









原文链接:https://arxiv.org/abs/2108.09661
开源代码:https://github.com/wangyuxin87/VisionLAN
摘要
在本文中,我们抛弃了占主导地位的复杂语言模型,重新思考了场景文本识别中的语言学习过程。不同于以往将视觉和语言信息放在两个独立的结构中考虑的方法,我们提出了一种视觉语言建模网络(VisionLAN),它将视觉和语言信息作为一个整体,直接赋予视觉模型语言能力。特别地,我们在训练阶段引入了基于字符的遮挡特征图的文本识别。这样的操作引导视觉模型在视觉线索被混淆(如遮挡、噪声等)时,不仅利用字符的视觉纹理,还利用视觉语境中的语言信息进行识别。由于语言信息与视觉特征一起获取,无需额外的语言模型,因此VisionLAN的速度显著提高了39%,并自适应地考虑语言信息来增强视觉特征,从而实现准确的识别。此外,提出了一个遮挡场景文本(OST)数据集来评估在缺失特征视觉线索的情况下的性能。几个基准测试的最新结果证明了我们的有效性。
1. 介绍
场景文本识别(scene text recognition, STR)是一项基础性的关键任务,旨在从自然图像中读取文本内容,引起了计算机视觉领域的极大兴趣[15,31,32,42,46]。一些早期的方法将文本图像作为输入,文本预测作为输出,将文本识别作为符号分类任务[31,19]。

图1所示。以往方法与我们方法的比较。左上:以前方法的体系结构。右上:当单词长度增加时,捕获语言信息的额外计算成本。下:提出的VisionLAN在训练阶段赋予视觉模型在视觉语境中主动捕捉语言信息的能力。在测试阶段,只使用视觉模型进行预测。
然而,对于视觉线索混乱的图像(如遮挡、噪声等)很难识别,这超出了视觉识别的范围。由于场景文本图像包含视觉纹理和语言信息两层内容,受到自然语言处理(Natural Language Processing, NLP)方法的启发[23,5],最近的STR工作将研究重点转向获取语言信息以辅助识别[47,46,28,45]。因此,视觉和语言模型的两步架构(图1左上)在最近的方法中很流行。具体来说,视觉模型只关注字符的视觉纹理,而没有考虑语言信息。然后,语言模型通过语言学习结构(RNN[32]、CNN[7]和Transformer[45])预测字符之间的关系。
然而,对于视觉线索混乱的图像(如遮挡、噪声等)很难识别,这超出了视觉识别的范围。由于场景文本图像包含视觉纹理和语言信息两层内容,受到自然语言处理(Natural Language Processing, NLP)方法的启发[23,5],最近的STR工作将研究重点转向获取语言信息以辅助识别[47,46,28,45]。因此,视觉和语言模型的两步架构(图1左上)在最近的方法中很流行。具体来说,视觉模型只关注字符的视觉纹理,而没有考虑语言信息。然后,语言模型通过语言学习结构(RNN[32]、CNN[7]和Transformer[45])预测字符之间的关系。
VisionLAN的流水线如图2所示。VisionLAN包括骨干网、掩码语言感知模块(mask Language-aware Module, MLM)和视觉推理模块(Visual Reasoning Module, VRM)三部分。在训练阶段,首先从骨干网络中提取视觉特征V。然后MLM以视觉特征V和字符索引P作为输入,通过弱监督互补学习,在相应位置自动生成字符掩码映射M askc。MLM的目的是通过在V中遮挡视觉信息来模拟缺失字符视觉线索的情况。为了在视觉纹理建模过程中考虑语言信息,我们提出了一种能够捕获视觉空间中远程依赖关系的VRM。VRM将被遮挡的特征映射Vm作为输入,并被引导进行词级预测。在测试阶段,我们去掉了MLM,只使用VRM进行识别。由于语言信息是与视觉特征一起获取的,不需要额外的语言模型,因此VisionLAN引入了零计算成本来捕获语言信息(图1右上),并且速度显著提高了39%(第4.4节)。与以前的方法相比,VisionLAN在遮挡和低质量图像上获得了更强的鲁棒性,并在几个基准测试中获得了新的最先进的结果。此外,提出了一个遮挡场景文本(OST)数据集来评估缺失字符视觉线索情况下的性能。
本文的主要贡献如下:1)提出了一种新的简单的场景文本识别体系结构。我们进一步可视化特征图,以说明VisionLAN如何主动使用语言信息来处理混淆的视觉线索(例如遮挡,噪声等)。2)我们提出了一种弱监督互补学习方法,用于在仅单词级注释的MLM中生成准确的逐字符掩码映射。3)提出了一种新的遮挡场景文本(OST)数据集来评估遮挡图像的识别性能。与以前的方法相比,VisionLAN在七个基准(不规则和常规)和OST上实现了最先进的性能,并且具有简洁的管道。
2. 相关工作
2.1 场景文本识别
场景文本识别(STR)一直是计算机视觉领域的一个长期研究课题[42,47,7]。随着深度学习成为最有前途的机器学习工具[35,40,41,8,17,20],过去几年STR研究取得了重大进展[28,24]。在本节中,我们根据是否使用语言规则将这些方法分为两类,即无语言方法和语言感知方法。无语言方法[42,48,31,19]将STR视为一种视觉分类任务,主要依靠视觉信息进行预测。CRNN[31]通过结合CNN和RNN提取序列视觉特征,然后使用连接时间分类(Connectionist Temporal classification, CTC)[9]解码器最大化所有路径的概率进行最终预测。Patel等[27]为图像自动生成自定义词汇,大大提高了文本读取系统的性能。Zhang等[48]将文本识别视为一种视觉匹配任务。他们计算输入图像的视觉特征与预先定义的字母表之间的相似性映射,以预测文本序列。Liao等[18]将文本识别视为逐像素分类任务。同样,Textscanner[36]进一步提出了一种顺序映射,以确保从字符到单词的更准确的转录。一般来说,无语言方法在识别过程中忽略了语言规则,通常无法识别视觉线索混乱(如模糊、遮挡等)的图像。
语言感知方法[16,4,47,43]试图利用语言规则来辅助识别过程。Lee等人[15]使用rnn自动学习单词字符串中的顺序动态,而无需手动定义n -gram。Aster[32]在识别前首先使用纠错模块,然后利用上一步预测到的字符,采用rnn对语言信息进行建模。然而,RNN中这种串行化和时效性的运算限制了计算效率和语义推理的性能[45]。因此,SRN[45]提出了一种基于变压器单元的全局语义推理模块[35],用于纯语言建模,以视觉模型的预测为输入,预测字符之间的关系,以细化识别结果。Fang等人[7]为视觉和语言建模设计了一个完全基于cnn的架构。虽然这些方法在场景文本识别任务上取得了很好的效果,但额外引入的语言模型将大大增加计算成本。此外,两步结构也难以全面考虑和有效融合独立的视觉和语言信息以实现准确识别[7,46]。不同于以往将视觉和语言信息放在两个独立的结构中考虑的方法,我们直接赋予视觉模型语言能力,并提出一个VisionLAN将视觉和语言信息作为一个整体来看待。因此,可以通过在视觉语境中捕捉语言信息来增强混淆的视觉线索。
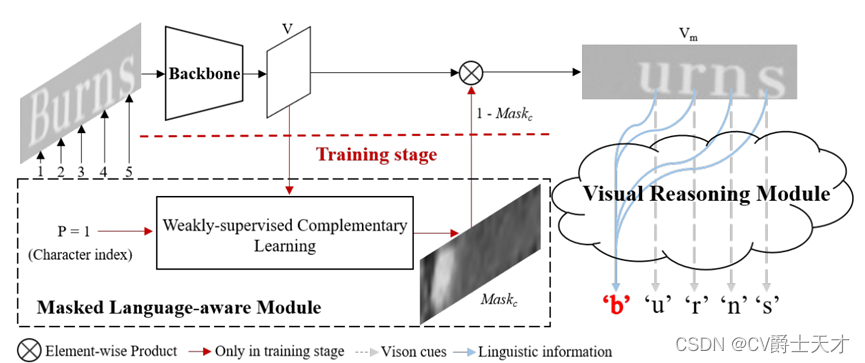 图2。VisionLAN的流程图。VisionLAN主要包括骨干网、掩码语言感知模块(mask Language-aware Module, MLM)和视觉推理模块(Visual Reasoning Module, VRM)三部分。MLM只在培训阶段使用。
图2。VisionLAN的流程图。VisionLAN主要包括骨干网、掩码语言感知模块(mask Language-aware Module, MLM)和视觉推理模块(Visual Reasoning Module, VRM)三部分。MLM只在培训阶段使用。
2.2. 掩蔽和预测
BERT[5]引入了一个完形填空任务来屏蔽输入句子的标记,该任务用于学习基于上下文的鲁棒双向表示。继[5]之后,一些作品使用了类似的概念来处理视觉和语言任务[34,1,22]。ViLBERT[22]使用两流模型来处理视觉和文本输入,并通过两个代理任务预训练他们的模型。Su等人[34]提出了一种适用于大多数视觉语言下游任务的通用结构,该结构将视觉和语言特征作为输入。由于STR数据集被弱标注为词级注释,因此很难在STR任务中直接实现这些屏蔽方法。不同于这些在令牌或图像补丁级别进行掩码的方法,本文提出了一种弱监督的掩码方法互补学习在特征级自动遮罩输入图像。因此,VisionLAN通过指导模型在缺失字符视觉线索的情况下进行单词级预测,从一个新的角度学习语言信息。
3.相关方法
VisionLAN是一个端到端可训练的框架,由三部分组成:骨干网、掩码语言感知模块(MLM)和视觉推理模块(VRM)。在本节中,我们首先详细介绍3.1节中提出的方法的流水线,然后分别在3.2节和3.3节中介绍MLM和VRM。
3.1 Pipeline
VisionLAN的流水线如图2所示。在训练阶段,给定一个输入图像,首先从骨干网络中提取二维特征V。然后,MLM以提取的特征V和字符索引P作为输入,通过弱监督互补学习生成位置感知的字符掩码映射Maskc。Maskc用于遮挡V中的逐字符视觉消息,以模拟缺少逐字符视觉语义的情况。之后,VRM将遮挡的特征映射Vm作为输入,在完全词级监督下进行预测。在测试阶段,我们去掉了MLM,只使用VRM进行预测。
3.2. 屏蔽语言感知模块(MLM模块)
为了遮挡字符视觉线索来指导语言学习,我们提出了一个掩码语言感知模块(MLM)来自动生成仅包含原始单词级注释的字符掩码映射。
如图3所示,MLM以视觉特征V和特征指数P作为输入。字符索引P 属于[1,Nw]表示被遮挡字符的索引,对于每个长度为Nw的输入单词图像,随机获取该字符的索引。
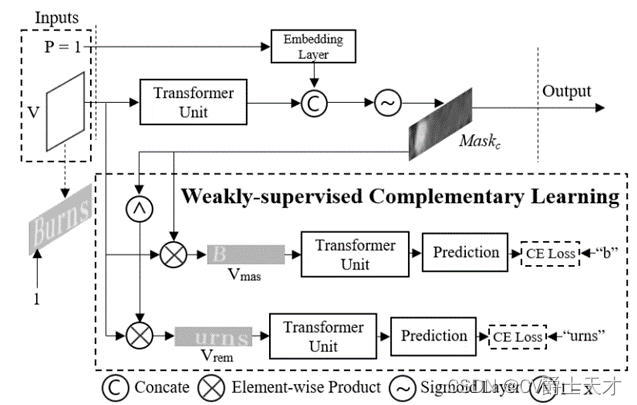
图3。MLM的架构。MLM以视觉特征V和字符索引P作为输入,自动生成字符掩码映射Maskc。CE损失是指交叉熵损失。
然后利用transformer单元[35]来提高特征表示能力。最后,结合字符索引信息,通过sigmoid层得到字符掩码映射M askc,用于生成图2中的遮挡特征映射Vm。
为了指导M askc的学习过程,在弱监督互补学习(WCL)的基础上设计了两个并行分支。WCL旨在引导Maskc覆盖更多被遮挡字符的区域,从而互补地使1−Maskc包含更多其他字符的区域。在第一个分支中,我们实现V和Maskc之间的逐元素乘积,以生成包含被遮挡字符的视觉语义的特征图Vmas(例如,图3中字符索引为1的单词“burns”中的字符“b”)。相反,第二分支中V和1−M askc之间的元素乘积用于生成包含其他字符的视觉语义的特征图Vrem(例如,图3中单词“burns”中的字符串“urns”)。通过这样做,互补学习过程引导M askc只覆盖相应位置的字符,而不与其他字符重叠(如图7所示)。我们在两个平行分支之间共享变换器单元和预测层的权重(等式1),用于特征表示增强和语义引导。Vin 2 Rhw×c是特征图,Att 2 Rhw×N是注意力图,其中c=512是通道数,N=25是最大时间步长,h和w是高度和宽度。Oc是字符顺序的位置编码[35]。W1、W2、W3是可训练的权重,t是时间步长。
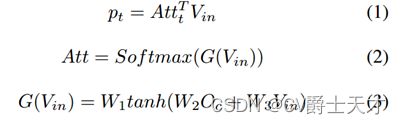
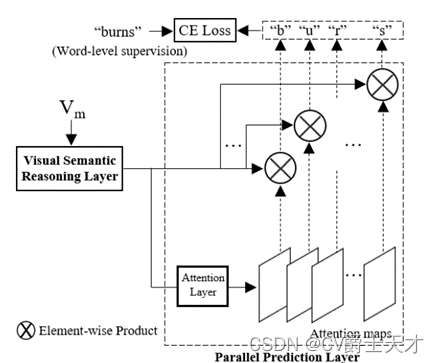
Figure 4. The architecture of VRM. CE loss is cross-entropy loss.
与BERT[5]相比,虽然两种方法都在一定时间步长内掩盖了信息,但本文提出的MLM掩盖了二维空间空间的视觉特征,而不是覆盖令牌级信息。此外,由于STR数据集是弱标记的,难以获得准确的逐字符像素级注释。因此,直接在STR任务中实现基于bert的方法[34,1,22]是不切实际的。在此基础上,MLM帮助模型从一个新的角度学习语言信息,这是现有掩蔽方法无法替代的。
使用原始的词级标注和随机生成的字符索引(详见第4节)自动获得WCL的监督。因此,MLM自动生成准确的字符掩码映射,而无需额外的标注,使实际应用成为可能。
3.3. 视觉推理模块(VRM)
与以往采用两步结构捕获视觉和语言信息的方法不同,我们提出了视觉推理模块(VRM),以统一的结构同时对两种信息进行建模。作为一种纯粹基于视觉的结构,VRM的目的是利用视觉环境中的字符信息,从被遮挡的特征中推断出词级预测。
VRM的细节如图4所示,它包括两部分:可视化语义推理(VSR)层和并行预测(PP)层。VSR层由N个变压器单元[35]组成,在最近的计算机视觉任务中被证明可以有效地建模长期依赖关系[2,24]。特别地,采用位置编码来感知像素的位置信息。与[45]使用变压器单元进行纯语言建模不同,本文提出的VRM使用变压器单元进行序列建模,不受单词长度的影响。然后,设计PP层来并行预测字符; 公式与方程1相同。

图5。VSR层生成的特征的可视化和相应的预测结果。顶部:输入图像。中间:没有传销的模型。下图:我们的VisionLAN。
为了实现语言建模过程yi =f(yN ,…, yi+1, yi−1, … y1),第I个字符yi的推理过程需要纯粹依赖于其他字符的信息。由于MLM在训练阶段准确地遮挡了字符信息,引导VSR层预测字符视觉特征之间的依赖关系,从而推断被遮挡字符的语义。因此,在单词级监督下,VSR层学习在视觉语境中主动建模语言信息以辅助识别。在测试阶段,VSR层能够在当前视觉语义混乱(如遮挡、噪声等)的情况下,自适应地考虑语言信息进行视觉特征增强。
我们将测试中由VSR层生成的特征映射可视化,以更好地理解学习到的语言信息如何提高识别性能。如图5所示,VSR层有效补充了单词“better”中被遮挡字符“r”的语义,并借助视觉语境中的语言信息,正确突出了单词“trans”中字符“t”的判别性视觉线索。由于没有MLM引导的主动语言学习,VRM错误地将输入图像预测为“bettep”和“rrans”。
3.4.训练目标
本文方法的最终目标函数如式4所示。Lrec为VRM中的损失,Lmas和Lrem分别为MLM中预测掩码字符和其他字符的损失。λ1和λ2用来平衡损耗。特别地,我们设λ1 = λ2 = 0:5,并对Lrec、Lmas和Lrem使用公式5中的交叉熵损失。Pt和gt分别表示预测值和真实值。
我们在实验中将N设为25。
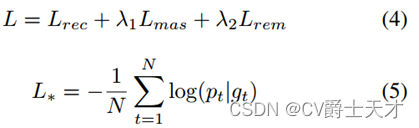
4.实验
4.1 数据集
为了公平比较,我们按照[45]的设置进行实验。训练集是 SynthText (ST) [10] 和 SynthText90K (90K) [12]。在包含IIIT 5K-Words (IIIT5K)[25]、ICDAR2013 (IC13)[14]、ICDAR2015 (IC15)[13]、Street View Text (SVT)[37]、Street View Text- perspective (SVTP)[29]和CUTE80 (CT)[30]的6个基准测试上对性能进行了评估。以上6个数据集的详细内容可参见前人的著作[45,28]。
此外,我们提供了一个新的遮挡场景文本(OST)数据集来反映识别缺少视觉线索的情况的能力。该数据集来自6个基准测试(IC13, IC15, IIIT5K, SVT, SVTP和CT),包含4832张图像。该数据集中的图像被手动以弱或重的程度遮挡(如图6所示)。弱和重的程度意味着我们使用一条或两条线遮挡字符。对于每张图像,我们随机选择一个度只覆盖一个字符。补充材料中显示了更多的OST示例。
4.2 实验细节
我们使用ResNet45[32,38,28]作为我们的主干。特别是,我们在阶段2,3,4中设置步幅为2,并默认初始化权重。根据最近的作品[45,28],我们将图像大小设置为256 × 64(与我们实验中128 × 32的大小没有明显差异)。数据增强包括随机旋转,颜色抖动和透视失真。我们在4个批处理大小为384的NVIDIA V100 gpu上进行了实验。使用学习速率为1e-4的Adam优化器对网络进行端到端训练。该识别包含37个字符,包括a-z、0-9和一个序列结束符号。
接下来[45],我们将训练过程分为2个步骤:无语言(LF)步骤和语言感知(LA)步骤。值得一提的是,为了公平比较,我们控制了培训课程的总数,以与现有方法保持一致。1)在LF步骤中,我们将MLM和VRM之间的连接分离(图2中的V = Vm),以保证两个模块的学习过程更加稳定。此步骤中的VRM不会获得语言能力,仅使用视觉纹理进行预测。2)在LA步骤中,利用MLM生成的M askc遮挡特征映射V,指导VRM学习语言规则。具体来说,我们控制了批次中遮挡数的比例,目的是在训练阶段平衡视觉信息丰富或薄弱的情况。
由于所有的训练图像都有单词级标注,我们根据单词的长度随机生成字符索引,并使用该索引和原始单词级标注生成MLM的标签(例如,当index为4,单词为“house”时,标签分别为“s”和“houe”)标签生成过程是自动的,无需人工干预,这使得在其他数据集上调整我们的模型变得容易。
4.3 消融实验
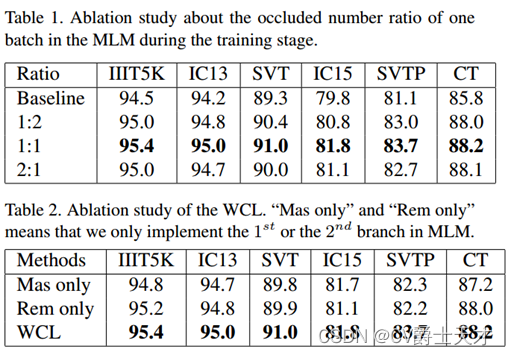
我们将在本节中说明所建议模块的有效性。具体来说,基线包含表1& 2& 3中两个transformer单元的VRM。
MLM的有效性。所提出的MLM旨在指导VRM中的语言学习过程。我们进行了几个实验来评估其在Tab中的有效性。
1. 基线模型在没有传销的情况下实现。我们改变批次中遮挡数的比例来研究其对识别性能的影响(例如当批次大小为128时,比例= 1:3意味着我们在1批次中仅对32个样本使用M请求c遮挡V,其余96个样本的特征图保持不变)。如Tab所示。1、当比例在1:2 ~ 2:1范围内时,所提出的MLM显著提高了基线模型的性能。对于含有大量混淆视觉线索(模糊、遮挡、噪声等)图像的不规则数据集(IC15、SVTP、CT),本文提出的MLM以1:1的比例将基线模型的准确率提高了至少2%,进一步证明了主动语言学习过程有效地帮助视觉模型处理混淆视觉线索。对于常规数据集,改进也相当可观(IIIT5K、IC13和SVT数据集分别为0.9%、0.8%和1.7%)。当比例提高到2:1时,性能略有下降。我们推断,在训练过程中,比值的较大值将打破视觉线索丰富和微弱的案例之间的平衡。因此在其余的实验中,我们将ratio的值设置为1:1。
WCL的有效性。为了证明所提出的弱监督互补学习在MLM中的有效性,我们进行了几个仅使用第一个分支(闭塞字符)或第二个分支(剩余字符串)实施的实验。如表2所示,在训练阶段,使用互补学习过程实现的MLM比只指导闭塞字符或剩余字符串语义的方法获得了更好的效果。
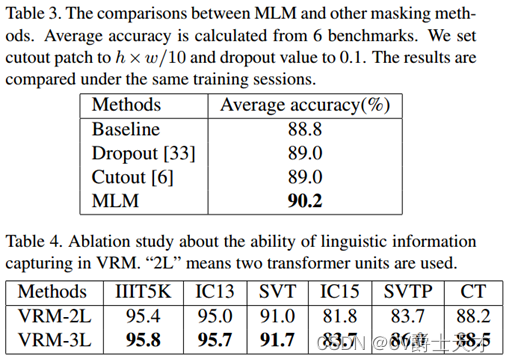
与其它掩蔽方法相比。我们将MLM与[6,33]进行比较,以评估我们在语言建模方面的有效性。为了公平比较,所有模块都只在V上工作。如表3所示,提出的MLM显著提高了识别结果(1.4% vs 0.2%)。如3.3节所述,第i个字符的推理过程需要完全依赖于其他字符的信息,而不包含当前的字符信息。因此,随机屏蔽逐像素特征[6,33]不具有语言学习能力。得益于精心设计的体系结构和巧妙的弱监督学习,MLM能够准确定位具有特征的视觉线索,从而能够指导VRM中的语言学习过程。
VRM的有效性。为了研究识别性能与语言信息捕获能力之间的关系,我们比较了在VSR层中使用不同数量的变压器单元实现的模型的结果。如表4所示,采用三个变压器单元实现的VRM进一步提高了性能,具有更强的语言能力。
4.4 与先进算法的对比
在表5的6个基准测试中,我们将我们的方法与以前最先进的方法进行了比较。我们根据是否使用语言信息简单地将方法分为无语言方法和语言感知方法。感知语言的方法通常比无语言的方法执行得更好。得益于自适应地考虑语言信息以增强特征,与无语言和语言感知方法相比,所提出的VisionLAN在6个公共数据集上实现了最先进的性能。具体而言,对于常规数据集,所提出的VisionLAN在IIIT5K、IC13和SVT数据集上分别获得1%、0.2%和0.2%的改进。对于不规则数据集,IC15、SVTP和CT分别增加1%、0.9%和0.7%。
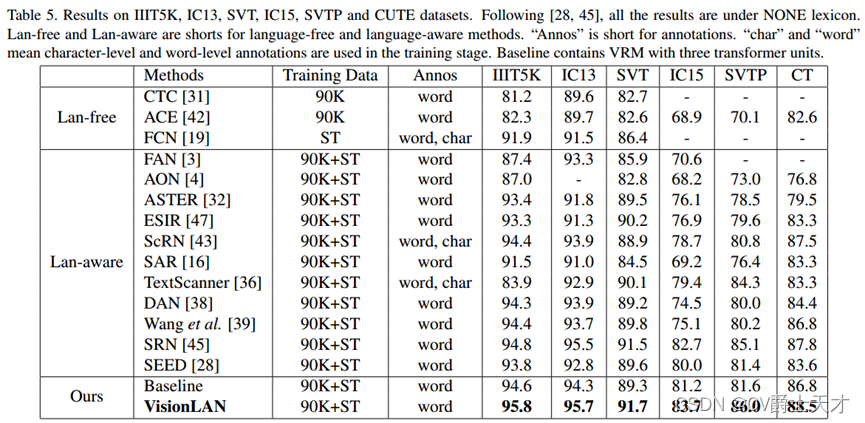 由于VisionLAN自适应地考虑了二维视觉空间中的视觉和语言信息,因此我们的方法对扭曲图像的敏感性较低。因此,本文方法在不规则数据集上的识别效果优于ASTER[32]和ESIR[47],后者在识别前采用校正过程。如表5所示,在IC15、SVTP和CT数据集上,[32]的增幅分别为7.6%、7.5%和9%,[47]的增幅分别为6.8%、6.4%和5.2%。
由于VisionLAN自适应地考虑了二维视觉空间中的视觉和语言信息,因此我们的方法对扭曲图像的敏感性较低。因此,本文方法在不规则数据集上的识别效果优于ASTER[32]和ESIR[47],后者在识别前采用校正过程。如表5所示,在IC15、SVTP和CT数据集上,[32]的增幅分别为7.6%、7.5%和9%,[47]的增幅分别为6.8%、6.4%和5.2%。

我们进一步比较了现有方法与我们的方法在识别速度和捕获语言信息的额外引入参数(eip)方面的差异,见表6。在接近速度和参数方面,我们在[45]的GSRM中实现了一个变压器单元(与第4.5节相同)。由于语言信息是与视觉特征一起获取的,不需要额外的语言模型,因此在不引入额外参数(0M vs 12.6M和3M)的情况下,所提出的VisionLAN显著提高了至少39%的速度(11.5ms vs 19ms和43.2ms)。此外,由于VisionLAN直接考虑视觉空间中的语言信息,因此其捕获语言信息的效率不会受到单词长度的影响。
4.5. OST数据集上的语言能力
为了详细评估VisionLAN的语言能力,我们将我们的方法与最近最流行的语言模型(RNN[32]和Transformer[45])在OST数据集上进行比较,以评估它们在缺少字符视觉线索的情况下的性能。具体地说,我们按照他们论文中的实现细节将这些语言模型连接到VRM。如表7所示,虽然[32]和[45]捕获的语言信息可以辅助视觉模型的预测,但本文提出的VisionLAN将视觉和语言信息视为一个整体,明显优于这些方法。通过自适应地将这两个信息聚合在一个统一的结构中,而不是单独考虑它们,VisionLAN平均提高了7.3%的基线模型。
4.6. 中文长数据集的泛化能力
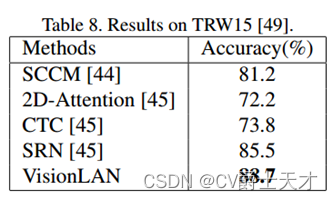
我们在非拉丁长文本(TRW15[49])上对VisionLAN进行了评估,以证明其泛化能力。这个数据集包含2997张裁剪过的图像,我们将最大长度N设置为50。我们一依据[45]的步骤训练VisionLAN。如表8所示,与无语言(CTC)和感知语言(2D Attention)方法相比,VisionLAN至少比这些方法高14.9%。得益于将视觉和语言信息视为一个联盟,所提出的VisionLAN实现了一个新的最先进的结果,并显著优于SRN[45]3.2%。在其他数据集(如MLT[26]等)上的更多实验可在补充中获得。
4.7 定性分析
按字符定位的MLM。为了定性分析MLM的有效性,我们在图7中可视化了生成的M askc的一些示例。生成的M askc在字符索引P的引导下有效地将字符视觉线索定位在相应的位置。此外,MLM能够处理失真的图像(例如弯曲的单词图像“nothing”)和重复字符的定位(例如单词“confabbing”中P=6的字符“b”)。补充部分提供了对字符本地化性能的定量评估VisionLAN的有效性。我们收集了一些识别结果来说明所学习的语言信息如何帮助视觉模型提高性能。如图8(a)所示,VisionLAN可以处理具有混淆字符的情况。例如,由于字符“e”与单词“before”的图像中的字符“f”具有相似的视觉线索,因此没有MLM的VisionLAN错误地给出了预测“f”,而VisionLAN则借助语言信息正确地推断出了字符“e)。对于图8(b)中的样本,VisionLAN还可以使用语言规则来消除背景干扰(包括遮挡、照明、背景纹理等)。此外,图8(c)中模糊字符的准确识别也证明了我们方法的有效性。和更多的Maskc可视化。
5. 总结
作为第一个赋予视觉模型语言能力的工作,本文提出了一种简洁有效的场景文本识别体系结构。VisionLAN成功地实现了从两步识别到一步识别的转换(从二步到一步),在不需要额外的语言模型的情况下,自适应地将视觉和语言信息考虑在一个统一的结构中。与以前的芈姓相比,VisionLAN在保持高效的同时展现出更强的语言能力。此外,还提出了一个新的遮挡场景文本数据集来评估在缺少特征视觉线索的情况下的性能。在七个基准测试和所提出的OST数据集上进行的大量实验证明了我们方法的有效性和效率。我们认为所提出的VisionLAN是朝着更强大和准确的场景文本识别迈出的基本一步,我们将在未来进一步探索其潜力。


Acknowledgments
这项工作得到了国家自然科学基金(62121002、62022076、U19362110)、中央高校基本科研业务费WK3480000011、中国博士后科学基金(2021M693092)和京东人工智能研究的资助。我们也感谢中科大信息科学技术研究所MCC实验室对GPU集群的支持。
参考资料
[1] Chris Alberti, Jeffrey Ling, Michael Collins, and David Reitter. Fusion of detected objects in text for visual question
answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th
International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2131–2140, 2019.
[2] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas
Usunier, Alexander Kirillov, and Sergey Zagoruyko. Endto-end object detection with transformers. arXiv preprint
arXiv:2005.12872, 2020.
[3] Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang
Pu, and Shuigeng Zhou. Focusing attention: Towards accurate text recognition in natural images. In Proceedings of
the IEEE international conference on computer vision, pages
5076–5084, 2017.
[4] Zhanzhan Cheng, Yangliu Xu, Fan Bai, Yi Niu, Shiliang
Pu, and Shuigeng Zhou. Aon: Towards arbitrarily-oriented
text recognition. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages 5571–
5579, 2018.
[5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina
Toutanova. Bert: Pre-training of deep bidirectional
transformers for language understanding. arXiv preprint
arXiv:1810.04805, 2018.
[6] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv
preprint arXiv:1708.04552, 2017.
[7] Shancheng Fang, Hongtao Xie, Zheng-Jun Zha, Nannan Sun,
Jianlong Tan, and Yongdong Zhang. Attention and language
ensemble for scene text recognition with convolutional sequence modeling. In Proceedings of the 26th ACM international conference on Multimedia, pages 248–256, 2018.
[8] Jiannan Ge, Hongtao Xie, Shaobo Min, and Yongdong
Zhang. Semantic-guided reinforced region embedding for
generalized zero-shot learning. In Proceedings of the AAAI
Conference on Artificial Intelligence, volume 35, pages
1406–1414, 2021.
[9] Alex Graves, Santiago Fernandez, Faustino Gomez, and ´
Jurgen Schmidhuber. Connectionist temporal classification: ¨
labelling unsegmented sequence data with recurrent neural
networks. In Proceedings of the 23rd international conference on Machine learning, pages 369–376, 2006.
[10] Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman.
Synthetic data for text localisation in natural images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2315–2324, 2016.
[11] Catherine L Harris. Language and cognition. Encyclopedia
of cognitive science, pages 1–6, 2006.
[12] Max Jaderberg, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Synthetic data and artificial neural networks for natural scene text recognition. NIPS, 2014.
[13] Dimosthenis Karatzas, Lluis Gomez-Bigorda, Anguelos
Nicolaou, Suman Ghosh, Andrew Bagdanov, Masakazu Iwamura, Jiri Matas, Lukas Neumann, Vijay Ramaseshan Chandrasekhar, Shijian Lu, et al. Icdar 2015 competition on robust
reading. In 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pages 1156–1160.
IEEE, 2015.
[14] Dimosthenis Karatzas, Faisal Shafait, Seiichi Uchida,
Masakazu Iwamura, Lluis Gomez i Bigorda, Sergi Robles
Mestre, Joan Mas, David Fernandez Mota, Jon Almazan Almazan, and Lluis Pere De Las Heras. Icdar 2013 robust
reading competition. In 2013 12th International Conference
on Document Analysis and Recognition, pages 1484–1493.
IEEE, 2013.
[15] Chen-Yu Lee and Simon Osindero. Recursive recurrent nets
with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 2231–2239, 2016.
[16] Hui Li, Peng Wang, Chunhua Shen, and Guyu Zhang. Show,
attend and read: A simple and strong baseline for irregular
text recognition. In Proceedings of the AAAI Conference on
Artificial Intelligence, volume 33, pages 8610–8617, 2019.
[17] Jiaming Li, Hongtao Xie, Jiahong Li, Zhongyuan Wang, and
Yongdong Zhang. Frequency-aware discriminative feature
learning supervised by single-center loss for face forgery
detection. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition, pages 6458–
6467, 2021.
[18] Minghui Liao, Pengyuan Lyu, Minghang He, Cong Yao,
Wenhao Wu, and Xiang Bai. Mask textspotter: An end-toend trainable neural network for spotting text with arbitrary
shapes. IEEE transactions on pattern analysis and machine
intelligence, 2019.
[19] Minghui Liao, Jian Zhang, Zhaoyi Wan, Fengming Xie, Jiajun Liang, Pengyuan Lyu, Cong Yao, and Xiang Bai. Scene
text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence,
volume 33, pages 8714–8721, 2019.
[20] Fanchao Lin, Hongtao Xie, Yan Li, and Yongdong Zhang.
Query-memory re-aggregation for weakly-supervised video
object segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 2038–2046,
2021.
[21] John L Locke. Why do infants begin to talk? language
as an unintended consequence. Journal of child language,
23(2):251–268, 1996.
[22] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations
for vision-and-language tasks. In Advances in Neural Information Processing Systems, pages 13–23, 2019.
[23] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on
Empirical Methods in Natural Language Processing, pages
1412–1421, 2015.
[24] Pengyuan Lyu, Zhicheng Yang, Xinhang Leng, Xiaojun Wu,
Ruiyu Li, and Xiaoyong Shen. 2d attentional irregular scene
text recognizer. arXiv preprint arXiv:1906.05708, 2019.
[25] Anand Mishra, Karteek Alahari, and CV Jawahar. Scene text
recognition using higher order language priors. In BMVC,
2012.
[26] Nibal Nayef, Yash Patel, Michal Busta, Pinaki Nath Chowdhury, Dimosthenis Karatzas, Wafa Khlif, Jiri Matas, Umapada Pal, Jean-Christophe Burie, Cheng-lin Liu, et al. Icdar2019 robust reading challenge on multi-lingual scene text
detection and recognition—rrc-mlt-2019. In 2019 International Conference on Document Analysis and Recognition
(ICDAR), pages 1582–1587. IEEE, 2019.
[27] Yash Patel, Lluis Gomez, Marc¸al Rusinol, and Dimosthenis
Karatzas. Dynamic lexicon generation for natural scene images. In European Conference on Computer Vision, pages
395–410. Springer, 2016.
[28] Zhi Qiao, Yu Zhou, Dongbao Yang, Yucan Zhou, and Weiping Wang. Seed: Semantics enhanced encoder-decoder
framework for scene text recognition. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pages 13528–13537, 2020.
[29] Trung Quy Phan, Palaiahnakote Shivakumara, Shangxuan
Tian, and Chew Lim Tan. Recognizing text with perspective
distortion in natural scenes. In Proceedings of the IEEE International Conference on Computer Vision, pages 569–576,
2013.
[30] Anhar Risnumawan, Palaiahankote Shivakumara, Chee Seng
Chan, and Chew Lim Tan. A robust arbitrary text detection
system for natural scene images. Expert Systems with Applications, 41(18):8027–8048, 2014.
[31] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end
trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE
transactions on pattern analysis and machine intelligence,
39(11):2298–2304, 2016.
[32] Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan
Lyu, Cong Yao, and Xiang Bai. Aster: An attentional scene
text recognizer with flexible rectification. IEEE transactions
on pattern analysis and machine intelligence, 41(9):2035–
2048, 2018.
[33] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya
Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way
to prevent neural networks from overfitting. The journal of
machine learning research, 15(1):1929–1958, 2014.
[34] Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu
Wei, and Jifeng Dai. Vl-bert: Pre-training of generic visuallinguistic representations. In International Conference on
Learning Representations, 2019.
[35] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia
Polosukhin. Attention is all you need. In Advances in neural
information processing systems, pages 5998–6008, 2017.
[36] Zhaoyi Wan, Mingling He, Haoran Chen, Xiang Bai,
and Cong Yao. Textscanner: Reading characters in order for robust scene text recognition. arXiv preprint
arXiv:1912.12422, 2019.
[37] Kai Wang, Boris Babenko, and Serge Belongie. End-to-end
scene text recognition. In 2011 International Conference on
Computer Vision, pages 1457–1464. IEEE, 2011.
[38] Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, Canjie Luo, Xiaoxue Chen, Yaqiang Wu, Qianying Wang, and Mingxiang
Cai. Decoupled attention network for text recognition. In
AAAI, pages 12216–12224, 2020.
[39] Yizhi Wang and Zhouhui Lian. Exploring font-independent
features for scene text recognition. ECCV, 2020.
[40] Yuxin Wang, Hongtao Xie, Zilong Fu, and Yongdong Zhang.
Dsrn: A deep scale relationship network for scene text detection. In IJCAI, pages 947–953, 2019.
[41] Yuxin Wang, Hongtao Xie, Zheng-Jun Zha, Mengting Xing,
Zilong Fu, and Yongdong Zhang. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11753–11762,
2020.
[42] Zecheng Xie, Yaoxiong Huang, Yuanzhi Zhu, Lianwen Jin,
Yuliang Liu, and Lele Xie. Aggregation cross-entropy for sequence recognition. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages 6538–
6547, 2019.
[43] Mingkun Yang, Yushuo Guan, Minghui Liao, Xin He,
Kaigui Bian, Song Bai, Cong Yao, and Xiang Bai.
Symmetry-constrained rectification network for scene text
recognition. In Proceedings of the IEEE International Conference on Computer Vision, pages 9147–9156, 2019.
[44] Fei Yin, Yi-Chao Wu, Xu-Yao Zhang, and Cheng-Lin Liu.
Scene text recognition with sliding convolutional character
models. arXiv preprint arXiv:1709.01727, 2017.
[45] Deli Yu, Xuan Li, Chengquan Zhang, Tao Liu, Junyu Han,
Jingtuo Liu, and Errui Ding. Towards accurate scene text
recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 12113–12122, 2020.
[46] Xiaoyu Yue, Zhanghui Kuang, Chenhao Lin, Hongbin Sun,
and Wayne Zhang. Robustscanner: Dynamically enhancing
positional clues for robust text recognition. eccv, 2020.
[47] Fangneng Zhan and Shijian Lu. Esir: End-to-end scene text
recognition via iterative image rectification. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 2059–2068, 2019.
[48] Chuhan Zhang, Ankush Gupta, and Andrew Zisserman.
Adaptive text recognition through visual matching. ECCV,
2020.
[49] Xinyu Zhou, Shuchang Zhou, Cong Yao, Zhimin Cao, and
Qi Yin. Icdar 2015 text reading in the wild competition.
arXiv preprint arXiv:1506.03184, 2015.
















 6549
6549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









