- 员工表中的e.did = d.did 都说明该部门有员工
);16.4 order by 与 limit
order by :
asc : 从小到大
desc: 从大到小
如果安装多个字段排序: order by 字段1 , 字段2 ,字段3
limit: 分页
limit:(pageNo-1)*pageSize,pageSize;
pageNo:第几页
pageSize: 每页显示的数量
/*查询每 一个员工的 名字 薪水 工作编号 工作名称 部门编号 部门名称
按照 部门编号升序排序 当部门编号相同时 按照工作编号 降序排序
每页显示5条记录 显示第三页
limit (pageNo-1)*pageSize,pageSize;*/
select e.`ename`,e.`salary`,e.`job_id`,j.`job_name`,d.`did`,d.`dname`
from t_employee e join t_department d join t_job j
on e.`did` = d.`did` and e.`job_id` = j.`job_id`
order by e.did , j.job_id desc;十七:事务的理解
17.1 事务概念
事务处理(事务操作):保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback)到最初状态。
例如转账操作:A账户要转账给B账户,那么A账户上减少的钱数和B账户上增加的钱数必须一致,也就是说A账户的转出操作和B账户的转入操作要么全部执行,要么全不执行;如果其中一个操作出现异常而没有执行的话,就会导致账户A和账户B的转入转出金额不一致的情况,为而事实上这种情况是不允许发生的,所以为了防止这种情况的发生,需要使用事务处理。
17.2:事务的ACID属性
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
17.3:开启事务
set autocommit = false; 当前会话永久有效
start transaction; 只有一次有效
rollback 回滚
commit 提交
如果进行了一次回滚 或者 进行了一次提交 代表当次事务结束
事务只对 增 删除 改 有效 对 DDL无效














 7902
7902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









